-
Elasticsearch
1.初识elasticsearch
1.1 elasticsearch的作用
elasticsearch是一款非常强大的开源
搜索引擎, 可以帮助我们从海量数据中快速找到需要的内容1.2 elasticsearch和lucene的关系
elasticsearch底层是基于lucene来实现的
- 1999年, DougCutting研发了lucene
- 2004年, Shay Banon基于Lucene开发了Compass
- 2010年, Shay Banon重写了Compass, 取名为Elasticsearch
1.3 目前流行的搜索引擎技术排名

虽然在早期,Apache Solr是最主要的搜索引擎技术,但随着发展elasticsearch已经渐渐超越了Solr,独占鳌头1.4 为什么使用elasticsearch作为搜索引擎
- 全文检索
- 分布式性能
1.全文检索
Elasticsearch是专门针对全文搜索场景设计的搜索引擎, 具有优秀的全文搜索性能, 可以对文本内容进行全面和灵活的搜索, 包括单词匹配、短语匹配、模糊搜索等。它还支持基于分析器的文本处理,包括分词、词干提取和同义词处理,从而提高搜索结果的准确性和相关性。它的全文检索优势, 得益于这几个方面:
- 倒排索引: 使用了倒排索引来存储文档和词项之间的关系
- 分词和词项处理: 在索引文档时, Elasticsearch会对文本内容进行分词, 并将词项存储在倒排索引中。这些分词和词项处理技术可以帮助提高搜索结果的准确性和相关性
- 复杂查询支持: Elasticsearch支持丰富的查询语法和功能,包括布尔查询、短语查询、模糊查询、范围查询等。它还支持多字段查询、字段加权、近似匹配等高级功能,能够满足各种复杂的搜索需求
- 近实时搜索: 在文档被索引后几乎立即就可以进行搜索, 而传统数据库在插入新记录或更新现有记录时, 会更新索引, 新的数据可能无法立即被搜索到, 有一段延迟, 不够实时
2.分布式性能
使用 MySQL 来处理搜索请求,可能会面临以下问题:- 单点故障: MySQL 是一个传统的关系型数据库,通常是基于单节点架构设计的。如果搜索请求过多,单个 MySQL
节点可能会成为瓶颈,导致系统性能下降甚至崩溃。 - 水平扩展困难: 虽然 MySQL
支持主从复制和分区等方式来提高性能和可用性,但是在面对大规模数据和高并发请求时,很难实现有效的水平扩展,而且需要投入大量的人力和资源。
相比之下,如果使用 Elasticsearch 来处理搜索请求,则可以获得更好的分布式性能:
- 分布式存储和搜索: Elasticsearch 是基于分布式架构设计的,数据被分散存储在多个节点上,并且可以水平扩展以处理大规模数据。当用户发起搜索请求时,Elasticsearch 可以同时在多个节点上执行搜索,并将结果合并返回,从而提高搜索性能和吞吐量。
- 负载平衡和自动恢复: Elasticsearch 具有良好的负载平衡和自动恢复能力,可以在节点故障或网络分区的情况下保持系统的稳定性和可用性。即使有节点发生故障,Elasticsearch 也能够自动重新分配数据和重新平衡负载,确保系统的正常运行
2.倒排索引
倒排索引有两个非常重要的概念:
- 文档(Document): 用来搜索的文档数据, 可以是一个商品详情、收货地址等
- 词条(Term): 对文档内容进行分词后, 得到具备含义的词语就是词条. 例如: 我是中国人, 就可以分为我、是、中国人、中国、国人这些词条
2.1 正排索引和倒排索引
1.正向索引
会将索引字段的值(词条)以及对应的记录信息记录下来, 当进行查询时, 搜索引擎先根据查询条件匹配索引字段的值, 然后根据值找到对应的记录位置, 从而定位到相关的记录

正向索引不支持
%索引值%的模糊查询, 因为正向索引是按索引值的顺序存储的, 对于模糊查询, 例如%索引值%, 无法利用索引树的中间节点来快速定位, 最终只能全表扫描, 全表扫描的缺点就是随着数据量增加, 其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难2.倒排索引
创建倒排索引是对正向索引的一种特殊处理,流程如下:- 文档分词: 对文档中的文本内容进行分词处理, 拆分为一个个词条
- 词条关联文档: 对于每个词条, 建立文档列表, 这个文档列表包含每个文档的标识符(例如ID、行号等)
- 索引合并、排序: 将所有词条合并起来, 并按词条的字典顺序进行排序. 这样就构建了完整的倒排索引结构

