-
Elasticsearch从入门到精通-05ES匹配查询
Elasticsearch从入门到精通-05ES匹配查询
👏作者简介:大家好,我是程序员行走的鱼
📖 本篇主要介绍和大家一块学习一下ES各种场景下的匹配查询,有助于我们在项目中进行综合使用
前提
创建索引并指定ik分词器:
PUT /es_db { "settings": { "index": { "analysis.analyzer.default.type": "ik_max_word" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
添加数据:
PUT /es_db/_doc/1 { "name": "张三", "sex": 1, "age": 25, "address": "广州天河公园", "remark": "java developer" } PUT /es_db/_doc/2 { "name": "李四", "sex": 1, "age": 28, "address": "广州荔湾大厦", "remark": "java assistant" } PUT /es_db/_doc/3 { "name": "rod", "sex": 0, "age": 26, "address": "广州白云山公园", "remark": "php developer" } PUT /es_db/_doc/4 { "name": "admin", "sex": 0, "age": 22, "address": "长沙橘子洲头", "remark": "python assistant" } PUT /es_db/_doc/5 { "name": "小明", "sex": 0, "age": 19, "address": "长沙岳麓山", "remark": "java architect assistant" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
案例1:字段包含关键词中几个
需要搜索的document中的remark字段包含java和developer词组
operator实现
GET /es_db/_search { "query": { "match": { "remark": { "query": "java developer", "operator": "and" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

上述语法中,如果将operator的值改为or。则与remark": "java developer"等价 。默认的ES执行搜索的时候,operator就是or。如果在搜索的结果document中,需要remark字段中包含多个搜索词条中的一定比例,可以使用下述语法实现搜索。其中minimum_should_match可以使用百分比或固定数字。百分比代表query搜索条件中词条百分比,如果无法整除,向下匹配(如,query条件有3个单词,如果使用百分比提供精准度计算,那么是无法除尽的,如果需要至少匹配两个单词,则需要用67%来进行描述。如果使用66%描述,ES则认为匹配一个单词即可。)。固定数字代表query搜索条件中的词条,至少需要匹配多少个。
minimum_should_match实现
完全匹配上:
GET /es_db/_search { "query": { "match": { "remark": { "query": "java architect assistant", "minimum_should_match": "100%" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

至少匹配两个:
GET /es_db/_search { "query": { "match": { "remark": { "query": "java architect assistant", "minimum_should_match": "68%" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

bool+should实现
如果使用should+bool搜索的话,也可以控制搜索条件的匹配度。具体如下:下述案例代表搜索的document中的remark字段中,必须匹配java、developer、assistant三个词条中的至少2个。
GET /es_db/_search { "query": { "bool": { "should": [ { "match": { "remark": "java" } }, { "match": { "remark": "developer" } }, { "match": { "remark": "assistant" } } ], "minimum_should_match": 2 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

match的底层转换
其实在ES中,执行match搜索的时候,ES底层通常都会对搜索条件进行底层转换,来实现最终的搜索结果。如:
1.GET /es_db/_search { "query": { "match": { "remark": "java developer" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
转化后:
//转换后是: GET /es_db/_search { "query": { "bool": { "should": [ { "term": { "remark": "java" } }, { "term": { "remark": { "value": "developer" } } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
GET /es_db/_search { "query": { "match": { "remark": { "query": "java developer", "operator": "and" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
转换后:
GET /es_db/_search { "query": { "bool": { "must": [ { "term": { "remark": "java" } }, { "term": { "remark": { "value": "developer" } } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
GET /es_db/_search { "query": { "match": { "remark": { "query": "java architect assistant", "minimum_should_match": "68%" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
转换后:
GET /es_db/_search { "query": { "bool": { "should": [ { "term": { "remark": "java" } }, { "term": { "remark": "architect" } }, { "term": { "remark": "assistant" } } ], "minimum_should_match": 2 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
建议,如果不怕麻烦,尽量使用转换后的语法执行搜索,效率更高。如果开发周期短,工作量大,使用简化的写法。
案例2:boost权重控制
一般用于搜索时相关度排序使用。如:电商中的综合排序。将一个商品的销量,广告投放,评价值,库存,单价比较综合排序。在上述的排序元素中,广告投放权重最高,库存权重最低,这样权重越大的排序越考前,我们以一下例子为例来详细学习权重的作用。
搜索document中remark字段中包含java的数据,如果remark中包含developer或architect,则包含architect的document优先显示。(就是将architect数据匹配时的相关度分数增加)。
GET /es_db/_search { "query": { "bool": { "must": [ { "match": { "remark": "java" } } ], "should": [ { "match": { "remark": { "query": "developer", "boost": 1 } } }, { "match": { "remark": { "query": "architect", "boost": 3 } } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32

