-
爬虫实战(维基xx)
实战网页链接:https://www.britannica.com/topic/Wikipedia
我们可以看见网页文本上有超链接,我们可以在源码看见它们的代码:
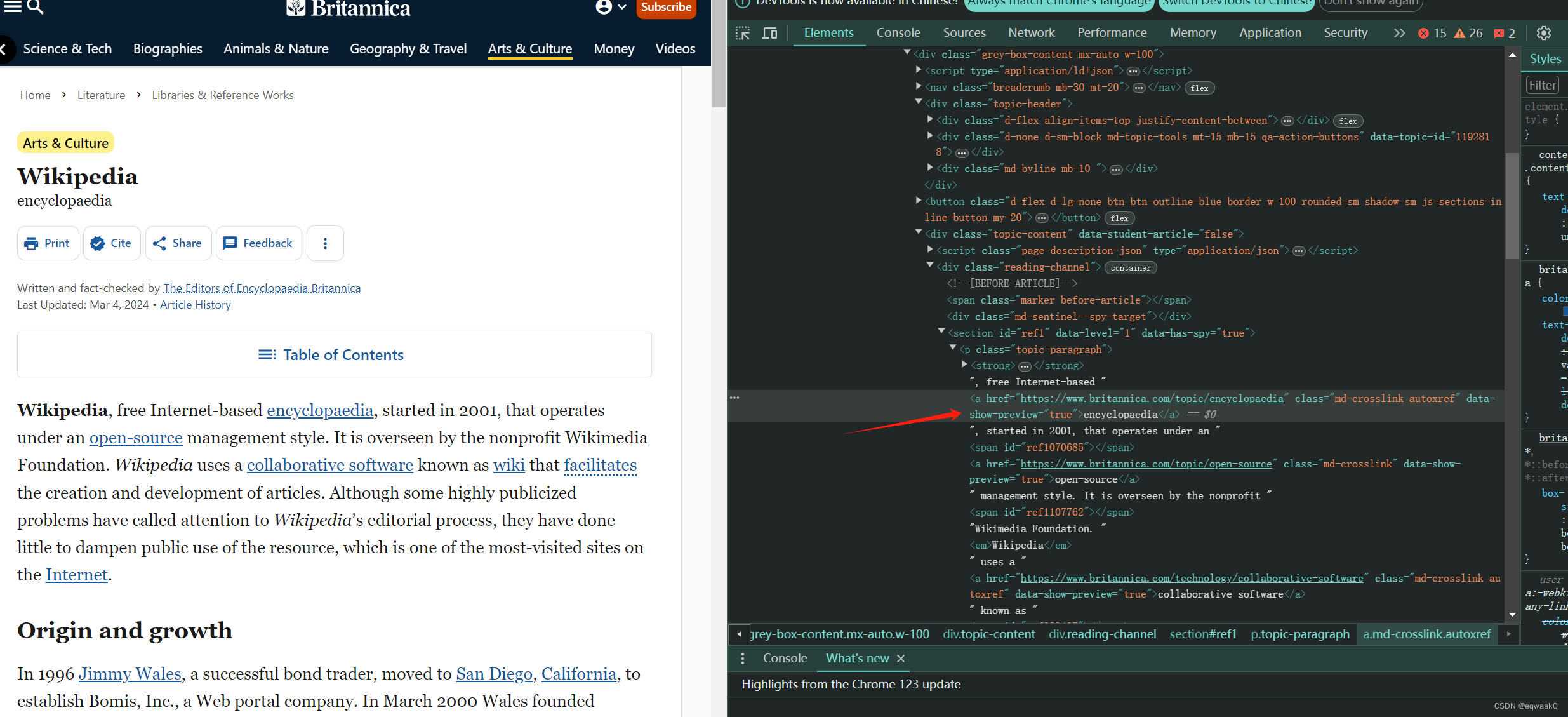
我们开始写出简单的爬取,把它的链接全部拿取出来:
- import requests
- from bs4 import BeautifulSoup
- #https://www.britannica.com/topic/Wikipedia
- headers = {
- 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
- 'Cookie': '__cf_bm=tib6ICsQJxwj9fpQPz8vhpKt84n0pXOPK6DvV8P8vc4-1713585206-1.0.1.1-3MKOfelDBDRh.z5WLq1ddVtPSuJQ69Ewh9v4Wc.Ljkw9I_G3nUUNOw3W8AG_hXTrF_PojWo.D7_8N4Zn6UGGbw; __mendel=%7B%27pagesViewed%27%3A1%2C%27surveyShown%27%3Afalse%2C%27topicInitialSequence%27%3A0%7D; subreturn=https%3A%2F%2Fwww.britannica.com%2Ferror404; webstats=referer_page=https%3A%2F%2Fwww.britannica.com%2Ferror404'
- }
- r=requests.get("https://www.britannica.com/topic/Wikipedia")
- html=r.text
- bsObj=BeautifulSoup(html)
- for link in bsObj.findAll("a"):
- if "href" in link.attrs:
- print(link.attrs['href'])
如下:(为爬取成功)
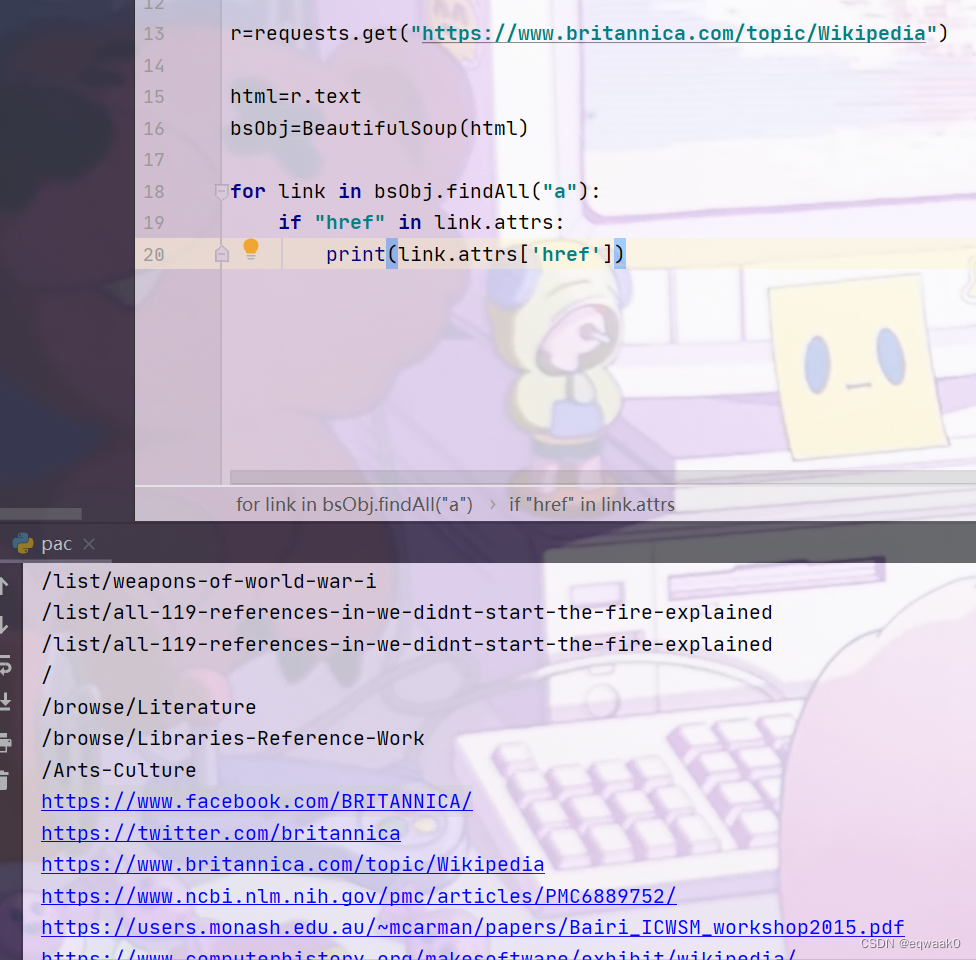
但是我们可以发现有一些是我们不需要的,还有一些URL是重复的,如文章链接,页眉,页脚......
1.URL链接不包括#、=、<、>。
2.URL链接是以/wiki/开头的。
深度优先的递归爬虫:
如下:
- import requests
- from bs4 import BeautifulSoup
- import re
- import time
- #https://www.britannica.com/topic/Wikipedia
- exist_url=[]#放url
- g_writecount=0
- def scrappy(url,depth=1):
- global g_writecount
- try:
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