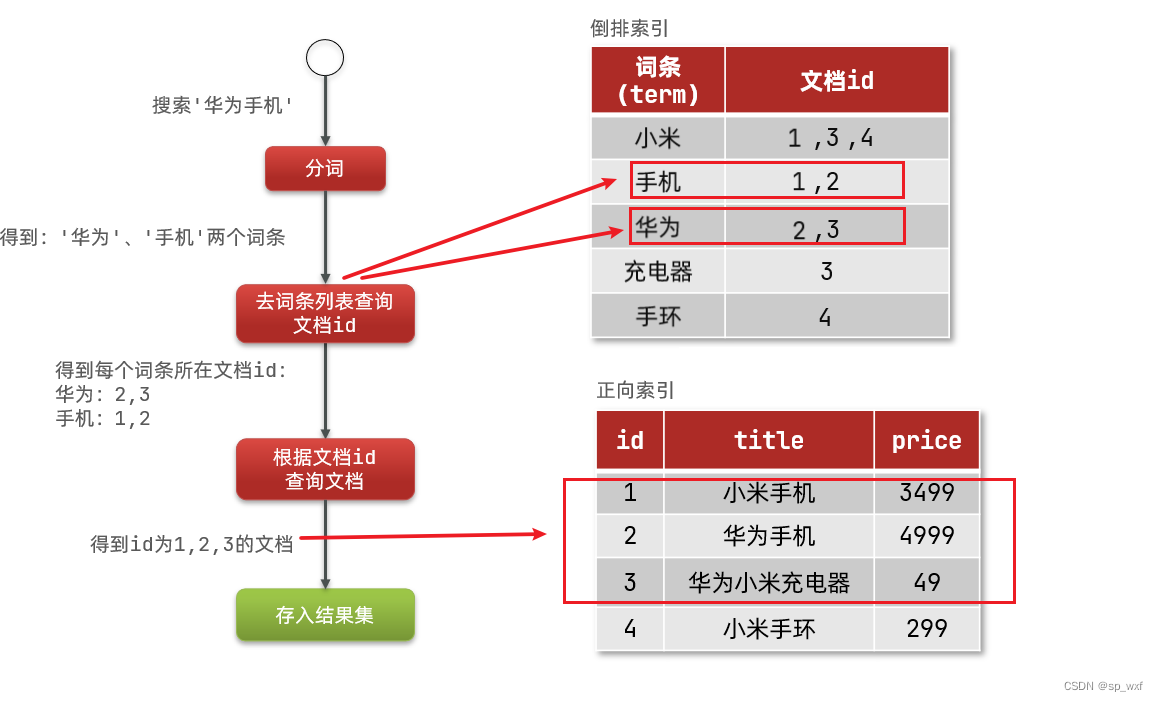
搜索流程:- 用户输入
华为手机进行搜索 - 对输入内容进行分词, 得到词条:
华为、手机 - 拿着词条在倒排索引中查找,可以得到包含词条的文档id: 1、2、3
- 拿着文档id到正向索引中查找具体文档
两者区别
- 正排索引
- 优点
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点
- 根据非索引字段, 或者索引字段中的部分词条查找时, 只能全表扫描
- 优点
- 倒排索引
- 优点
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点
- 只能给词条创建索引, 而不是字段
- 无法根据字段做排序
- 优点
3.Elasticsearch概念
3.1 文档和字段
- 文档: elasticsearch是面向
文档(Document)存储的, 可以是数据库中的一条商品数据, 一个订单信息, 文档数据会被序列化为json格式后存储在elasticsearch中 - 字段: Json文档中往往包含很多的
字段(Field), 类似于数据库中的列。

3.2 索引和映射
- 索引: 相同类型的文档的集合, 相当于数据库中的表
- 映射: 约束文档的字段信息, 类似于数据库中的表结构

3.3 mysql和elasticsearch
Mysql Elasticsearch 说明 Table Index 索引, 就是同类文档的集合, 类似于数据库的表 Row Document 文档, 就是一条条记录, 类似于数据库中的一行数据, 文档都是JSON格式 Column Field 字段, 就是JSON文档中的字段, 类似数据库中的列 Schema Mapping Mapping(映射)是索引中文档的约束, 例如字段类型约束. 类似数据库的表结构(Schema) SQL DSL DSL是elasticsearch提供的JSON风格的请求语句, 用来操作elasticsearch, 实现CRUD - Mysql: 擅长事务类型操作, 可以确保数据的安全和一致性
- Elasticsearch: 擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作, 使用mysql实现
- 对查询性能要求较高的搜索需求, 使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
-
相关阅读:
【Qt】QML与C++的前后端交互与通信方法
传统大数据迁移遇到的问题与解决方案
线上发生锁表怎么办 show processlist命令详解
QDataStream
使用opencv及FFmpeg编辑视频
英语写作中“限制”limit、restrict、constrain的用法
JavaScript系列之变量
idea配置springboot热部署
Redis 的 Java 客户端(Jedis、SpringDataRedis、SpringCache、Redisson)基本操作指南
NoSQL 数据库管理工具,搭载强大支持:Redis、Memcached、SSDB、LevelDB、RocksDB,为您的数据存储提供无与伦比的灵活性与性能!
- 原文地址:https://blog.csdn.net/qq_24099547/article/details/137938433