在搜索所有remark包含java文档中,我们设置包含architect的权重比包含developer权重大,所以排序后会出现以上的结果,如果我们把developer权重调为比architect权重大,那么developer的排序会比architect高

案例3:基于dis_max实现best fields策略进行多字段搜索
best fields策略: 搜索到的结果,应该是某一个field中匹配到了尽可能多的关键词,被排在前面;而不是尽可能多的field匹配到了少数的关键词,排在了前面.
dis_max语法:直接取多个query中,分数最高的那一个query的分数即可,下边以案例解释这句话的意思
数据准备
PUT /forum { "settings" : { "number_of_shards" : 1 }} POST /forum/article/_bulk {"index":{"_id":1}} {"title":"this is java and elasticsearch blog","content":"i like to write best elasticsearch article"} {"index":{"_id":2}} {"title":"this is java blog","content":"i think java is the best programming language"} {"index":{"_id":3}} {"title":"this is elasticsearch blog","content":"i am only an elasticsearch beginner"} {"index":{"_id":4}} {"title":"this is java, elasticsearch, hadoop blog","content":"elasticsearch and hadoop are all very good solution, i am a beginner"} {"index":{"_id":5}} {"title":"this is spark blog","content":"spark is best big data solution based on scala ,an programming language similar to java"}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
普通DSL:
GET /forum/article/_search { "query": { "bool": { "should": [ { "match": { "title": "java solution" } }, { "match": { "content": "java solution" } } ], "minimum_should_match": 1 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

来分析一下结果
计算每个document的relevance score:每个query的分数,乘以matched query数量,除以总query数量

算一下doc2的分数:
{ “match”: { “title”: “java solution” }}:针对文档2,java匹配上了,可以得到一个分数 1.1
{ “match”: { “content”: “java solution” }}:针对文档2,java匹配上了,可以得到一个分数 1.2
假设分数如下 , 所以是两个分数加起来,比如说,1.1 + 1.2 = 2.3
matched query数量 = 2
总query数量 = 2
2.3 * 2 / 2 = 2.3 当前文档获取分数就是2.1
算一下doc5的分数

{ “match”: { “title”: “java solution” }}:针对文档5,没有关键字匹配,所以没有分数
{ “match”: { “content”: “java solution” }}:针对文档5,java匹配上了,可以得到一个分数2.3
所以说,只有一个query是有分数的,比如2.3 matched query数量 = 1 总query数量 = 2
2.3 * 1 / 2 = 1.15
doc5的分数 = 1.15 < doc2的分数 = 2.3
id=2的数据排在了前面,其实我们希望id=5的排在前面,毕竟id=5的数据 content字段既有java又有solution. 那看下dis_max吧

