-
基于Flask的岗位就业可视化系统(四)
前言
-
本项目综合了基本数据分析的流程,包括数据采集(爬虫)、数据清洗、数据存储、数据前后端可视化等
-
推荐阅读顺序为:数据采集——>数据清洗——>数据库存储——>基于Flask的前后端交互,有问题的话可以留言,有时间我会解疑~
-
感谢阅读、点赞和关注
开发环境
- 系统:Window 10 家庭中文版。
- 语言:Python(3.9)、MySQL。
- Python所需的库:pymysql、pandas、numpy、time、datetime、requests、etree、jieba、re、json、decimal、flask(没有的话pip安装一下就好)。
- 编辑器:jupyter notebook、Pycharm、SQLyog。
(如果下面代码在jupyter中运行不完全,建议直接使用Pycharm中运行)
文件说明
本项目下面有四个.ipynb的文件,下面分别阐述各个文件所对应的功能:(有py版本 可后台留言)-
数据采集:分别从前程无忧网站和猎聘网上以关键词数据挖掘爬取相关数据。其中,前程无忧上爬取了270页,有超过1万多条数据;而猎聘网上只爬取了400多条数据,主要为岗位要求文本数据,最后将爬取到的数据全部储存到csv文件中。
-
数据清洗:对爬取到的数据进行清洗,包括去重去缺失值、变量重编码、特征字段创造、文本分词等。
-
数据库存储:将清洗后的数据全部储存到MySQL中,其中对文本数据使用jieba.analyse下的extract_tags来获取文本中的关键词和权重大小,方便绘制词云。
-
基于Flask的前后端交互:使用Python一个小型轻量的Flask框架来进行Web可视化系统的搭建,在static中有css和js文件,js中大多为百度开源的ECharts,再通过自定义controller.js来使用ajax调用flask已设定好的路由,将数据异步刷新到templates下的main.html中。
技术栈
- Python爬虫:(requests和xpath)
- 数据清洗:详细了解项目中数据预处理的步骤,包括去重去缺失值、变量重编码、特征字段创造和文本数据预处理 (pandas、numpy)
- 数据库知识:select、insert等操作,(增删查改&pymysql) 。
- 前后端知识:(HTML、JQuery、JavaScript、Ajax)。
- Flask知识:一个轻量级的Web框架,利用Python实现前后端交互。(Flask)
四、基于Flask的前后端交互
定义函数来获取数据库中的数据
导入模块
from flask import Flask as _Flask, jsonify, render_template from flask.json import JSONEncoder as _JSONEncoder import pandas as pd import numpy as np import pymysql, decimal, time- 1
- 2
- 3
- 4
- 5
将清洗后的数据存储到sql中
def get_time(): time_str = time.strftime("%Y{}%m{}%d{} %X") return time_str.format("年", "月", "日") # 连接数据库 def get_con(): con = pymysql.connect(host='localhost', user='用户名', password='密码', database='数据库名', charset='utf8') cursor = con.cursor() return con, cursor # 关闭数据库 def con_close(con, cursor): if cursor: cursor.close() if con: con.close() # 定义函数来执行单独一条sql语句 def query(sql): con, cursor = get_con() cursor.execute(sql) res = cursor.fetchall() con_close(con, cursor) return res # 定义函数 def get_c1_data(): ... def get_c2_data(): ... def get_l1_data(): ... def get_l2_data(): ... def get_r1_data(): ... def get_r2_data(): ... ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
使用flask框架进行网页的搭建
网页搭建思路:
首先,构造获取数据库特定数据的函数;
接着,在flask中设置相关路由,调用该函数,并return获取的数据;
然后,在main.html页面导入设定好的javascript脚本,脚本中使用ajax来接收路由的数据;
