-
[MYSQL索引优化] 分页查询优化
这里一共介绍两种常见的分页索引优化技巧,let go!
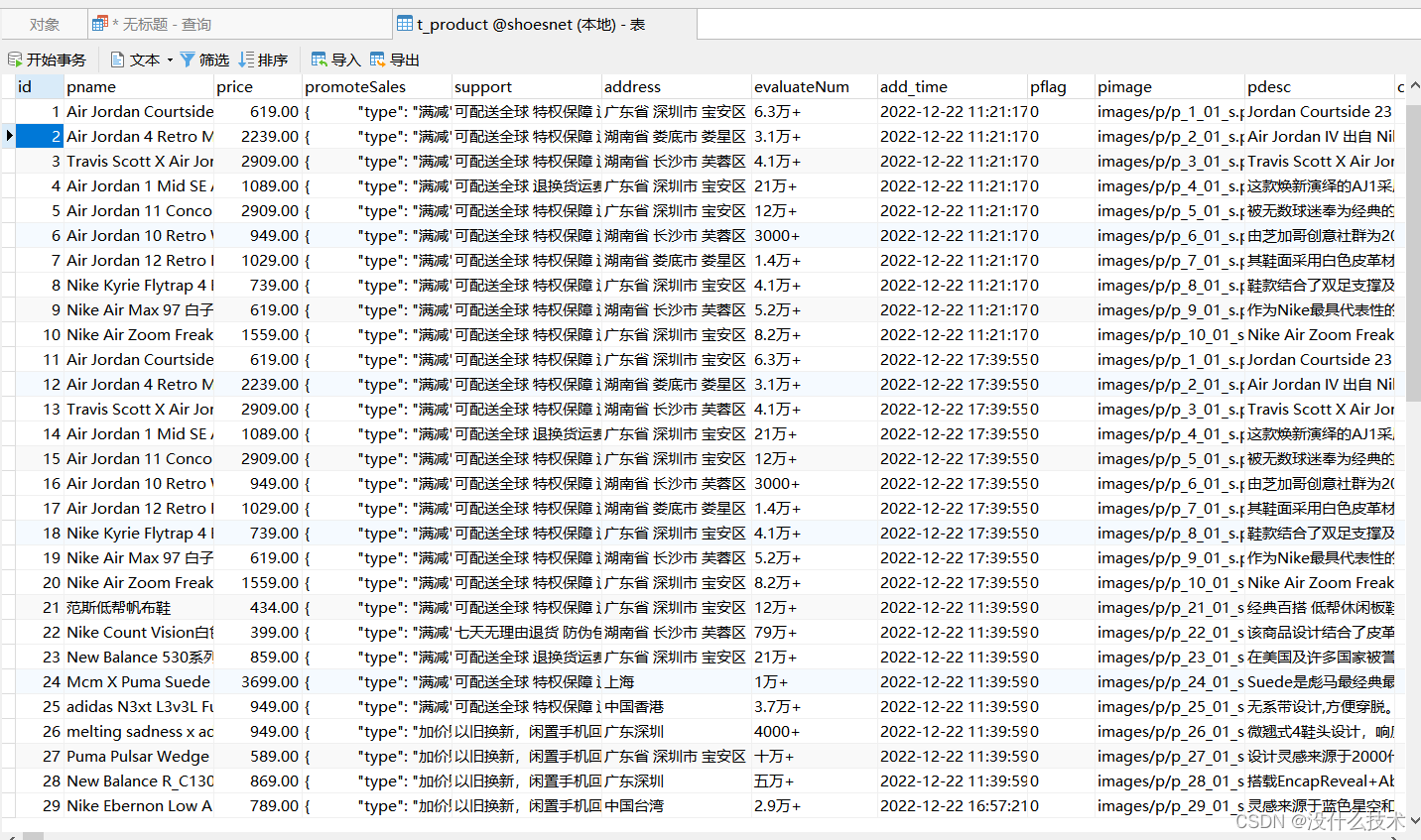
示例表:
- CREATE TABLE `t_product` (
- `id` int(0) NOT NULL,
- `pname` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
- `price` double(7, 2) NULL DEFAULT 0.00,
- `promoteSales` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '商品促销类别',
- `support` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
- `address` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
- `evaluateNum` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '评论数',
- `add_time` timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0),
- `pflag` enum('0','1') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT '0' COMMENT '0 上架 1 下架',
- `pimage` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
- `pdesc` varchar(400) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
- `cid` int(0) NULL DEFAULT NULL,
- PRIMARY KEY (`id`) USING BTREE
- ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
- //对价格建立普通索引
- CREATE INDEX idx_price ON t_product(price);
1、根据自增且连续的主键排序的分页查询
首先来看一个根据自增且连续主键排序的分页查询的例子:

因为没添加单独 order by,表示通过主键排序,我们这里给出的优化语句是:
select * from t_product where id > 30 limit 5;改写成按照主键去查询从第 30开始的五行数据。
我们看看这么改的原因:

首先他们的查询结果是相同的,但是他们的执行计划却大相径庭!
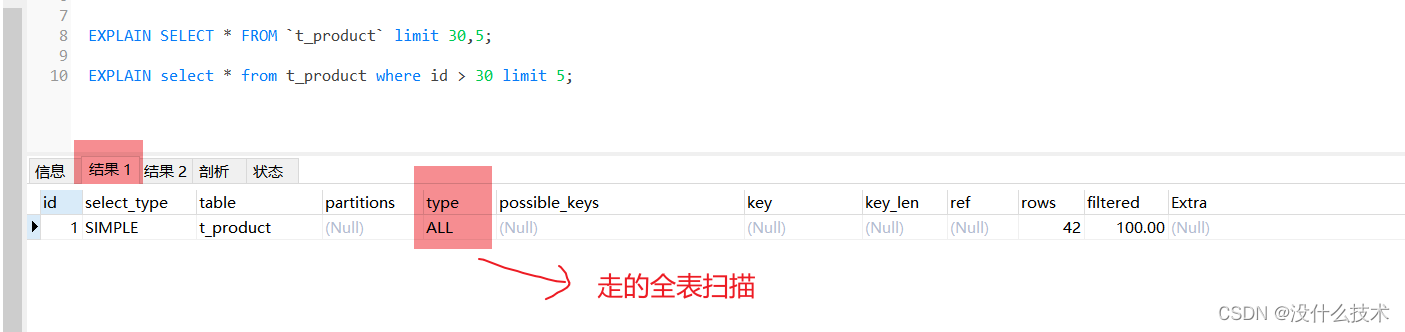

显然改写后的 SQL 走了索引,而且扫描的行数大大减少,执行效率更高。
但是有一条,这条改写的SQL 在很多场景并不实用,因为表中可能某些记录被删后,主键空缺,导致结果不一致,如下图试验所示(先删除一条前面的记录,然后再测试原 SQL 和优化后的 SQL):


故给出的建议是 慎用,一定要注意满足要求,自增且连续的主键排序
2、根据非主键字段排序的分页查询
例如:
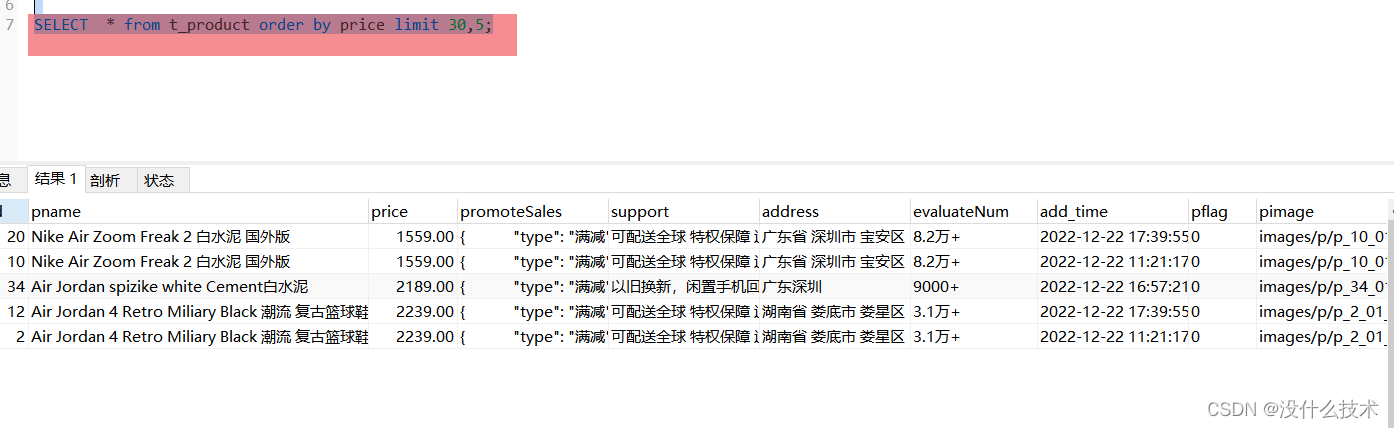
再来看看它的执行计划:

可以看到走的全表扫描,这里可能有人会有疑惑,我不是给price建立的普通索引嘛,为什么order by没用上??其实这是因为我们mysql底层的优化器认为查整个记录,每做一次二级索引的话都需要进行回表不如直接走全表扫描去遍历整个记录的性能来的高。
我们可以进行验证:
例如,我这里如果只查询id,price,我们看看它的执行计划

神奇的事情发生了,明明一样的查询条件执行计划却差这么大!
那知道不走索引的原因,那么怎么优化呢?
实关键是让排序时返回的字段尽可能少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录,SQL改写如下


这样一来,我们只有最外层的没有走到索引,但是没关系啊,子查询语句总共就只查询出来了5条记录,全表扫描也就五条记录,最耗时间的排序哪里我们使用了二级索引和eq_ref,效率是很高的。
这样就完美解决问题了,并且执行时间减少了一半以上。
ps:如果这里不太明白explain用法的可以去看看我之前发的一个简单的explain入门
-
相关阅读:
Sobel算子详解及例程
vue3组合式api的函数系列一
MongoDB快速上手
Kotlin 协程(线程)切换
php实战案例记录(6)伪静态设置
【OpenGL ES】渲染管线
【YoloDeployCsharp】基于.NET Framework的YOLO深度学习模型部署测试平台
武汉新时标文化传媒有限公司抖音小店提高价格的商品还有人买吗?
can中继 智能CAN总线隔离中继器集线器CANBridge-300/400
【MySQL】BIT_OR函数在二进制分组group by中的妙用
- 原文地址:https://blog.csdn.net/qq_62775328/article/details/138169955