我们再来计算下两个文档的分数:
{ “match”: { “title”: “java solution” }}:针对文档2,java匹配上了,可以得到一个分数1.1
{ “match”: { “content”: “java solution” }}:针对文档2,java匹配上了,可以得到一个分数1.2
取最大分数,1.2
{ “match”: { “title”: “java solution” }}:针对文档2,java匹配上了,可以得到一个分数0
{ “match”: { “content”: “java solution” }}:针对文档2,java匹配上了,可以得到一个分数2.3
取最大分数,2.3
然后doc2的分数 = 1.2 < doc5的分数 = 2.3,所以doc5就可以排在更前面的地方.
dis_max优点:精确匹配的数据可以尽可能的排列在最前端,且可以通过minimum_should_match来去除长尾数据,避免长尾数据字段对排序结果的影响
长尾数据比如说我们搜索4个关键词,但很多文档只匹配1个,也显示出来了,这些文档其实不是我们想要的,这时候我们就需要对dis_max改进一下:
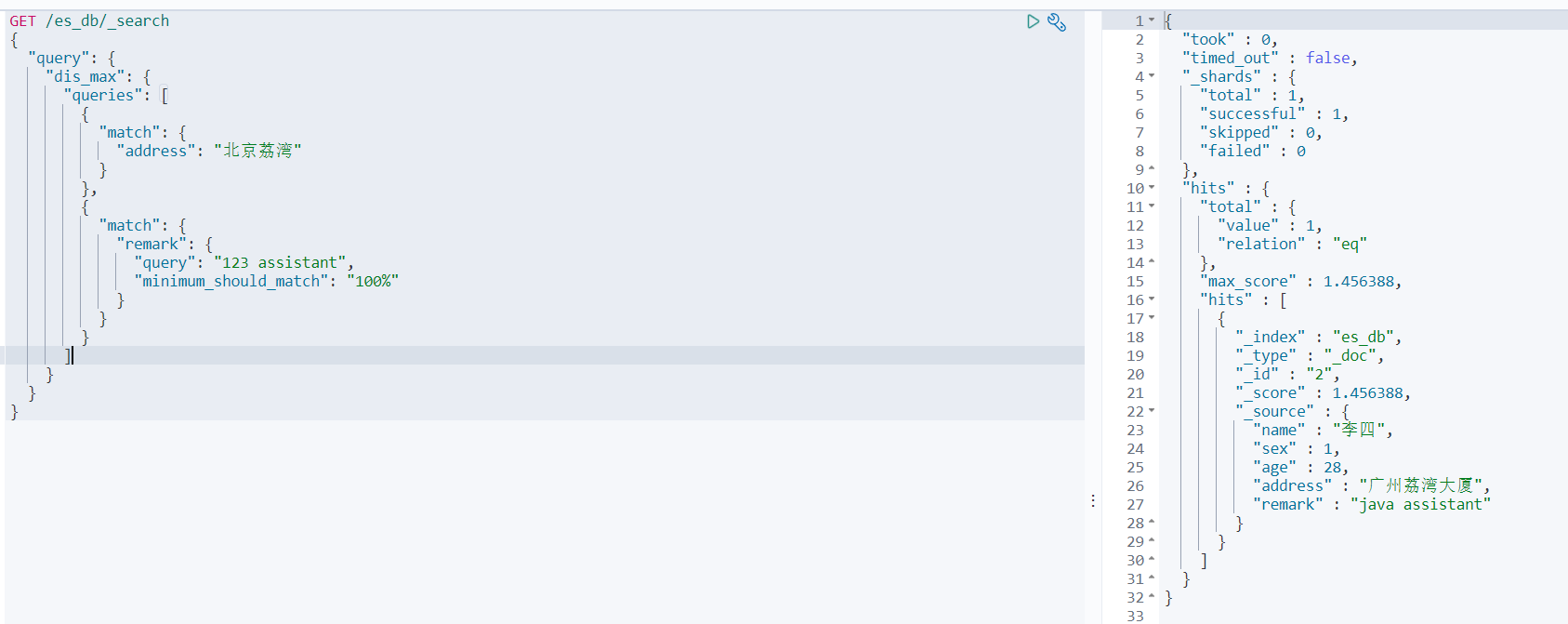
比如我们查询content中必须包含java solution的文档
GET /forum/article/_search { "query": { "dis_max": { "queries": [ { "match": { "title": "java solution" } }, { "match": { "content": { "query": "java solution", "minimum_should_match": "100%" } } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
案例4:基于tie_breaker参数优化dis_max搜索效果
dis_max是将多个搜索query条件中相关度分数最高的用于结果排序,忽略其他query分数,在某些情况下,可能还需要其他query条件中的相关度介入最终的结果排序,这个时候可以使用tie_breaker参数来优化dis_max搜索。tie_breaker参数代表的含义是:将其他query搜索条件的相关度分数乘以参数值,再参与到结果排序中。如果不定义此参数,相当于参数值为0。所以其他query条件的相关度分数被忽略。
GET /forum/article/_search { "query": { "dis_max": { "queries": [ { "match": { "title": "java beginner" } }, { "match": { "content":"java beginner"} } ], "tie_breaker": 0.5 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
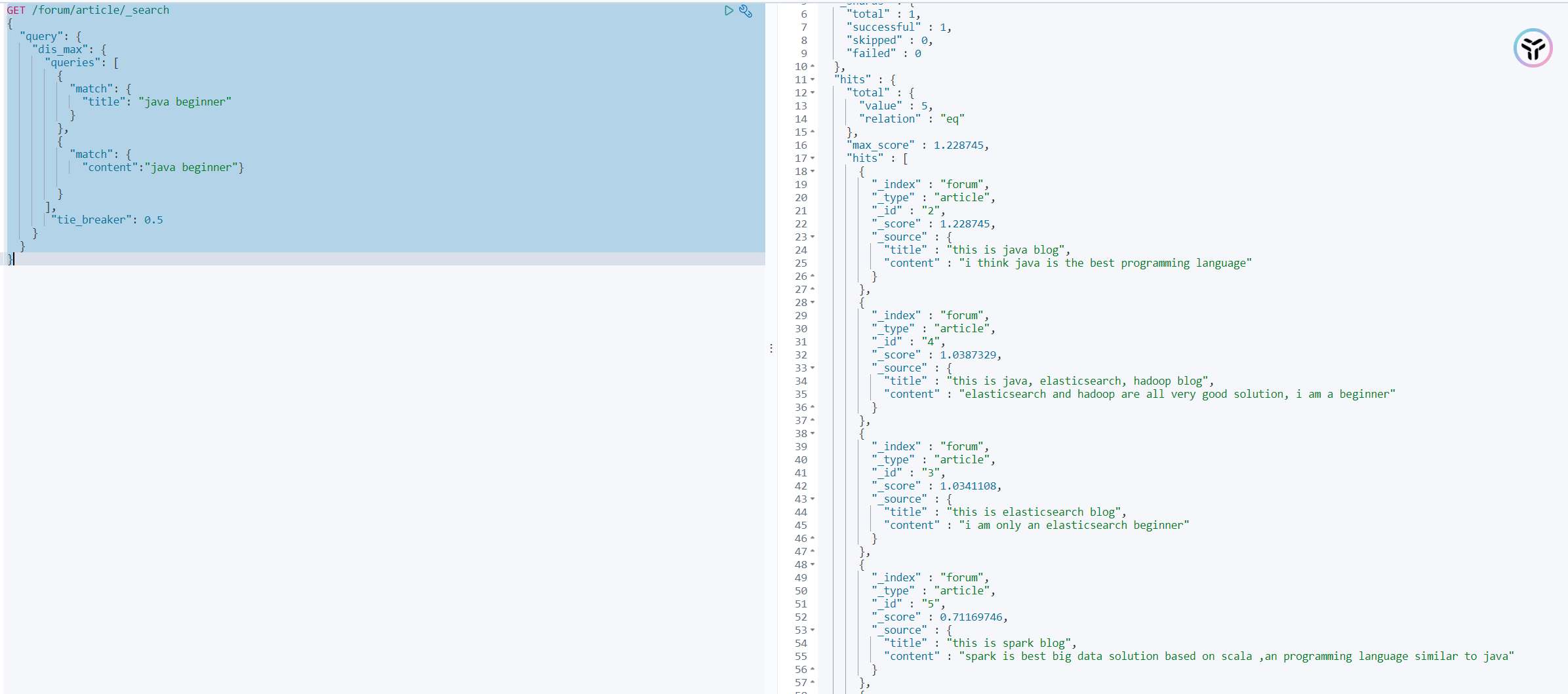
可以明显看出来,文档5直接排序来到了最后一位,因为其他query也参与了计算,综合算起来是score是低于其他文档的。
案例5:使用multi_match简化dis_max+tie_breaker
GET /forum/article/_search { "query": { "multi_match": { "query": "best java solution", "fields": [ "title", "content^2"#^n代表权重,说明如果content匹配到多个关键字的话权重高一点。 ], "type": "best_fields", "tie_breaker": 0.5, "minimum_should_match": "50%" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

