-
探索性数据分析EDA的数据可视化
大家好,数据可视化是探索性数据分析的重要组成部分,因为它有助于分析和可视化数据,以获得对数据分布、变量之间的关系和潜在异常值的启示性见解。Python具有丰富的库,可以快速高效地创建可视化。
在Python中,通常使用以下几种类型的可视化进行探索性数据分析:柱状图(用于显示不同类别之间的比较)、折线图(用于显示随时间或不同类别的趋势)、饼图(用于显示不同类别的比例或百分比)、直方图(用于显示单个变量的分布)、热图(用于显示不同变量之间的相关性)、散点图(用于显示两个连续变量之间的关系)、箱线图(用于显示变量的分布并识别异常值)。
1. 理解业务问题
心血管疾病是全球死亡的主要原因。根据世界卫生组织的数据,每年约有1,790万人死于心脏病。其中85%的死亡是由心脏病发作和中风引起的。本文中将探索来自Kaggle的心脏病数据集,并使用Python创建用于探索性数据分析的数据可视化。
该数据集包含有关患者的数据,包括年龄、性别、血压、胆固醇水平以及是否患有心脏病发作等各种变量。该数据集的目标是根据患者的医疗属性预测其是否有心脏病发作的风险。
2.导入必要的库
- # import libraries
- import pandas as pd
- import numpy as np
- # data visualization
- import matplotlib.pyplot as plt
- import seaborn as sns
- import plotly.express as px
- import plotly.graph_objects as go
- from plotly.subplots import make_subplots
3. 加载数据集
将数据加载到一个Pandas DataFrame中,并开始探索它。
heart = pd.read_csv('heart.csv')现在已经加载数据,看一下DataFrame的前几行,以了解数据的大致情况。
heart.head()
可以看到数据集包含14列,包括目标列(输出),该列指示患者是否患有心脏病发作,现在开始创建可视化图表。
4. 数据清理和预处理
数据清理的目的是准备好数据进行分析和可视化。
- # 检查是否存在任何空值
- heart.isnull().sum().sort_values(ascending=False).head(11)

正如我们在这里看到的,这种情况下没有缺失值。
- # 检查重复值
- heart.duplicated().sum()
- # 删除重复值
- heart.drop_duplicates(keep='first', inplace=True)
5. 统计摘要
- # 获取数据集的统计摘要
- heart.describe().T
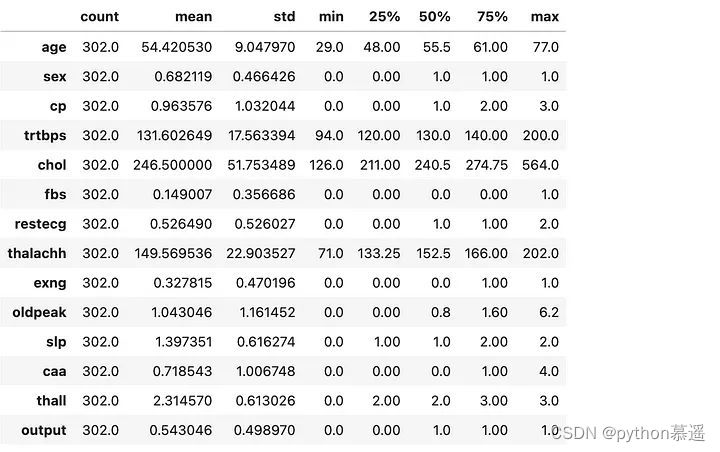
可以得出的主要结论是,对于大多数列,平均值与中位数(50th percentile: 50%)相似。
6. 数据可视化与解释
- 基于性别的数据可视化
- # Compare Heart Attack vs Sex
- df = pd.crosstab(heart['output'],heart['sex'])
- sns.set_style("white")
- df.plot(kind="bar",
- figsize=(6,6),
- color=['#c64343', '#e1d3c1']);
- plt.title("Heart Attack Risk vs Sex ", fontsize=16)
- plt.xlabel("0 = Lower Risk 1 = Higher Risk", fontsize=16)
- plt.ylabel("Amount", fontsize=16)
- plt.legend(["Female","Male"], fontsize=14)
- plt.xticks(rotation=0)

