-
【MySQL】MySQL主从复制
技术背景
数据库架构演变
1.单机MySQL数据库的美好年代
在20世纪90年代,一个网站的浏览量一般都不大,用单个数据库完全可以轻松应付。 在那个时候,更多的都是静态网页,动态交互类型的网站不多
2.Memcached(缓存)+MySQL
- 随着网站浏览量的增多,几乎大部分使用MySQL架构的网站在数据库方面都开始出现了性能问题,Web程序不再仅仅专注在功能业务,同时也在追求性能。
- 为了尽快缓解用户访问的压力,一般在优化数据库的结构和索引的基础上,会在应用服务器和数据库服务器中间加一个缓存层来抵消掉一部分的数据库查询操作。

3.主从复制:读写分离
- 由于数据库的写入压力增加,Memcached 只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。
- MySQL的Master-Slave模式成为这个时候的网站标配了。主从库之间通过同步机制把主库的数据同步到从库,对于需要查询最新写入数据的场景,可以在缓存中多写一份,通过缓存获得最新数据

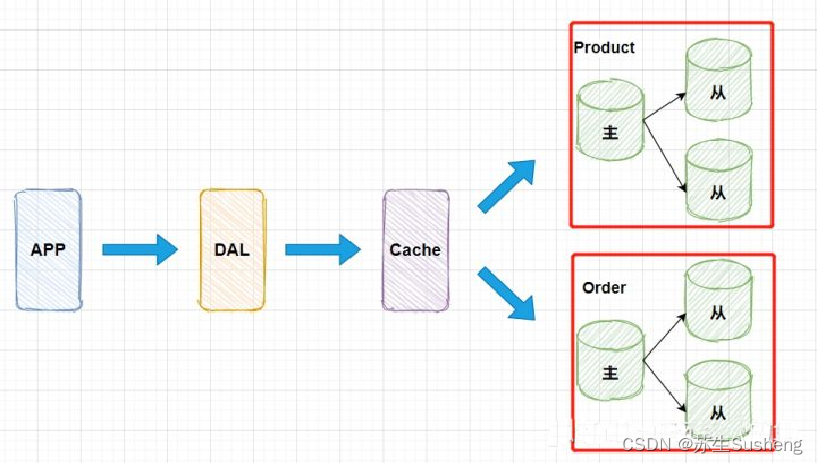
4.垂直拆分业务数据
- 当我们使用了主从数据库架构之后,我们会发现我们能支撑更多的用户访问和请求了。但随着业务的进一步发展,如电商系统中增加了商品库存系统,此时就会与原有的订单系统抢占数据库资源,相互影响性能,导致数据库的压力进一步增大。
- 数据量的持续猛增,MySQL主库的写压力开始出现瓶颈
5.分库分表
如果一个网站业务快速发展,那这个网站流量也会增加,数据库的压力也会随之而来,比如电商系统来说双十一大促对订单数据压力很大,十几万并发量,如果是一主多从架构,主库容量肯定无法满足这么高的TPS,业务越来越大,会出现如下问题
- 单表数据量太大,超出了数据库支持的容量。MySQL 单表的最大尺寸不能超过 2TB,假设一个表的平均行长度为32KB,最大能存储多少行数据?4 x 1024 x 1024 x 1024 / 32 = 134217728,大约 1.4 亿不到。对于饿了么,美团那外卖种交易系统的订单表 1.4 亿是很容易达到的,一天平均 2000W 订单,一周就到 1.4 亿了,没法玩
- 随着表数据的不断增大,会发现,查询也随着变得缓慢。
- 随着时间的推移,数据库不堪重负,可能会宕机。

结论——生产环境的MySQL架构
简单来说,MySQL在生产环境中,必须要搭建一套主从复制的架构,同时可以基于一些工具实现高可用架构。
另外如果有需求,还需要基于一些中间件实现读写分离架构
最后就是如果数据量很大,还必须可以实现分库分表的架构。什么是主从复制
- 主从复制是指将主库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持一致。
- MySQL 支持一台主库同时向多台从库进行复制,从库同时也可以作为其他从服务器的主库,实现链状复制。
- MySQL 主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
- 顾名思义,就是部署两台服务器,每台服务器上都得有一个MySQL,其中一个MySQL是master(主节点),另外一个MySQL是slave(从节点)。然后系统平时连接到master节点写入数据,当然也可以从里面查询了,就跟用一个单机版的MySQL是一样的,但是master节点会把写入的数据自动复制到slave节点去,让slave节点可以跟master节点有一模一样的数据

作用
- 实时灾备,用于故障切换:主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失,确保数据安全,提升性能。
- 读写分离,使数据库能支持更大的并发。在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)
- 做数据的热备,作为后备数据库,避免影响业务:可以在从库中执行备份,以避免备份期间影响主库服务。
- 通过架构的扩展,实现高可用的数据库架构。当业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的评率,提高单个机器的I/O性能。
读写分离
- 假设MySQL单机服务器配置是8核16GB,然后每秒最多能抗4000读写请求,现在假设真实的业务负载已经达到了,每秒有2500写请求+2500读请求,也就是每秒5000读写请求了,那么如果都放一台MySQL服务器,能抗的住吗?必然不行!
- 所以此时如果可以利用主从复制架构,搭建起来读写分离架构,就可以让每秒2500写请求落到主节点那台服务器,2500读请求落到从节点那台服务器,用2台服务器来抗下每秒5000的读写请求