如果需要的结果是有特殊要求,如:hello world必须是一个完整的短语,不可分割;或document中的field内,包含的hello和world单词,且两个单词之间离的越近,相关度分数越高。那么这种特殊要求的搜索就是近似搜索。包括hell搜索条件在hello world数据中搜索,包括h搜索提示等都数据近似搜索的一部分。下边的案例都是近似匹配的情况
案例6:短语搜索
短语搜索。就是搜索条件不分词,代表搜索条件不可分割。如果java assistant是一个不可分割的短语,我们可以使用前文学过的短语搜索match phrase来实现。语法如下:
GET _search { "query": { "match_phrase": { "remark": "java assistant" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

ES是如何实现match phrase短语搜索的?其实在ES中,使用match phrase做搜索的时候,也是和match类似,首先对搜索条件进行分词-analyze。将搜索条件拆分成java和assistant。既然是分词后再搜索,ES是如何实现短语搜索的?
这里涉及到了倒排索引的建立过程。在倒排索引建立的时候,ES会先对document数据进行分词,如:

从上述结果中,可以看到。ES在做分词的时候,除了将数据切分外,还会保留一个position。position代表的是这个词在整个数据中的下标。当ES执行match phrase搜索的时候,首先将搜索条件hello world分词为hello和world。然后在倒排索引中检索数据,如果hello和world都在某个document的某个field出现时,那么检查这两个匹配到的单词的position是否是连续的,如果是连续的,代表匹配成功,如果是不连续的,则匹配失败。
案例7:match phrase优化
在做搜索的时候,如果搜索参数是hello spark。而ES中存储的数据是hello world, java spark。那么使用match phrase则无法搜索到。在这个时候,可以使用match来解决这个问题。但是,当我们需要在搜索的结果中,做一个特殊的要求:hello和spark两个单词距离越近,document在结果集合中排序越靠前,这个时候再使用match则未必能得到想要的结果.针对这种情况,在ES的搜索中,对match phrase提供了参数slop。slop代表match phrase短语搜索的时候,单词最多移动多少次,可以实现数据匹配。在所有匹配结果中,多个单词距离越近,相关度评分越高,排序越靠前。这种使用slop参数的match phrase搜索,就称为近似匹配(proximity search)
举例:
数据为:hello world, java spark
搜索为:match phrase : hello spark。
slop为: 3 (代表单词最多移动3次。)
执行短语搜索的时候,将条件hello spark分词为hello和spark两个单词。并且连续。
接下来,可以根据slop参数执行单词的移动。
下标 : 0 1 2 3
doc : hello world java spark
搜索 : hello spark
移动1: hello spark
移动2: hello spark
匹配成功,不需要移动第三次即可匹配。
再如:
数据为: hello world, java spark
搜索为: match phrase : spark hello。
slop为: 5 (代表单词最多移动5次。)
执行短语搜索的时候,将条件hello spark分词为hello和spark两个单词。并且连续。
接下来,可以根据slop参数执行单词的移动。
下标 : 0 1 2 3
doc : hello world java spark
搜索 : spark hello
移动1: spark/hello
移动2: hello spark
移动3: hello spark
移动4: hello spark
匹配成功,不需要移动第五次即可匹配。
如果当slop移动次数使用完毕,还没有匹配成功,则无搜索结果。如果使用中文分词,则移动次数更加复杂,因为中文词语有重叠情况,很难计算具体次数,需要多次尝试才行。
英语测试:

