-
[Algorithm][前缀和][和为K的子数组][和可被K整除的子数组][连续数组][矩阵区域和]详细讲解
1.和为 K 的子数组
1.题目链接
2.算法原理详解
- 分析:因为有负数的存在
- 无法使用"双指针"优化,因为区间求和不具备单调性
- 可能已经找到前缀和为k的子数组了,但是后面仍然可能会有更长的和为k的子数组存在
- 思路:前缀和 + 哈希表
- 前缀和:以
i位置为结尾的所有的子数组- 将问题转化为:在
[0, i - 1]区间内,有多少个前缀和等于sum[i] - k - 此时,该连续区间问题就可以转化为一个前缀和问题了
- 将问题转化为:在
- 哈希表:
- 前缀和:以
- 细节处理:
- 前缀和加入哈希表的时机?
- 由于是在
[0, i - 1]区间内,找有多少个前缀和等于sum[i] - k - 所以在计算
i位置之前,哈希表里面只保存[0, i - 1]位置的前缀和
- 由于是在
- 不用真的创建一个前缀和数组
- 因为只关⼼在
i位置之前,有多少个前缀和等于sum[i] - k - 用一个变量sum来标记前一个位置的前缀和即可
- 因为只关⼼在
- 如果整个前缀和等于
k呢?hash[0] = 1- 即:默认哈希表中存在一个前缀和为0的值

- 前缀和加入哈希表的时机?
3.代码实现
int SubarraySum(vector<int>& nums, int k) { unordered_map<int, int> hash; // <前缀和, 次数> hash[0] = 1; int ret = 0, sum = 0; // 标识前一个位置的前缀和 for(auto& e : nums) { sum += e; // 计算当前位置的前缀和 if(hash.count(sum - k)) { ret += hash[sum - k]; } hash[sum]++; // 将i位置的前缀和入hash } return ret; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.和可被 K 整除的子数组
1.题目链接
2.算法原理详解
- 前置知识:
- 同余定理:
(a - b) / p = k->a % p == b % p - C++
[
负数
%
正数
]
[负数 \% 正数]
[负数%正数]的结果及修正
- 结果:
[
负数
%
正数
]
[负数 \% 正数]
[负数%正数] -> 负数
- 尽可能让商,进行向0取整
- 修正:
a % p + p - 正负统一:
(a % p + p) % p
- 结果:
[
负数
%
正数
]
[负数 \% 正数]
[负数%正数] -> 负数
- 同余定理:
- 分析:因为有负数的存在
- 无法使用"双指针"优化,因为区间求和不具备单调性
- 可能已经找到前缀和可以被k整除的子数组了,但是后面仍然可能会有更长的前缀和可以被k整除的子数组存在
- 思路:前缀和 + 哈希表
- 前缀和:以
i位置为结尾的所有的子数组- 将问题转化为:在
[0, i - 1]区间内,有多少个前缀和的余数等于(sum % k + k) % k - 此时,该连续区间问题就可以转化为一个前缀和问题了
- 将问题转化为:在
- 哈希表:
- 前缀和:以
- 细节处理:
- 前缀和加入哈希表的时机?
- 由于是在
[0, i - 1]区间内,找有多少个前缀和的余数等于(sum % k + k) % k - 所以在计算
i位置之前,哈希表里面只保存[0, i - 1]位置的前缀和的余数
- 由于是在
- 不用真的创建一个前缀和数组
- 因为只关⼼在
i位置之前,有多少个前缀和的余数等于(sum % k + k) % k - 用一个变量sum来标记前一个位置的前缀和即可
- 因为只关⼼在
- 如果整个前缀和等于
k呢?hash[0] = 1- 即:默认哈希表中存在一个前缀和余数为0的值

- 前缀和加入哈希表的时机?
3.代码实现
int subarraysDivByK(vector<int>& nums, int k) { unordered_map<int, int> hash;// <前缀和余数, 次数> hash[0] = 1; int sum = 0, ret = 0; // 用于标记前一个位置的前缀和 for(auto& e : nums) { sum += e; // 计算当前位置的前缀和 int tmp = (sum % k + k) % k; // 修正后的余数 if(hash.count(tmp)) { ret += hash[tmp]; } hash[tmp]++; // 将i位置的前缀和的余数入hash } return ret; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
3.连续数组
1.题目链接
2.算法原理详解
-
问题转化:
- 将所有的 0 0 0修改成 − 1 -1 −1
- 在数组中,找出最长的子数组,使子数组中所有元素的和为0
-
[和为k的子数组] -> [和为0的子数组]
-
思路:前缀和 + 哈希表
- 前缀和:以
i位置为结尾的所有的子数组- 将问题转化为:在
[0, i - 1]区间内,有多少个前缀和等于sum - 此时,该连续区间问题就可以转化为一个前缀和问题了
- 将问题转化为:在
- 哈希表:

- 前缀和:以
-
细节处理:
- 前缀和加入哈希表的时机?`
- 在计算
i位置之前,哈希表里面只保存[0, i - 1]位置的前缀和 - 所以,使用完之后,丢进哈希表
- 在计算
- 如果哈希表中有重复的
(sum, i),如何存?- 因为要找最长的子数组
- 所以只需要保留前面的那一对
(sum, i)即可
- 不用真的创建一个前缀和数组
- 因为只关⼼在
i位置之前,有多少个前缀和等于sum - 用一个变量sum来标记前一个位置的前缀和即可
- 因为只关⼼在
- 默认的前缀和为0的情况,如何存?
hash[0] = -1
- 长度怎么算?
i - j