最后便将数据通过jquery来映射到html页面中,总体上实现了前后端交互的功能。
class JSONEncoder(_JSONEncoder): def default(self, o): if isinstance(o, decimal.Decimal): return float(o) super(_JSONEncoder, self).default(o) class Flask(_Flask): json_encoder = JSONEncoder app = Flask(__name__) # 路由解析 @app.route('/') def index(): return render_template("main.html") # 获取系统当前时间 @app.route('/time') def get_time1(): return get_time() # 对数据库中的数据进行计数、薪资取平均值、省份和学历取众数 @app.route('/c1') def get_c1_data1(): data = get_c1_data() return jsonify({"employ": data[0], "avg_salary": data[1], "province": data[2], "edu": data[3]}) # 对省份进行分组,之后统计其个数 @app.route('/c2') def get_c2_data1(): res = [] for tup in get_c2_data(): res.append({"name": tup[0], "value": int(tup[1])}) return jsonify({"data": res}) # 统计每个学历下公司数量和平均薪资(上下坐标折线图) @app.route('/l1') def get_l1_data1(): data = get_l1_data() edu, sum_company, avg_salary = [], [], [] for s in data: edu.append(s[0]) sum_company.append(int(s[1])) avg_salary.append(float(s[2])) return jsonify({"edu": edu, "sum_company": sum_company, "avg_salary": avg_salary}) # 统计不同学历下公司所招人数和平均经验(折线混柱图) @app.route('/l2') def get_l2_data1(): data = get_l2_data() edu, num, exp = [], [], [] for s in data: edu.append(s[0]) num.append(float(s[1])) exp.append(float(s[2])) return jsonify({'edu': edu, 'num': num, 'exp': exp}) # 统计不同类型公司所占的数量(饼图) @app.route('/r1') def get_r1_data1(): res = [] for tup in get_r1_data(): res.append({"name": tup[0], "value": int(tup[1])}) return jsonify({"data": res}) # 可视化词云 @app.route('/r2') def get_r2_data1(): d = [] text, weight = get_r2_data() for i in range(len(text)): d.append({'name': text[i], 'value': weight[i]}) return jsonify({"kws": d}) if __name__ == '__main__': app.run()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
未加数据库效果图
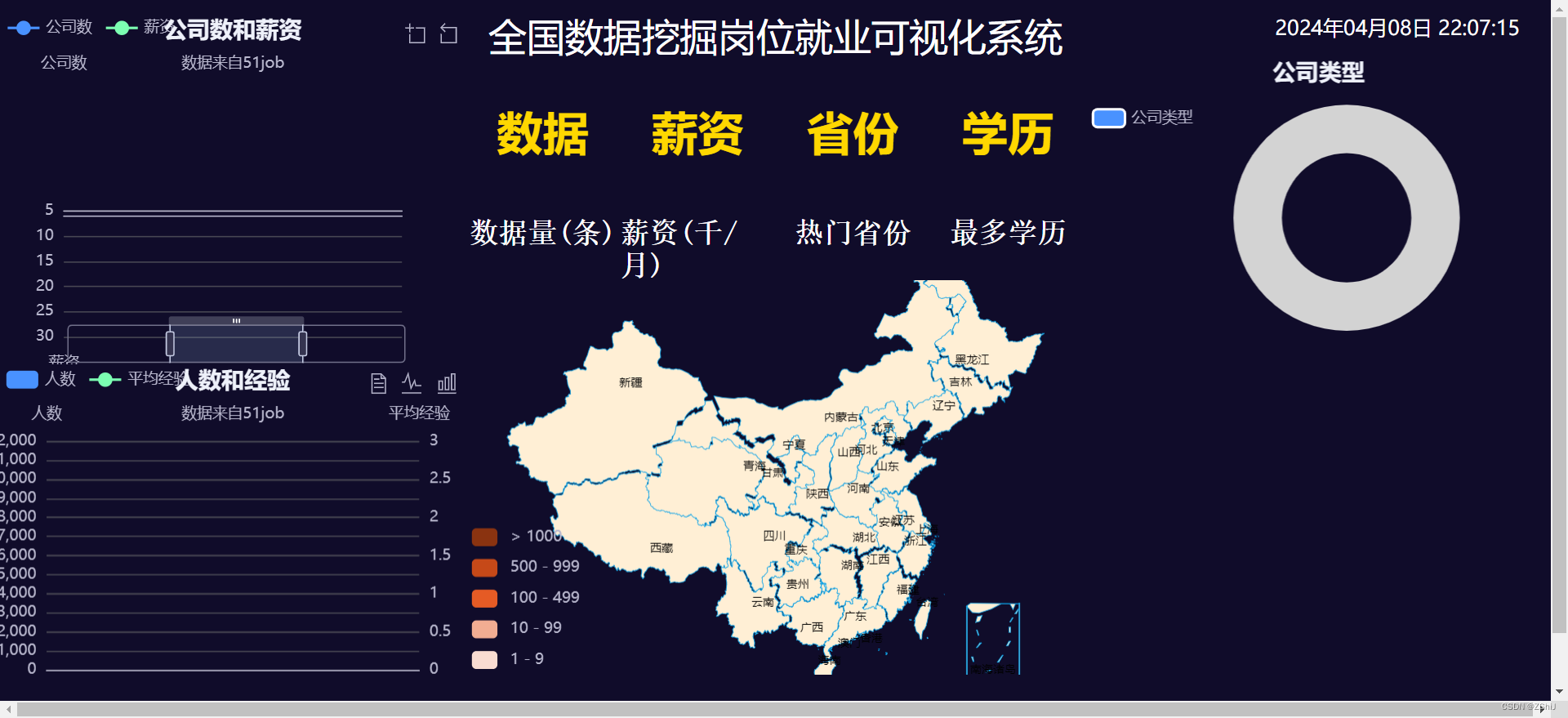
添加加数据库效果图







-
-
相关阅读:
Tomcat部署及配置
MySQL奇偶数判断
SpringMVC---请求与响应&&REST风格
vue3路由跳转时,页面如何滚动到顶部
SPark学习笔记:13 Spark Streaming 的Transform算子和Action算子
深入研究Android内存
快速构建电脑软件系统 、超好用经典的网页推荐汇总
Codeforces Round #803 (Div. 2) A. XOR Mixup
Vue中常见的loader的作用
springboot使用jackson序列化报错
- 原文地址:https://blog.csdn.net/m0_53054984/article/details/137525608