GET _analyze { "text": "hello world, java spark", "analyzer": "standard" } POST /test_a/_doc/3 { "f": "hello world, java spark" } GET /test_a/_search { "query": { "match_phrase": { "f": { "query": "hello spark", "slop": 2 } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
中文测试:
DELETE /test_a GET _analyze { "text": "中国,一个世界上最强的国", "analyzer": "ik_max_word" } PUT /test_a { "settings": { "index": { "analysis.analyzer.default.type": "ik_max_word" } } } POST /test_a/_doc/3 { "f": "中国,一个世界上最强的国家" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
只移动五次:

移动100次:

案例8:前缀搜索
使用前缀匹配实现搜索能力。通常针对keyword类型字段,也就是不分词的字段。
当然,我们也可以对非keywork类型的字段进行前缀搜索,只需要在字段后边加上.keyword即可
GET /es_db/_search { "query": { "prefix": { "address.keyword": { "value": "广州" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

前缀搜索效率比较低,前缀搜索不会计算相关度分数。前缀越短,效率越低。如果使用前缀搜索,建议使用长前缀。因为前缀搜索需要扫描完整的索引内容,所
以前缀越长,相对效率越高。
使用match和proximity search实现召回率和精准度平衡。
召回率:召回率就是搜索结果比率,如:索引A中有100个document,搜索时返回多少个document,就是召回率(recall)。
精准度:就是搜索结果的准确率,如:搜索条件为hello java,在搜索结果中尽可能让短语匹配和hello java离的近的结果排序靠前,就是精准度
(precision)。
如果在搜索的时候,只使用match phrase语法,会导致召回率底下,因为搜索结果中必须包含短语(包括proximity search)。
如果在搜索的时候,只使用match语法,会导致精准度底下,因为搜索结果排序是根据相关度分数算法计算得到。
那么如果需要在结果中兼顾召回率和精准度的时候,就需要将match和proximity search混合使用,来得到搜索结果。
案例9:通配符搜索
ES中也有通配符,但是和java还有数据库不太一样,通配符可以在倒排索引中使用,也可以在keyword类型字段中使用。
常用通配符:
- ? : 一个任意字符
- * :0~n个任意字符
GET /es_db/_search { "query": { "wildcard": { "remark": { "value": "d*" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
性能很低,需要扫描完整的索引。
案例10:正则搜索
ES支持正则表达式,可以在倒排索引或keyword类型字段中使用。
常用符号:
-
[]: 范围,如: [0-9]是0~9的范围数字 -
.: 一个字符
+ - 前面的表达式可以出现多次。
GET /es_db/_search { "query": { "regexp": { "remark": { "value": "[a-a].+" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

性能很低,需要扫描完整索引。
案例11:即时搜索
搜索推荐: search as your type, 搜索提示。如:索引中有若干数据,以“hello”开头,那么在输入hello的时候,推荐相关信息。(类似百度输入框)
其原理和match phrase类似,是先使用match匹配term数据(java),然后在指定的slop移动次数范围内,前缀匹配(d),max_expansions是用于指定prefix
最多匹配多少个term(单词),超过这个数量就不再匹配了。这种语法的限制是,只有最后一个term会执行前缀搜索,执行性能很差,毕竟最后一个term是需要扫描所有符合slop要求的倒排索引的term,因为效率较低,如果必须使用,则一定要使用参数max_expansions。
案例12:模糊搜索技术
搜索的时候,可能搜索条件文本输入错误,如:hello world -> hello word。这种拼写错误还是很常见的。fuzzy技术就是用于解决错误拼写的(在英文中很有效,在中文中几乎无效。),其中fuzziness代表value的值word可以修改多少个字母来进行拼写错误的纠正(修改字母的数量包含字母变更,增加或减少字)。
GET /es_db/_search { "query": { "fuzzy": { "remark": { "value": "jva", "fuzziness": 1 } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

