-
【面试题-004】ArrayList 和 LinkList区别
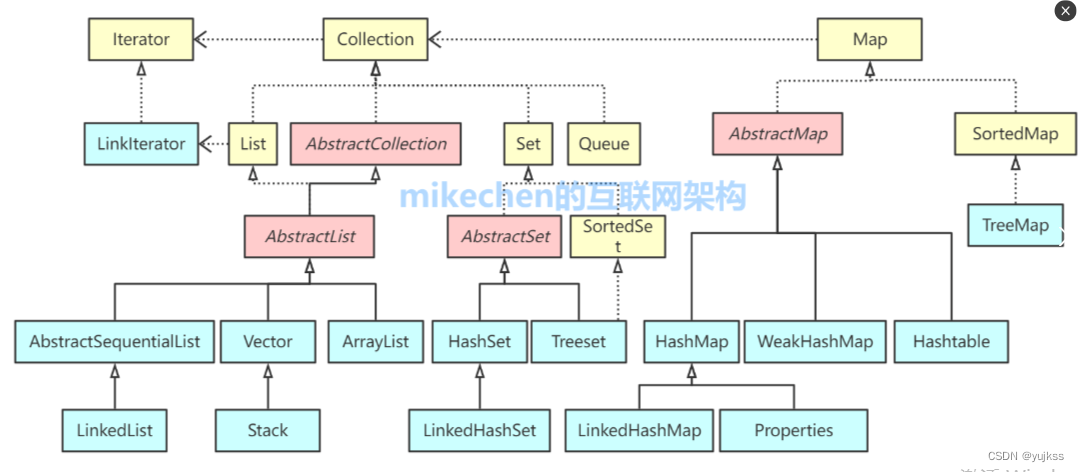
ArrayList和LinkedList都是 Java 中常用的动态数组实现,都实现了List接口,但它们在内部数据结构和性能方面有所不同:- 内部数据结构:
ArrayList是基于动态数组的数据结构,它允许快速随机访问。数组的大小在创建时是固定的,当数组满时,ArrayList会自动扩容,创建一个新的更大的数组,并将原数组的内容复制到新数组中。LinkedList是基于双向链表的数据结构,每个元素都是一个节点,包含数据和两个指针,分别指向前一个节点和后一个节点。链表的特点是元素可以灵活地插入和删除,不需要移动其他元素。
- 性能:
ArrayList提供了更快的随机访问和顺序访问速度,时间复杂度为 O(1)。但是,在数组中间插入或删除元素时,需要移动目标位置后的所有元素,时间复杂度为 O(n)。LinkedList在链表中间插入和删除元素非常快,时间复杂度为 O(1)。但是,随机访问较慢,时间复杂度为 O(n),因为需要从头节点或尾节点开始遍历链表。
- 内存占用:
ArrayList由于是基于数组的,需要连续的内存空间,而且在扩容时可能会浪费一些内存(因为新数组可能会留有未使用的空间)。LinkedList每个元素都需要额外的内存来存储指向前一个和后一个节点的指针,因此在存储大量元素时,可能会比ArrayList使用更多的内存。
- 适用场景:
- 当需要频繁进行随机访问操作时,
ArrayList是更好的选择。 - 当需要频繁在列表中间进行插入和删除操作时,
LinkedList更适合。
选择ArrayList还是LinkedList取决于具体的应用场景和对性能的需求。在实际开发中,ArrayList由于其优异的随机访问性能,通常是最常用的列表实现。只有在特定的场景下,当链表的特性(如频繁的插入和删除操作)能带来明显的性能优势时,才会考虑使用LinkedList。
- 当需要频繁进行随机访问操作时,
List和set
Java 提供了丰富的集合框架(Collection Framework),用于存储和管理对象集合。这些集合可以分为几个主要类别:
- List(列表):列表是一个有序的集合,可以包含重复的元素。实现 List 接口的类包括:
ArrayList:基于动态数组的数据结构,提供快速的随机访问和顺序访问。LinkedList:基于双向链表的数据结构,提供快速的插入和删除操作。Vector:和ArrayList类似,但是是同步的,适用于多线程环境。不过,由于同步带来的性能开销,通常建议使用ArrayList并自行同步,或者使用并发集合。
- Set(集):集是一个无序的集合,不包含重复的元素。实现 Set 接口的类包括:
HashSet:基于哈希表实现,提供快速的插入、删除和查找操作。LinkedHashSet:具有HashSet的查找效率,并且维护了插入顺序。TreeSet:基于红黑树实现,可以确保元素处于排序状态。EnumSet:用于存放枚举类型,内部使用位向量实现,非常高效。
- Queue(队列):队列是一个先进先出(FIFO)的数据结构。实现 Queue 接口的类包括:
PriorityQueue:基于优先级堆的无界优先队列。LinkedList:也可以用作队列,因为实现了Queue接口。ArrayDeque:是一个可扩容的双端队列,可以作为栈或队列使用。
- Deque(双端队列):双端队列允许在队列的两端进行元素的插入和删除。实现 Deque 接口的类包括:
ArrayDeque:基于数组的双端队列实现。LinkedList:也可以用作双端队列。
- Map(映射):映射是一个键值对集合,键不包含重复的元素。实现 Map 接口的类包括:
HashMap:基于哈希表实现,提供快速的查找、插入和删除操作。LinkedHashMap:维护了插入顺序的HashMap。TreeMap:基于红黑树实现,可以确保键处于排序状态。Hashtable:和HashMap类似,但是是同步的,适用于多线程环境。同样,由于同步带来的性能开销,通常建议使用HashMap并自行同步,或者使用并发集合。EnumMap:键为枚举类型的特殊映射,内部使用数组实现,非常高效。
- 并发集合:Java 提供了一些线程安全的集合,用于多线程环境:
ConcurrentHashMap:线程安全的HashMap。CopyOnWriteArrayList:线程安全的ArrayList,适用于读多写少的场景。CopyOnWriteArraySet:线程安全的Set,适用于读多写少的场景。BlockingQueue:线程安全的队列,用于生产者-消费者模式。ConcurrentLinkedQueue:线程安全的非阻塞队列。
- 其他集合:
Stack:栈是一个后进先出(LIFO)的数据结构,Java 中没有单独的Stack类,而是使用Deque接口的实现类,如ArrayDeque,来实现栈的功能。
这些集合类和接口都在java.util包中,除了并发集合,它们大多在java.util.concurrent包中。Java 的集合框架提供了丰富的API,使得操作集合变得非常方便和灵活。
ArrayList扩容机制
ArrayList是 Java 中使用最广泛的动态数组实现之一。它允许我们动态地添加和删除元素,而不需要担心数组的固定大小。ArrayList的扩容机制是其核心特性之一,下面是它的工作原理:- 初始容量:
- 当我们创建一个
ArrayList对象时,可以指定一个初始容量,如果没有指定,默认容量为 10。
- 当我们创建一个
- 扩容时机:
- 当我们尝试添加元素到
ArrayList中,并且数组的当前大小不足以容纳新元素时,ArrayList需要进行扩容。
- 当我们尝试添加元素到
- 扩容过程:
ArrayList通过一个内部数组来存储元素。当需要扩容时,它会创建一个新的更大的数组(通常是原数组大小的 1.5 倍),然后将原数组中的所有元素复制到新数组中。- 这个过程是通过
System.arraycopy()方法实现的,它是一个本地方法,可以高效地复制数组。
- 内存复制:
- 扩容涉及到内存复制,这是一个相对昂贵的操作,因为它需要将所有现有元素从一个数组复制到另一个数组。
- 因此,虽然
ArrayList提供了动态添加元素的便利,但在大量添加元素的场景下,频繁的扩容可能会影响性能。
- 预分配:
- 为了避免频繁的扩容操作,如果预先知道将要存储的元素数量,可以在创建
ArrayList时指定一个足够大的初始容量,这样可以减少扩容的次数。
- 为了避免频繁的扩容操作,如果预先知道将要存储的元素数量,可以在创建
- 缩容:
ArrayList没有提供自动缩容的功能。如果需要减少存储空间的使用,可以通过调用trimToSize()方法来缩小数组的大小以匹配当前元素数量。
扩容机制是ArrayList能够灵活地处理元素数量的变化的关键,但它也带来了性能上的考虑。在实际使用中,根据应用场景和性能要求,合理地管理ArrayList的容量是非常重要的。
HashMap扩容机制
