-
Pipeline管道
一、介绍
pipelines直译为管道,类似于流水线的意思,可以将数据预处理和建模流程封装起来。在数据处理过程中,很多步骤都是重复或者类似的,比如数据处理,特征选择,标准化,分类等,pipeline就可以实现以下几点好处
- 1、简化代码:直接将步骤封装成完整的工作流,避免代码重复
- 2、更少出bug,流程规范话,避免在建模和部署过程中漏掉某个步骤
- 3、更易于生产/复制:直接调用fit和predict来对管道中所有的算法模型进行一次性进行训练和预测
- 4、简化模型验证过程:网格搜索(grid search)可以遍历管道中所有评估器等参数
pipeline数用(key,value)的列表构建的,其中key数步骤名称的字符串,而value时一个估计器对象
Sklearn中有2个pipeline类型的模块,分别是
- 1、ColumnTransformer,主要用于用于数据于特征处理的工作流,可并行
- 2、pipeline,可用于任何需求的工作流,只能串行
注意:管道中的所有评估器,除了最后一个评估器,管道的所有评估器必须是转换器。例如,必须有transform方法。最后一个评估器的类型不限(转换器、分类器等)
二、为什么使用pipeline
正如介绍中所说,可以简化流程,如果不使用呢,请看如下模型示例
1.读入数据集
# 读入数据集,数据探索 df = pd.read_csv('./data/L1_L2/保险数据_第一期.csv') df.head(5)
2、数据预处理
1、缺失值、重复值处理
# 数据与特征处理 #重复值 df.duplicated().sum() #缺失值(缺失值占比很少,直接删除) df1 = df.dropna() # 异常值,可不处理 #分割标签 labels = df1.pop('resp_flag')2、数据编码、标准化
# 数据类型拆分 cat_cols = df1.select_dtypes(include=['object']) # 分类型变量 num_cols = df1.select_dtypes(exclude=['object']) # 数值型变量 # 数据编码 from sklearn.preprocessing import OrdinalEncoder cat_encode = OrdinalEncoder() cat_trans = cat_encode.fit_transform(cat_cols) df_cat = pd.DataFrame(cat_trans,columns=cat_cols.columns) # 数据标准化 from sklearn.preprocessing import StandardScaler num_std = StandardScaler() num_trans = num_std.fit_transform(num_cols) df_num = pd.DataFrame(num_trans,columns=num_cols.columns) # 数据合并 data = pd.concat([df_cat,df_num],axis=1)3、分割数据集
# 分割测试集 from sklearn.model_selection import train_test_split xtrainn,xtest,Ytrain,Ytest = train_test_split(data,labels,test_size=0.3,stratify=labels,random_state=42)4、模型训练、预测
# 模型选择-决策树 from sklearn.tree import DecisionTreeClassifier DT = DecisionTreeClassifier() DT.fit(xtrainn,Ytrain) from sklearn.metrics import classification_report print(classification_report(Ytest,DT.predict(xtest)))
# 模型选择-逻辑回归 from sklearn.linear_model import LogisticRegression LR = LogisticRegression() LR.fit(xtrainn,Ytrain) from sklearn.metrics import classification_report print(classification_report(Ytest,LR.predict(xtest)))
5、调参:网格搜索
# 调参,网格搜索 from sklearn.model_selection import GridSearchCV #参数字典 param = {'C':np.arange(1,2,0.1), # 启、止,步长 'class_weight':[None,'balanced'] } lr = LogisticRegression() grid_lr = GridSearchCV(lr,param,n_jobs=1) grid_lr.fit(xtrainn,Ytrain) print(classification_report(Ytrain,grid_lr.predict(xtrainn))) grid_lr.best_params_ grid_lr.best_score_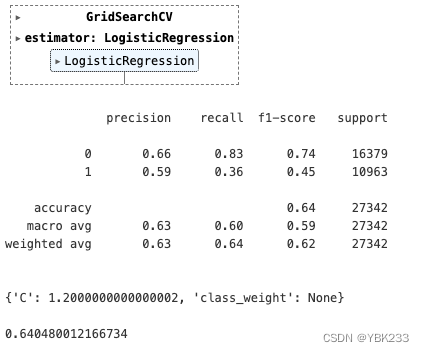
6、模型保存
# 模型保存(与读取) import joblib joblib.dump(grid_lr,'grid_lr_model_20240516.joblib')
7、预测新进用户
数据读取
df_new = pd.read_csv('./data/L1_L2/保险案例_新进用户.csv') df_new
grid_lr.predict(df_new)
结论:从报错不难看出,需要重新做数据清洗,很麻烦,所以考虑使用pipeline。三、pipeline示例
1、读取数据