案例13:高亮查询

在搜索中,经常需要对搜索关键字做高亮显示,高亮显示也有其常用的参数,在这个案例中做一些常用参数的介绍。
highlight简单使用
数据准备:
PUT /news_website { "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word" }, "content": { "type": "text", "analyzer": "ik_max_word" } } } } PUT /news_website/_doc/1 { "title": "我的第一篇文章", "content": "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
高亮显示:
GET /news_website/_doc/_search { "query": { "match": { "content": "文章" } }, "highlight": { "fields": { "content": {} } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

会变成红色,所以说你的指定的field中,如果包含了那个搜索词的话,就会在那个field的文本中,对搜索词进行红色的高亮显示。
highlight中要高亮的字段和要查询的字段是要进行一一匹配的,比如如果我们也想title中关键字做高亮显示可以这样做:
GET /news_website/_doc/_search { "query": { "bool": { "should": [ { "match": { "title": "文章" } }, { "match": { "content": "文章" } } ] } }, "highlight": { "fields": { "title": {}, "content": {} } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

highlight类型
在es中支持好几种highlight
- plain highlight(lucene highlight):默认
- posting highlight:性能比plain highlight要高,因为不需要重新对高亮文本进行分词,对磁盘消耗低。
- fast vector highlight:对大field而言(大于1mb),性能更高
我们看看其他两种的使用方式:
posting highlight:在mappering中设置"index_options": "offsets"DELETE news_website PUT /news_website { "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word" }, "content": { "type": "text", "analyzer": "ik_max_word", "index_options": "offsets" } } } } PUT /news_website/_doc/1 { "title": "我的第一篇文章", "content": "大家好,这是我写的第一篇文章,特别喜欢这个文章门户网站!!!" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

GET /news_website/_doc/_search { "query": { "match": { "content": "文章" } }, "highlight": { "fields": { "content": {} } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

fast vector highlight:在mappings中设置"term_vector": "with_positions_offsets"DELETE /news_website PUT /news_website { "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word" }, "content": { "type": "text", "analyzer": "ik_max_word", "term_vector": "with_positions_offsets" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

指定highlight
当然,如果我们在映射中指定了highlight,但是我们想要查询的时候也指定highlight,那么可以这样查询
GET /news_website/_doc/_search { "query": { "match": { "content": "文章" } }, "highlight": { "fields": { "content": { "type": "plain" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

设置highlight标签
我们高亮的标签默认是是标签,我们可以通过属性修改高亮标签
pre_tags:前置标签post_tags:后置标签
GET /news_website/_doc/_search { "query": { "match": { "content": "文章" } }, "highlight": { "pre_tags": [ "" ], "post_tags": [ "" ], "fields": { "content": { "type": "plain" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

##高亮片段fragment显示
有时候如果我们的内容特别多,不可能所有关键字都高亮显示,那么我们就可以指定片段数量和文本长度。
-
fragment_size:一个Field的值,比如有长度是1万,但是你不可能在页面上显示这么长,我们可以设置要显示出来的fragment文本判断的长度,默认是100 -
number_of_fragments:可能你的高亮的fragment文本片段有多个片段,你可以指定就显示几个片段
GET /_search { "query": { "match": { "content": "文章" } }, "highlight": { "fields": { "content": { "fragment_size": 10, "number_of_fragments": 1 } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