HashMap是 Java 中使用哈希表实现的映射接口,它存储键值对(key-value pairs)。HashMap的扩容机制是其核心特性之一,用于处理哈希表中的哈希冲突和提高性能。下面是HashMap的扩容机制的工作原理:- 初始容量和负载因子:
- 创建
HashMap时,可以指定初始容量和负载因子。初始容量是哈希表中的桶数,负载因子是哈希表填充程度的度量标准。
- 创建
- 扩容时机:
- 当
HashMap中的元素数量达到容量和负载因子的乘积时,即HashMap的实际大小超过了负载因子与当前容量的乘积,HashMap就会进行扩容。
- 当
- 扩容过程:
- 扩容过程涉及创建一个新的更大的数组(通常是原数组大小的两倍),然后将原数组中的所有元素重新哈希并复制到新数组中。
- 重新哈希是因为哈希表的容量改变了,每个键的哈希值与新容量之间的关系可能会改变,因此需要重新计算每个键的索引位置。
- 内存复制:
- 扩容涉及到内存复制,这是一个相对昂贵的操作,因为它需要将所有现有元素从一个数组复制到另一个数组,并重新计算每个元素的哈希值。
- 这个过程是通过数组的复制和链表的遍历来实现的。
- 链表和红黑树:
- 在
HashMap中,哈希表的每个桶可能包含一个链表或一棵红黑树。当桶中的元素数量超过一定阈值时,链表会转换为红黑树,以提高搜索效率。 - 扩容时,链表和红黑树中的元素都需要重新哈希和重新组织。
- 在
- 性能考虑:
- 频繁的扩容可能会影响
HashMap的性能,因为每次扩容都需要重新哈希和复制所有元素。 - 为了避免性能问题,如果预先知道将要存储的键值对数量,可以在创建
HashMap时指定一个足够大的初始容量。
HashMap的扩容机制是为了保持哈希表的性能和效率,同时处理哈希冲突。在实际使用中,根据应用场景和性能要求,合理地管理HashMap的容量是非常重要的。
- 频繁的扩容可能会影响
HashMap初始容量(Initial Capacity)和负载因子(Load Factor)
在 Java 的
HashMap中,初始容量(Initial Capacity)和负载因子(Load Factor)是两个重要的参数,它们在创建HashMap时可以进行调整,以优化性能和内存使用。- 初始容量:
- 初始容量是指
HashMap创建时的桶数,即内部数组的大小。默认的初始容量是 16。 - 设置一个合适的初始容量可以减少扩容操作的次数,从而提高性能。如果预先知道将要存储的键值对数量,可以选择一个接近于预期数量的初始容量,但最好保持为 2 的幂,因为
HashMap使用哈希值与数组长度的模运算来定位元素,2 的幂可以使得这个运算更高效。
- 初始容量是指
- 负载因子:
- 负载因子是衡量
HashMap填充程度的一个指标,它决定了HashMap何时进行扩容。负载因子的默认值是 0.75。 - 负载因子等于当前元素数量(即键值对的数量)与内部数组大小的比值。当
HashMap中的元素数量达到负载因子与内部数组大小的乘积时,HashMap就会进行扩容,通常是容量翻倍。 - 设置一个较低的负载因子可以减少哈希冲突的概率,但会增加内存的使用和扩容操作的频率。设置一个较高的负载因子可以节省内存,但可能会增加哈希冲突的概率和链表的长度,从而降低性能。
在实际应用中,选择合适的初始容量和负载因子取决于具体的使用场景。如果对内存使用非常敏感,可以选择一个较高的负载因子。如果对性能要求较高,尤其是在插入和查找操作非常频繁的情况下,可以选择一个较低的负载因子,并设置一个足够大的初始容量以减少扩容操作的次数。
- 负载因子是衡量
HashMap与HashTable区别 ?HashMap底层数据结构?