- 'Cookie': '__cf_bm=tib6ICsQJxwj9fpQPz8vhpKt84n0pXOPK6DvV8P8vc4-1713585206-1.0.1.1-3MKOfelDBDRh.z5WLq1ddVtPSuJQ69Ewh9v4Wc.Ljkw9I_G3nUUNOw3W8AG_hXTrF_PojWo.D7_8N4Zn6UGGbw; __mendel=%7B%27pagesViewed%27%3A1%2C%27surveyShown%27%3Afalse%2C%27topicInitialSequence%27%3A0%7D; subreturn=https%3A%2F%2Fwww.britannica.com%2Ferror404; webstats=referer_page=https%3A%2F%2Fwww.britannica.com%2Ferror404'
- }
- url='https://www.britannica.com/topic/Wikipedia'+url
- r=requests.get(url,headers=headers)
- html=r.text
- except Exception as e:
- print('saveing',url)
- print(e)
- exist_url.append(url)
- return None
- exist_url.append(url)
- link_list=re.findall('',html)
- #去重复url
- unique_list=list(set(link_list)-set(exist_url))
- #放到txt文件里面
- for eachone in unique_list:
- g_writecount+=1
- output="NO."+str(g_writecount)+"\t Depth"+str(depth)+"\t"+url+'->'+eachone+'\n'
- print(output)
- with open('link_eqwaak.txt',"a+") as f:
- f.write(output)
- if depth<2:
- scrappy(eachone,depth+1)
- scrappy("wiki")
url放入link_eqwaak.txt文件里面,直到深度大于或等于2.
下一节我们实现多线程网页爬取,提高代码的执行速度。
-
相关阅读:
K8S-存储(ConfigMap、Secret、Volume、PVC/PV)
TensorFlow深度学习!构建神经网络预测股票价格!⛵
TCP/IP 七层架构模型
都说Dapper性能好,突然就遇到个坑,还是个性能问题
手机浏览器风生水起,多御安全浏览器手机版升级上线
软件测试人员必须知道的接口测试基础
多团队协同开发的18条实践
Spring Cloud Gateway从数据库读取并更新Cors配置
Redis学习笔记-跳跃表
LeetCode——动态规划篇(六)
- 原文地址:https://blog.csdn.net/eqwaak0/article/details/137995104