- 前缀和加入哈希表的时机?`
3.代码实现
int FindMaxLength(vector<int>& nums) { unordered_map<int, int> hash; // <前缀和, 下标> hash[0] = -1; // 默认有一个前缀和为0的情况 int sum = 0, len = 0; // 标记前一次的前缀和 for(int i = 0; i < nums.size(); i++) { sum += nums[i] == 0 ? -1 : 1; if(hash.count(sum)) { len = max(len, i - hash[sum]); // 更新最大长度 } else { hash[sum] = i; // 将(sum, i)入hash } } return len; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
4.矩阵区域和
1.题目链接
2.算法原理详解
-
该题就是对**[二维前缀和]**的一个实际应用
-
左上角/右上角坐标可能会越界
- 左上角:
- x 1 = m a x ( 0 , i − k ) + 1 x_1 = max(0, i - k) + 1 x1=max(0,i−k)+1
- y 1 = m a x ( 0 , j − k ) + 1 y_1 = max(0, j - k) + 1 y1=max(0,j−k)+1
- 右下角:
- x 2 = m i n ( m − 1 , i + k ) + 1 x_2 = min(m - 1, i + k) + 1 x2=min(m−1,i+k)+1
-
y
2
=
m
i
n
(
n
−
1
,
j
+
k
)
+
1
y_2 = min(n - 1, j + k) + 1
y2=min(n−1,j+k)+1

- 左上角:
-
下标的映射关系:
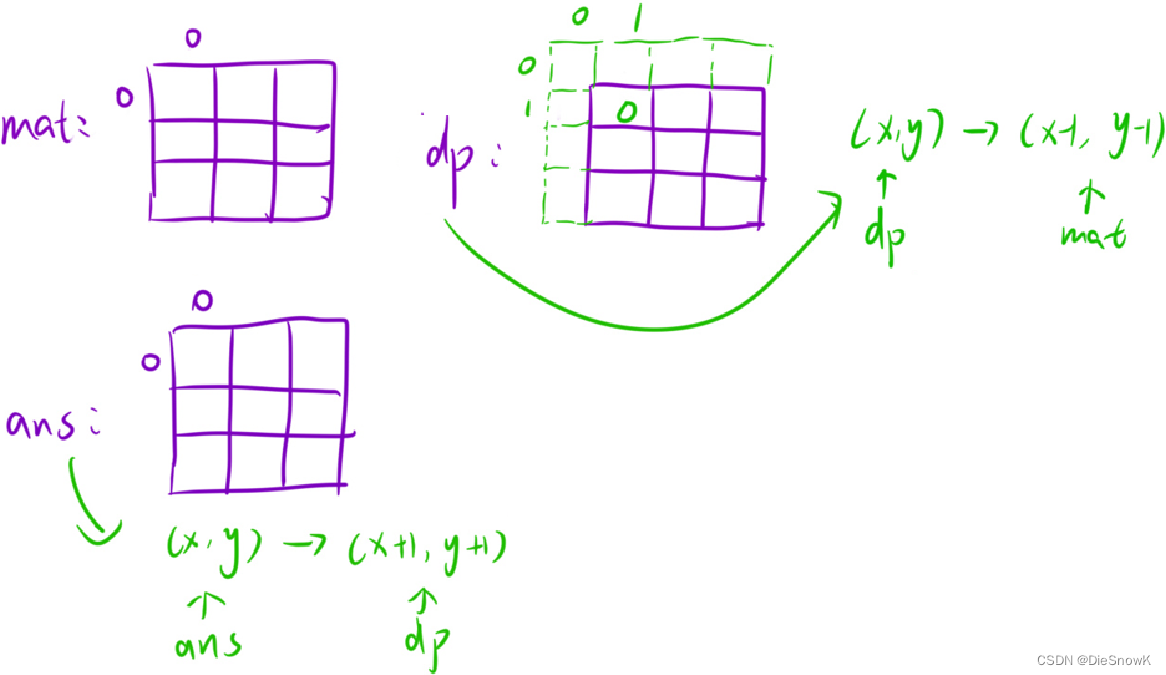
3.代码实现
vector<vector<int>> MatrixBlockSum(vector<vector<int>>& mat, int k) { int row = mat.size(), col = mat[0].size(); // 预处理前缀和数组 vector<vector<int>> dp(row + 1, vector<int>(col + 1)); for(int i = 1; i <= row; i++) { for(int j = 1; j <= col; j++) { // 下标映射关系 dp[x, y] -> mat[x - 1][y - 1] dp[i][j] = dp[i - 1][j] + dp[i][j - 1] \ - dp[i - 1][j - 1] + mat[i - 1][j - 1]; } } // 使用前缀和数组 vector<vector<int>> ret(row, vector<int>(col)); for(int i = 0; i < row; i++) { for(int j = 0; j < col; j++) { // 下标映射关系 ret[x][y] -> dp[x + 1][y + 1] int x1 = max(0, i - k) + 1; int y1 = max(0, j - k) + 1; int x2 = min(row - 1, i + k) + 1; int y2 = min(col - 1, j + k) + 1; ret[i][j] = dp[x2][y2] - dp[x1 - 1][y2] \ - dp[x2][y1 - 1] + dp[x1 - 1][y1 - 1]; } } return ret; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 分析:因为有负数的存在
-
相关阅读:
Feign的使用
TiUP Cluster
【Linux】:Linux环境与版本
线程池——futuretask、CompletionService、CompletableFuture
Linux 使用ss命令停止指定端口进程
概率图模型在机器学习中的应用:贝叶斯网络与马尔可夫随机场
Redis在中国火爆,为何MongoDB更受欢迎国外?
代码随想录算法训练营第23期day11 | 20. 有效的括号、1047. 删除字符串中的所有相邻重复项 、150. 逆波兰表达式求值
微信小程序canvas 证件照制作
WebRTC创建客户端
- 原文地址:https://blog.csdn.net/qq_37281656/article/details/138172409