- fig = px.pie(heart2,
- names= "sex",
- template= "presentation",
- hole= 0.6,
- color_discrete_sequence=['#e1d3c1', '#c64343']
- #color_discrete_sequence=px.colors.sequential.RdBu
- )
- # layout
- fig.update_layout(title_text='Gender Distribution',
- title_x=0.5,
- font=dict( size=18),
- autosize=False,
- width=500,
- height=500,
- showlegend=False)
- fig.add_annotation(dict(x=0.5, y=0.5, align='center',
- xref = "paper", yref = "paper",
- showarrow = False, font_size=22,
- text="Gender
")) - fig.update_traces(textposition='outside', textinfo='percent+label', rotation=20)
- fig.show()

解释:男性患心脏病的风险更高。
- 基于年龄的数据可视化
- plt.figure(figsize=(14,8))
- sns.set(font_scale=1.2)
- sns.set_style("white")
- sns.countplot(x=heart["age"],
- palette='Reds')
- plt.title("Count of Patients Age",fontsize=20)
- plt.xlabel("Age",fontsize=16)
- plt.ylabel("Count",fontsize=16)
- plt.show()

- # age based analysis
- sns.set(font_scale=1.3)
- plt.figure(figsize=(8,6))
- sns.set_style("white")
- sns.distplot(heart['age'],
- color='red',
- kde=True)
- plt.title("Distribution of Patients Age",fontsize=20)
- plt.xlabel("Age",fontsize=16)
- plt.ylabel("Density",fontsize=16)
- plt.show()

解释:大多数患者的年龄在50-60岁之间。其中,患者中年龄为58岁的人数最多。
- 基于胆固醇水平的数据可视化
- # Attack vs Cholesterol analysis
- sns.set(font_scale=1.3)
- plt.figure(figsize=(8,6))
- sns.set_style("white")
- sns.distplot(heart[heart["output"]==0]["chol"],
- color="blue")
- sns.distplot(heart[heart["output"]==1]["chol"],
- color="red")
- plt.title("Heart Attack Risk vs Cholesterol", size=20)
- plt.xlabel("Cholesterol Level", fontsize=16)
- plt.ylabel("Density", fontsize=16)
- plt.legend(["Lower Risk","Higher Risk"], fontsize=14)
- plt.show()

- plt.figure(figsize=(8,6))
- sns.lineplot(y="chol",
- x="age",
- data=heart,
- color="red")
- plt.title("Cholesterol with Age",fontsize=20)
- plt.xlabel("Age",fontsize=16)
- plt.ylabel("Cholesterol Level",fontsize=16)
- plt.show()

解释:大多数患者的胆固醇水平在200-300之间;随着年龄的增长,体内胆固醇水平增加的可能性很高。
- 基于相关性的数据可视化
- plt.figure(figsize=(12,10))
- sns.set(font_scale=0.9)
- sns.heatmap(heart.corr(),
- annot=True,
- cmap='Reds')
- plt.title("变量间的相关性", size=15)
- plt.show()

解释:热图显示了变量之间相关性,比如胸痛类型(cp)和输出、达到的最大心率(thalachh)和输出、斜率(sp)和输出。
本文中使用数据可视化来检查数据集,创建了多个图表,如条形图、饼图、线图、直方图、热图。探索性数据分析(EDA)和数据可视化的主要目的是在做出任何假设之前帮助理解数据。它们帮助我们查看分布、摘要统计信息、变量之间的关系和异常值。
-
相关阅读:
【配送路径规划】基于matlab遗传算法求解静态外卖骑手路径规划问题【含Matlab源码 2248期】
【Linux】指针常量和常量指针
JAVA微信小程序核酸预约小程序系统毕业设计 开题报告
【Flink入门修炼】1-4 Flink 核心概念与架构
以OneFlow为例探索MLIR的实际开发流程
activiti-spring-app-process 源码分析
vue2+elementUI,vue3+elementPlus解决form中的下拉列表回写显示id,不显示label
docker安装目录迁移
基于 AdaFace 提供适合低质量人脸识别的人脸特征向量输出服务
分布式 PostgreSQL - Citus 架构及概念
- 原文地址:https://blog.csdn.net/csdn1561168266/article/details/136661007
