-
遥感之特征选择-禁忌搜索算法
各类智能优化算法其主要区别在于算法的运行规则不同,比如常用的遗传算法,其规则就是变异,交叉和选择等,各种不同的变体大多是在框架内的实现细节不同,而本文中的禁忌算法也是如此,其算法框架如下进行介绍。
智能优化算法和其他算法的最大不同在于,其没有太高深的数学理论和公式,主要是基于一种设定规则运行,其规则的设置背后有优美的哲学味道,所以它能有效解决一些问题,而同时不少人对比表示怀疑的态度,只有当真正的跑一遍代码,看看效果,才能对背后的思想有所领悟。
一言以蔽之,智能优化算法,是简洁,优美和有效的。禁忌搜索算法(Tabu Search,TS)是一种基于局部搜索的启发式算法,它通过记录搜索历史和禁止重复访问已访问过的局部最优解,来跳出局部最优,从而找到全局最优解。它模仿了人类行为中的“记忆”和“遗忘”机制,是一种简单而有效的全局优化方法。
禁忌搜索算法的原理
禁忌搜索算法的核心思想是“禁止重复”和“记忆”。它通过以下方式实现:
禁忌表:记录最近访问过的局部最优解或其状态,以及相应的禁忌长度。
搜索方向:在当前解的邻域中搜索候选解,并根据评价函数选择最好的解。
禁忌更新:将当前解或其状态添加到禁忌表中,并设置禁忌长度。
禁忌解除:当候选解被禁忌时,根据特赦规则决定是否允许访问该解。
搜索终止:达到最大迭代次数或找到全局最优解时,算法终止。
禁忌搜索算法的步骤
初始化:设置初始解,并计算其目标函数值。
搜索:在当前解的邻域中搜索候选解,并根据评价函数选择最好的解。
更新禁忌表:将当前解或其状态添加到禁忌表中,并设置禁忌长度。
禁忌解除:如果候选解被禁忌,则根据特赦规则决定是否允许访问该解。
搜索终止:达到最大迭代次数或找到全局最优解时,算法终止。
其算法流程图如下所示;
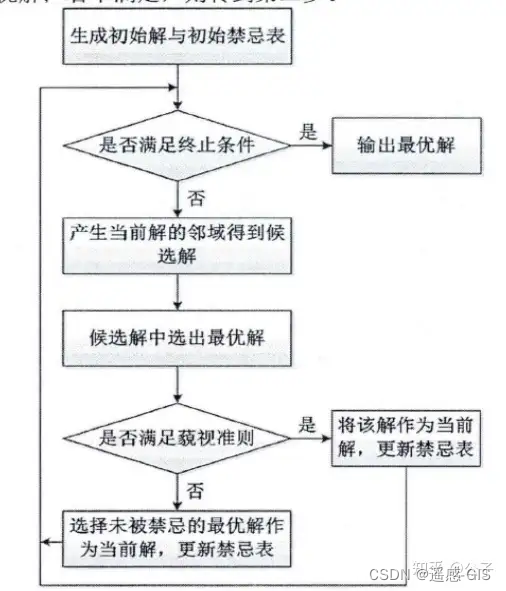
禁忌搜索算法的优缺点
优点:
- 跳出局部最优:通过禁忌表和特赦规则,能够有效跳出局部最优,寻找全局最优解。
- 全局搜索能力:具有全局搜索能力,能够搜索整个解空间。
- 易于实现:算法结构简单,易于实现。
- 参数选择灵活:禁忌表大小、禁忌长度、特赦规则等参数可以根据问题进行调整。
缺点: - 计算复杂度:禁忌表需要存储搜索历史,可能会增加计算复杂度。
- 参数选择困难:参数选择对算法性能影响较大,需要根据问题进行调整。
- 无法保证找到全局最优解:虽然能够有效跳出局部最优,但无法保证找到全局最优解。
代码
在遥感高光谱领域中会经常遇到波段选择的问题,基于此,利用禁忌搜索算法完成特征选择的案例,代码可以直接运行。
代码中对于上述提到的步骤的每个环节只是用简单的方式进行实现,比如初始化这步,在实际中通常对高光谱波段之间的相关性进行研究,划分不同的块,在每个块中选择一些波段作为初始化的解,以及对于候选解是如何选择的,是否需要进一步根据经验设定规则等,在实际中需要在此代码基础上进一步完善即可。import numpy as np import random class TabuSearchFeatureSelection: ''' 代码说明: 1. `TabuSearchFeatureSelection` 类定义了禁忌搜索算法,包括初始化、适应度函数、获取邻居、更新禁忌表、选择最佳邻居和选择特征等方法。 2. `initialize_population` 方法初始化当前特征集为所有特征。 3. `get_neighbors` 方法获取当前特征的邻居,包括删除一个特征和添加一个特征两种情况。 4. `update_tabu_list` 方法更新禁忌表,将特征集添加到禁忌表。 5. `select_best_neighbor` 方法从邻居中选择最佳特征集,优先选择不在禁忌表中的特征集,并选择适应度值最高的特征集。 6. `select_features` 方法进行特征选择,循环迭代更新当前特征集,直到没有更好的邻居或达到最大迭代次数。 7. `best_features` 和 `best_score` 分别存储最佳特征集和最佳得分。 ''' def __init__(self, n_iterations, tabu_size, feature_set, data, labels, model): """ 禁忌搜索算法初始化 :param n_iterations: 迭代次数 :param tabu_size: 禁忌表大小 :param feature_set: 特征集 :param data: 数据集 :param labels: 标签 :param model: 机器学习模型 """ self.n_iterations = n_iterations self.tabu_size = tabu_size self.feature_set = feature_set self.data = data self.labels = labels self.model = model self.best_score = float('-inf') self.best_features = None self.tabu_list = [] def fitness(self, features): """ 适应度函数,计算模型在当前特征集上的性能 :param features: 当前特征集 :return: 适应度值 """ X_train = self.data[:, features] clf = self.model.fit(X_train, self.labels) score = clf.score(X_train, self.labels) return score def get_neighbors(self, features): """ 获取当前特征的邻居 :param features: 当前特征集 :return: 邻居特征集列表 """ neighbors = [] for i in range(len(self.feature_set)): if i in features: new_features = np.array(features) new_features = np.delete(new_features, np.where(new_features == i)[0][0]) neighbors.append(new_features) else: new_features = np.array(features) new_features = np.append(new_features, i) neighbors.append(new_features) return neighbors def update_tabu_list(self, features): """ 更新禁忌表 """ # 将特征集添加到禁忌表 if len(self.tabu_list) >= self.tabu_size: self.tabu_list.pop(0) self.tabu_list.append(tuple(features)) def select_best_neighbor(self, neighbors): """ 从邻居中选择最佳特征集 :param neighbors: 邻居特征集列表 :return: 最佳特征集 """ best_score = float('-inf') best_features = None for neighbor in neighbors: if tuple(neighbor) in self.tabu_list: continue score = self.fitness(neighbor) if score > best_score: best_score = score best_features = neighbor return best_features def select_features(self): """ 选择特征 """ # 初始化当前特征集 current_features = np.arange(self.data.shape[1]) for _ in range(self.n_iterations): # 获取邻居 neighbors = self.get_neighbors(current_features) # 选择最佳邻居 best_neighbor = self.select_best_neighbor(neighbors) # 如果没有更好的邻居,则终止搜索 if best_neighbor is None: break # 更新当前特征集 current_features = best_neighbor # 更新禁忌表 self.update_tabu_list(current_features) # 更新最佳解 if self.fitness(current_features) > self.best_score: self.best_score = self.fitness(current_features) self.best_features = current_features return self.best_features, self.best_score # 示例用法 from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression # 加载数据集 data = load_iris().data labels = load_iris().target # 初始化模型 model = LogisticRegression(solver='newton-cg') # 初始化禁忌搜索算法 tabu_search = TabuSearchFeatureSelection(n_iterations=2, tabu_size=1, feature_set=np.arange(data.shape[1]), data=data, labels=labels, model=model) # 选择特征 best_features, best_score = tabu_search.select_features() print("最佳特征:", best_features) print("最佳得分:", best_score)总结
此类算法,了解其规则即可,在规则之内可以扩展展开。
欢迎关注专栏:智能优化算法专栏
欢迎点赞,收藏,关注,支持小生,打造一个好的遥感领域知识分享专栏。
同时欢迎私信咨询讨论学习,咨询讨论的方向不限于:地物分类/语义分割(如水体,云,建筑物,耕地,冬小麦等各种地物类型的提取),变化检测,夜光遥感数据处理,目标检测,图像处理(几何矫正,辐射矫正(大气校正),图像去噪等),遥感时空融合,定量遥感(土壤盐渍化/水质参数反演/气溶胶反演/森林参数(生物量,植被覆盖度,植被生产力等)/地表温度/地表反射率等反演)以及高光谱数据处理等领域以及深度学习,机器学习等技术算法讨论,以及相关实验指导/论文指导等多方面。 -
相关阅读:
[HNCTF 2022 Week1]——Web方向 详细Writeup
如何为java项目开启Spring Boot模式呢?
如何快速将钉钉员工信息同步到飞书
【编程题】【Scratch四级】2021.03 绳子算法
力扣二分查找:第一个错误的版本
Linux防火墙和firewall-cmd命令应用
java -非空判断
【git】一些容易混淆的操作
Java通过反射模拟冰蝎免杀功能
Linux中搭建DNS 域名解析服务器(详细版)
- 原文地址:https://blog.csdn.net/qq_36904533/article/details/139393935