案例14:CrossFields 多字段搜索策略
数据准备:
POST /testcross/_bulk {"index":{"_id": 1}} {"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article"} {"index":{"_id": 2}} {"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"} {"index":{"_id": 3}} { "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"} {"index":{"_id": 4}} {"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"} {"index":{"_id": 5}} { "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"} {"index":{"_id": 6}} {"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer"} {"index":{"_id": 7}} {"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer"} {"index":{"_id": 8}} {"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language"} {"index":{"_id": 9}} {"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer"} {"index":{"_id": 10}} {"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch"} {"index":{"_id": 11}} {"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java "} {"index":{"_id": 12}} {"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good"} {"index":{"_id": 13}} {"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java "} {"index":{"_id": 14}} {"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++"} {"index":{"_id": 15}} {"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good"}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
地址存储的时候 不能直接存储 ”湖北省武汉市东湖高新区“ 这样的字符串,一个完整的地址需要用多个字段来唯一标识,一般存储的时候 省/市/区 分别是"provice", “city”, "area"三个字段,那我搜寻湖北省武汉市江汉区这个完整地址 的时候,会如何查询 provice=”湖北省“ , city=“武汉市” , area=“东湖高新” ?
我们可以使用most fields试下: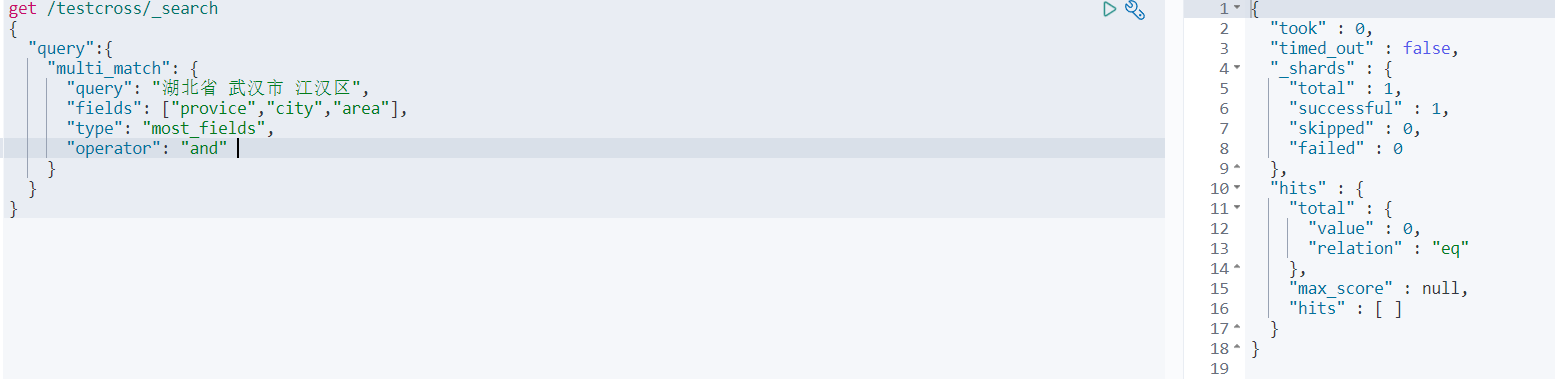

从结果来看:
- 不支持 operator=AND,没有一个doc可以match到,因为你的关键字是分布在多个字段中的用了and就是 provice包含湖北省武汉市江汉区或者city包含这三个词,后者 area包含这三个词, 没有一个doc能匹配,因为字段是打散的.
- 如果用 operator = OR 出来几十条, 从语义上也是错误的, 会把所有包含湖北省,武汉市都搜出来,因为OR操作就是任一字段匹配,就会大量重复无用数据 比如出现 湖北省 XX市 XX区 的数据,甚至是 河南省 郑州市 江汉区的类似数据.
- 搜索不准确,因为MostFields 会把多个词计算权重后参与最终分计算,累加求和,这就导致如果 有个 郑州市的江汉区,他的权重较高,然后会影响到 湖北省武汉市东湖高 的排序,比他会优先排序
也有人会想,我们直接使用组合查询,provice、city、area三个进行must匹配不就可以查询出来了吗,就如下边的效果:
get /testcross/_search { "query":{ "bool": { "must": [ { "match_phrase": { "provice": "湖北省" } }, { "match_phrase": { "city": "武汉" } }, { "match_phrase": { "area": "高新开发区" } } ] } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
似乎没什么问题, 但是正常我们的搜索,很多时候我是不知道他是具体什么字段的,比如我只知道 省/市/区 这三个ABC字段中包含了 湖北省,武汉,高新开发区的查询字段, 就给我命中返回,我不关心哪个字段匹配上,只要三个字段都存在就行
到底是 A:湖北省 B:武汉 C:高新开发区
还是 A:武汉 B:湖北省,C:高新开发区
还是 A:湖北省, B:高新开发区,C:武汉
所以And也是不满足的基于这种情况,我们可以使用词条为中心的CrossFields 搜索,我们可以实现当我们不关系具体哪些字段,我们只需要将多个field的信息整合成一个作为唯一标识返回即可。
get /testcross/_search { "query":{ "multi_match": { "query": "湖北省 武汉 高新开发区", "fields": ["provice","city","area"], "type": "cross_fields", "operator": "and" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

CrossFields 提高权重控制排名
可以查看刚才CrossFields的查询结果
员工 分数 员工10 8.200133 员工5 6.558913 如果 provice, city 及area 每个词的权重不同, 比如想要把city权重放的更高点,让权重优先的更考前的返回,我们可以直接在fields中计入权重计算, 可以看到 city 被我改成了 city ^ 2 就是权重扩大 2倍,默认都是1倍

