-
springcloud - ribbon 饥饿加载
一、未饥饿加载前
我们的服务者端口是8081,消费者端口是8085
当我们将两个项目都启动的时候,在消费者里日志级别设置未debug,发现找不到8081

二、开启饥饿加载
- # 配置饥饿加载,d1为服务名
- ribbon.eager-load.enabled=true
- ribbon.eager-load.clients=d1
如果多个服务开启饥饿模式,使用逗号分隔。 clients: userservice,orderservice

三、饥饿加载的原理
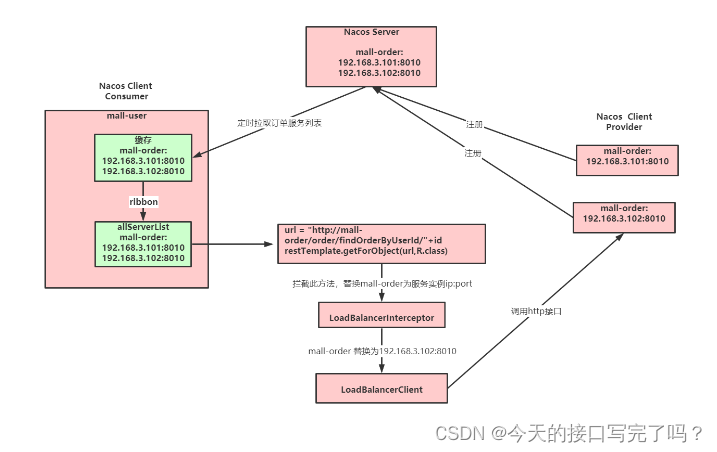
①特点:我们可以理解为一种优化策略,
-
应用启动时,Ribbon会根据配置立即向服务注册中心发起请求,获取指定服务的所有实例信息,并将其缓存起来。
② 优点:
- 减少延迟:首次调用服务时不再需要等待从服务注册中心获取实例列表的时间,提高服务调用的响应速度。
- 避免雪崩效应:特别是在服务集群规模较大或网络延迟较高的情况下,避免因首次请求时集中拉取服务列表引发的网络拥塞或超时问题。
- 提升用户体验:特别适用于对启动性能要求较高的场景,如系统启动初期就有高并发请求的情况。
③ 缺点:
- 增加资源消耗:启动时即加载所有服务实例可能导致额外的网络资源消耗,特别是当服务实例数量众多时。
- 数据实时性问题:如果服务实例的注册状态在应用启动后发生变化(比如新增、移除或状态变更),饥饿加载的数据可能不会立刻反映最新的服务列表,需要配合轮询或其他更新机制来保持数据同步。
- 注意:虽然以上描述了Ribbon的一种潜在优化策略,但在官方文档或最新版本的Spring Cloud体系中,对Ribbon的饥饿加载特性并没有明确支持。不过开发者可以根据需求自行实现类似的逻辑,以实现在应用启动时预先加载服务实例信息的目的。
-
相关阅读:
函数入门及C Primer Plus第五章编程题
C++11特性——类型推导
Spark Standalone架构及安装部署
V90伺服驱动器控制(PN版本)
uboot顶层Makefile前期所做工作说明三
zabbbix从4.0升级到5.0(服务端和客户端)
卫星地图-航拍影像-叠加配准套合(ArcGIS版)
网络安全——SQLMAP基础
调试分析Linux 0.00引导程序
夯实基础才是硬道理--拍案叫绝的计算机经典
- 原文地址:https://blog.csdn.net/qq_65142821/article/details/138160790