HashMap和Hashtable都是 Java 中用于存储键值对的数据结构,但它们之间有一些关键的区别:- 同步性:
HashMap不是同步的,如果多个线程同时访问并修改HashMap,必须外部同步。Hashtable是同步的,它所有的公共方法都是同步的,适用于多线程环境。但是,这会带来性能开销,因为它需要锁定整个表来防止并发修改。
- null值和null键:
HashMap允许使用一个 null 键和多个 null 值。Hashtable不允许使用 null 键或 null 值。
- 迭代顺序:
HashMap提供了更快的迭代速度,并且迭代顺序是不确定的。Hashtable的迭代速度较慢,并且迭代顺序也是不确定的。
- 继承:
HashMap继承自AbstractMap类。Hashtable继承自Dictionary类,这是一个已经被废弃的类。
- 性能:
HashMap通常提供比Hashtable更好的性能,因为HashMap的实现更加优化。
- 历史:
Hashtable是早期 Java 版本中的实现,而HashMap是在 Java 2(JDK 1.2)中引入的。
HashMap的底层数据结构是一个数组,数组的每个元素是一个链表(在 Java 8 及更高版本中,链表在达到一定长度后会转换为红黑树以提高性能)。这个数组被称为桶(bucket)数组,每个桶对应一个哈希值。当插入一个键值对时,首先会根据键的哈希值计算出桶的索引,然后将键值对存储在相应的桶中的链表(或红黑树)中。如果两个不同的键产生了相同的哈希值,会发生哈希冲突,这时会在同一个桶中的链表(或红黑树)中存储这两个键值对。
由于Hashtable的许多特性已经被HashMap替代,并且Hashtable的同步性能较差,通常建议在不需要线程安全的场景下使用HashMap,在需要线程安全的场景下使用ConcurrentHashMap。
ConcurrentHashMap底层数据结构?
ConcurrentHashMap是 Java 中的一个线程安全的映射实现,它位于java.util.concurrent包中。ConcurrentHashMap的底层数据结构在 Java 8 及其之后的版本中经历了一些变化,下面是主要的组成:- 节点(Node):
ConcurrentHashMap中的元素以节点(Node)的形式存储,每个节点包含键、值、哈希值和指向下一个节点的指针。
- 数组(Segment)(Java 8 之前):
- 在 Java 8 之前的版本中,
ConcurrentHashMap使用了一个分段锁(Segment)的数据结构,其中内部数组被分割成多个段,每个段是一个独立的锁结构,用于减少锁竞争。 - 每个段包含一个小的哈希表,用于存储节点。
- 在 Java 8 之前的版本中,
- 桶(Bucket)数组(Java 8 及之后):
- 从 Java 8 开始,
ConcurrentHashMap的底层数据结构被重新设计,去掉了分段锁,转而使用一个大的桶数组(也称为哈希桶数组或哈希表),类似于HashMap的结构。 - 桶数组中的每个桶可能包含一个链表或一棵树(红黑树),用于解决哈希冲突。
- 从 Java 8 开始,
- 链表和红黑树:
- 当多个键映射到同一个桶时,这些键值对以链表的形式存储。
- 在链表长度超过一定阈值后,链表会被转换成红黑树,以提高搜索效率。
- CAS(Compare-And-Swap)操作:
ConcurrentHashMap使用了无锁算法和 CAS 操作来实现并发安全,这是一种乐观锁策略,它允许在不加锁的情况下对数据进行修改,只有当预期值与实际值相同时才进行更新。
- 同步机制:
ConcurrentHashMap使用了细粒度的同步机制,只对哈希桶数组中的特定桶进行锁定,而不是整个映射,这大大减少了锁竞争,提高了并发性能。
ConcurrentHashMap的设计目的是提供一种高效的线程安全映射,它在多线程环境中提供了良好的并发性能,同时避免了Hashtable的全局锁带来的性能瓶颈。
- 内部数据结构:
-
相关阅读:
防火墙原理讲解——练习实验
升级到 jQuery 3.6.1 遇见的几个坑以及应对方法
io多路复用之poll的详细执行过程
你的凭据不工作(Win10远程桌面Win10)详细解决路线
一看就懂:正则表达式
【一周安全资讯1014】交通运输部发布《公路工程设施支持自动驾驶技术指南》;多地网信办对违反数据安全法规企业作出行政处罚
接口自动化测试系列-接口测试
今抖云创—短视频需要的那些自媒体工具
Java基础:设计模式之抽象工厂模式
Linux常用命令——chown命令
- 原文地址:https://blog.csdn.net/qq_39900031/article/details/139391468