city:高新开发区的被提前了 ,因为 city:武汉 有很多个文档,但是city:高新开发区的就只有几个,所以 TFIDF模型认为 高新开发区 的权重在city字段上更有代表性,所以权重更大,这就影响了结果的排序.
案例15:CopyTo字段组合实现逻辑多字段搜索
场景:
淘宝中搜手机,点击搜索,那么一个商品有很多属性,比如 商品名称,商品卖点,商品描述,商品评价等等等,那么如果搜索手机关键字,并且一个搜索条件都没限定,那底层到底是在那几个字段内进行匹配
如果仅用单一的字段比如名称字段来匹配,很有可能不是用户要的结果,如果使用全字段匹配?这样明显也不合适,比如商品价格,商品库存,商品店铺等,不包含手机信息,那么如何实现?解决办法:
- copy_to:就是将多个字段,复制到一个字段中,来实现多字段组合查询,用于解决搜索条件默认字段信息
- copy_to需要在创建mapping结构的时候就指定 需要将当前字段 copy_to 到哪个字段上,默认搜索条件生效的字段就是你要复制到的字段
准备数据:
注意:
put /testcopy PUT /testcopy/_mapping { "properties" : { "address" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } }, "copy_to":"info" }, "age" : { "type" : "long" }, "area" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "city" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "content" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "deptName" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } }, "copy_to":"info" }, "empId" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "mobile" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } }, "copy_to":"info" }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } }, "copy_to":"info" }, "provice" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "salary" : { "type" : "long" }, "sex" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } POST /testcopy/_bulk {"index":{"_id": 1}} {"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article"} {"index":{"_id": 2}} {"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"} {"index":{"_id": 3}} { "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"} {"index":{"_id": 4}} {"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"} {"index":{"_id": 5}} { "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"} {"index":{"_id": 6}} {"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer"} {"index":{"_id": 7}} {"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer"} {"index":{"_id": 8}} {"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language"} {"index":{"_id": 9}} {"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer"} {"index":{"_id": 10}} {"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch"} {"index":{"_id": 11}} {"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java "} {"index":{"_id": 12}} {"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good"} {"index":{"_id": 13}} {"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java "} {"index":{"_id": 14}} {"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++"} {"index":{"_id": 15}} {"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good"}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
我们搜索插入的数据是否正确及 info字段是否存在?
很显然是不存在这个字段的,但是我们搜索的时候却可以使用info字段取匹配
get /testcopy/_search { "query":{ "match_phrase": { "info": "员工" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

get /testcopy/_search { "query":{ "match_phrase": { "info": "湖北" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

至此 我们已经能够利用 CopyTo字段组合来实现逻辑多字段搜索,可以看到存储结构上并没有 info字段,但是我们可以用copy_to把多个字段关联起来实现多字段搜索.
loper thing java is good"}
{“index”:{“_id”: 13}}
{“empId” : “131313”,“name” : “李江汉”,“age” : 36,“sex” : “男”,“mobile” : “19000001013”,“salary”:1125,“deptName” : “销售部”,“provice” : “河南省”,“city”:“郑州市”,“area”:“二七区”,“address” : “河南省郑州市二七区”,“content” : “i like java and java is very best i like it do you like java “}
{“index”:{”_id”: 14}}
{“empId” : “141414”,“name” : “王技术”,“age” : 45,“sex” : “女”,“mobile” : “19000001014”,“salary”:6222,“deptName” : “测试部”,“provice” : “河南省”,“city”:“郑州市”,“area”:“金水区”,“address” : “河南省郑州市金水区”,“content” : “i like c++”}
{“index”:{“_id”: 15}}
{“empId” : “151515”,“name” : “张测试”,“age” : 18,“sex” : “男”,“mobile” : “19000001015”,“salary”:20000,“deptName” : “技术部”,“provice” : “河南省”,“city”:“郑州市”,“area”:“高新开发区”,“address” : “河南省郑州高新开发区”,“content” : “i think spark is good”}我们搜索插入的数据是否正确及 info字段是否存在? [外链图片转存中...(img-byM2NlK2-1710668677317)] 很显然是不存在这个字段的,但是我们搜索的时候却可以使用info字段取匹配 ```json get /testcopy/_search { "query":{ "match_phrase": { "info": "员工" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
[外链图片转存中…(img-be8FlMn8-1710668677317)]
get /testcopy/_search { "query":{ "match_phrase": { "info": "湖北" } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[外链图片转存中…(img-BMqw1ekq-1710668677318)]
至此 我们已经能够利用 CopyTo字段组合来实现逻辑多字段搜索,可以看到存储结构上并没有 info字段,但是我们可以用copy_to把多个字段关联起来实现多字段搜索.
🌟至此本篇就结束了,下一篇将介绍ES统计查询语法,希望和小伙伴们可以继续坚持学习!
-
相关阅读:
Go源码实现使用多线程并发下载大文件的功能
Xilinx 7系列 clock IP核的使用(二)
快速排序算法 QuickSort algorithm
@RabbitListener和@RabbitHandler的使用
ISO三体系的流程及必要性
14. Redisson 分布式锁
《UnityShader入门精要》学习4
云计算与低代码:重塑软件开发的新范式
2022年新能源汽车行业分析
Learning Transferable Features with Deep Adaptation Networks
- 原文地址:https://blog.csdn.net/qq_43599766/article/details/136786162
