-
Hadoop3:HDFS、YARN、MapReduce三部分的架构概述及三者间关系(Hadoop入门必须记住的内容)
一、HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。

1)
NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。理解为集群数据索引
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。二、YARN架构概述
Yet Another Resource Negotiator简称YARN,另一种资源协调者,是Hadoop的资源管理器

1)ResourceManager(RM):整个集群资源(内存、CPU等)的管理者,负责分配和回收集群资源
3)ApplicationMaster(AM):单个任务运行的管理者
2)NodeManager(NM):单个节点服务器资源的管理者
4)Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等,可以类比理解成docker容器说明
1:客户端可以有多个
2:集群上可以运行多个ApplicationMaster
3:每个NodeManager上可以有多个Container三、MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map 和 Reduce
1)Map阶段并行处理数据,分配任务
2)Reduce阶段对Map结果进行汇总
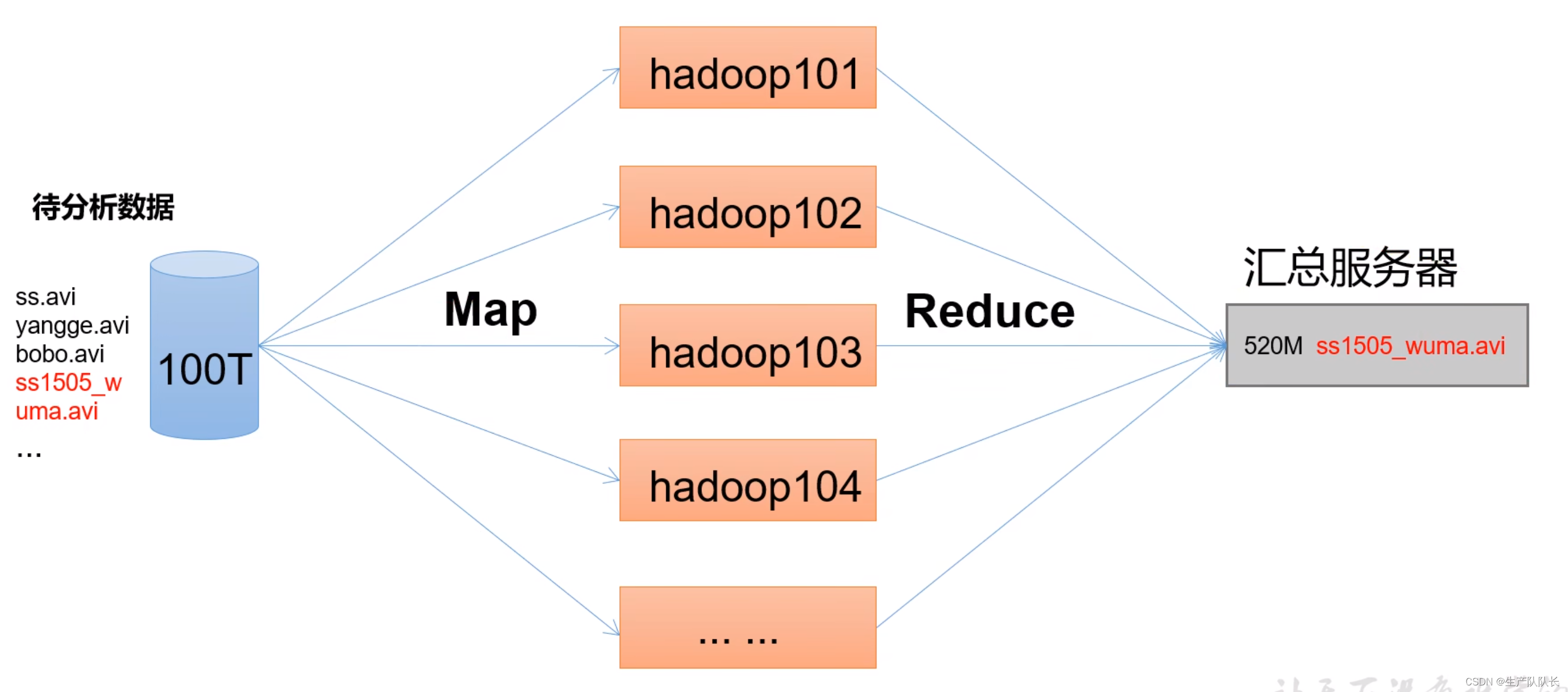
四、HDFS、YARN、MapReduce三者关系
对下图工作过程进行简要说明:
首先,集群的HDFS存储了海量数据,然后,客户端提交了一个查询任务,任务提交到RM,RM找到一台有空闲资源的NM,然后,RM创建Container和App Mstr,然后,由App Mstr向RM申请资源,进入计算任务的Map阶段,接着创建了如图的102和103上的两个Container和MapTask,最后,进入Reduce阶段,在104上创建Container和ReduceTask,汇总Map阶段的结果,并写入HDFS。

-
相关阅读:
Python 越来越火爆
kvm部署
org.activiti.engine
Lamt的部署
Spring源码解析——事务增强器
MySQL——库和表的增删改
深度学习的炼金术:转化数据为黄金的秘密
Proxmox download
Vue 3响应式系统全解析:深入ref、reactive、computed、watch及watchEffect
YOLOV5学习笔记(七)——训练自己数据集
- 原文地址:https://blog.csdn.net/Brave_heart4pzj/article/details/138034637