from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity='all' import pandas as pd import numpy as np import warnings warnings.filterwarnings('ignore') # 数据导入、处理 df1 = pd.read_csv('./data/L1_L2/保险数据_一.csv') labels = df1.pop('resp_flag') #取出y2、数据处理
1、数据类型拆分
# 数据类型拆分 cat_cols = df1.select_dtypes(include=['object']) # 分类型变量 num_cols = df1.select_dtypes(exclude=['object']) # 数值型变量引入机器学习相关包
from sklearn.impute import SimpleImputer from sklearn.preprocessing import OrdinalEncoder,StandardScaler from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer2、分类变量处理
# 分类型变量 cat_imp = SimpleImputer(strategy='most_frequent') cat_encode = OrdinalEncoder() cat_pipeline = Pipeline(steps=[('cat_imp',cat_imp),('cat_encode',cat_encode)]) # list of (name ,transform) tuples3、数值变量处理
# 数值型变量 num_imp = SimpleImputer(strategy='mean') num_std = StandardScaler() num_pipeline = Pipeline(steps=[('num_imp',num_imp),('num_std',num_std)]) # columnTransformer,list(name,transformer,columns) tuples cat_trains = ColumnTransformer(transformers=[('cat_pipeline',cat_pipeline,cat_cols.columns), ('num_pipeline',num_pipeline,num_cols.columns)])单元测试
# 单元测试 aaa = cat_trains.fit_transform(df1) pd.DataFrame(aaa)3、建立pipeline
# 实例化模型,建立pipeline from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr_pipeline = Pipeline(steps=[('cat_trains',cat_trains),('lr',lr)])4、分割数据集
# 分割测试集 from sklearn.model_selection import train_test_split xtrainn,xtest,Ytrain,Ytest = train_test_split(df1,labels,test_size=0.3,stratify=labels,random_state=42)5、建模、调参
# 网格搜索,使用_ 访问每个transform内部等参数 from sklearn.model_selection import GridSearchCV #参数字典 param = dict(lr__C = np.arange(1,2,0.1), # 启、止,步长 lr__class_weight = [None,'balanced'], cat_trains__num_pipeline__num_imp__strategy = ['mean','median'] #从外向内一层层写转换器 ) grid_lr_pipeline = GridSearchCV(lr_pipeline,param,cv=3,n_jobs=-1) grid_lr_pipeline.fit(xtrainn,Ytrain) 
6、查看最优参数组合
grid_lr_pipeline.best_params_ grid_lr_pipeline.best_score_
7、查看预测效果
from sklearn.metrics import classification_report print(classification_report(Ytest,grid_lr_pipeline.predict(xtest)))
8、模型保存
# 模型保存 import joblib joblib.dump(grid_lr_pipeline,'grid_lr_pipeline_model_20240516.joblib')9、使用新数据集预测
# 预测新进用户 df_new = pd.read_csv('./data/L1_L2/保险案例_新进用户.csv') grid_lr_pipeline.predict(df_new)
-
相关阅读:
vue3.0 实现图片延迟加载 自定义属性
MES管理系统在柔性制造中有何重要作用
仓颉语言HelloWorld内测【仅需三步】
大热电视剧《好事成双》里的IT故事:用户数据泄露事件引出的美女黑客
【JS 判断数组是否包含某个元素】
11.14 知识总结(视图层、模层板)
springboot自动扫描添加的BeanDefinition源码解析
蓝桥杯练习笔记(十五)
完全指南:mv命令用法、示例和注意事项 | Linux文件移动与重命名
2022最新Java后端面试题(带答案),重点都给画出来了!你不看?
- 原文地址:https://blog.csdn.net/YBK233/article/details/139408034