一主多从
- 接着上述的案例,现在问题来了,其它大部分Java业务系统都是读多写少,读请求远远多于写请求,那么接着发现随着系统日益发展,读请求越来越多,每秒可能有6000读请求了,此时一个从节点服务器也抗不下来啊,那怎么办呢?
- 简单!因为MySQL的主从复制架构,是支持一主多从的,所以此时可以再在一台服务器上部署一个从节点,去从主节点复制数据过来,此时就有2个从节点了,然后每秒6000读请求不就可以落到2个从节点上去了,每台服务器主要接受每秒3000的读请求

应用场景
- 主库压力较大扛不住时,可通过主从复制把读压力分担一部分到从库上;
- 业务高峰数据库连接数太多时,例如高峰的认证,只需要把这个业务分拆到从库上;
- 低频复杂类且难以优化的 SQL(报表统计分析类的 SQL),专门在从库上执行;
- 利用从库做高可用切换。
原理解析


- 主库汇报数据变更记录在二进制日志文件 binlog 中:MySQL主库在执行增删改的时候会记录binlog日志,这个binlog日志里就记录了所有数据增删改的操作
- a) 启动(Slave I/O Thread->master.info;Slave SQL Thread,Relay-log.info);
- b) 建立连接(slave I/O Thread->master.info;Master log Dump
- 从库连接主库,读取 binlog 日志,并写入自身中继日志 Relay log:从库上有一个IO线程,这个IO线程会负责跟主库建立一个TCP连接,接着请求主库传输binlog日志给自己,这个时候主库上有一个IO dump线程,就会负责通过这个TCP连接把binlog日志传输给从库的IO线程
- a) 获取更新日志(Master log dump Thread->binlog);
- b) 传递更新日志(Master log dump Thread->binlog;slave I/O Thread->master.info);
- c) 保存更新日志(slave I/O Thread->master.info;slave Relay log)
- slave 重做中继日志,将改变反映它自身的数据:应用中继日志(Slave SQL Thread;relay-log.info;slave Relay Log)。从库的IO线程会把读取到的binlog日志数据写入到自己本地的relay日志文件中去,然后从库上另外有一个SQL线程会读取relay日志里的内容,进行日志重做,把所有在主库执行过的增删改操作,在从库上做一遍,达到一个还原数据的过程,如图:

MySQL主从复制工作方式
master 记录二进制日志。
在每个事务完成数据更新之前,master 在二进制日志记录这些改变。MySQL 将事务串行地写入二进制日志,完成后,master 通知存储引擎提交事务。
slave 将 master 的 binary log 拷贝到它自身的中继日志:
- 首先,slave 开始一个工作线程:I/O 线程;
- I/O 线程在 master 上打开一个普通的连接,然后开始 binlog dump process。binlog dump process 从 master 的二进制日志中读取事件(接收的单位是 event),如果已经跟上 master,它会睡眠并等待 master 产生新的事件;
- I/O 线程将这些事件写入中继日志。
SQL slave 重做中继日志
- Thread(SQL 从线程)是处理该过程的最后一步。SQL 线程从中继日志读取事件,并重放其中的事件(回放的单位也是 event)更新 slave 的数据,使其与 master 中的数据一致。只要该线程与 I/O 线程保持一致,中继日志通常会位于 OS 的缓存中,所以中继日志的开销很小;
- 在 master 中也有一个工作线程:和其他 MySQL 的连接一样,slave 在 master 中打开一个连接也会使得 master 开始一个线程。
主从复制分类
主从复制可分为异步复制、同步复制和半同步复制三种:
异步复制
- 异步复制为 MySQL 默认的复制模式,指主库写 binlog、从库 I/O 线程读 binlog 并写入 relaylog、从库 SQL 线程重放事务这三步之间是异步的。
- 异步复制的主库不需要关心备库的状态,主库不保证事务被传输到从库,如果主库崩溃,某些事务可能还未发送到从库,切换后可能导致事务的丢失。其优点是可以有更高的吞吐量,缺点是不能保持数据实时一致,不适合要求主从数据一致性要求较高的应用场景。
同步复制
同步复制的模式下,主库在提交事务前,必须确认事务在所有的备库上都已经完成提交。即主库是最后一个提交的,在提交前需要将事务传递给从库并完成重放、提交等一系列动作。其优点是任何时候主备库都是一致的,主库的崩溃不会丢失事务,缺点是由于主库需要等待备库先提交事务,吞吐量很低。
半同步复制
- MySQL 从 5.5 版本开始引入了半同步复制,半同步复制介于异步复制和同步复制之间。主库在提交事务时先等待,必须确认至少一个从库收到了事件(从库将事件写入 relaylog,不需要重放和提交,并向主库发送一个确认信息 ACK),主库收到确认信息后才会正式 commit。
- 与同步复制相比,半同步复制速度快很多,因为它只需要至少1个从库确认写入 relaylog,并不需要完成在从库上的事务提交,同时又比异步复制更安全,因为主库在提交时,事务至少已经存在2个地方(主库的 binlog 和从库的 relaylog)。
- 由于半同步复制在提交事务前,需要从库返还确认信息,所以这里涉及到网络的往返通信开销,因此半同步复制只适合在网络条件较好且地理上距离不远的环境部署,否则可能会因为网络延迟大幅降低主库性能。
MySQL一主一从环境搭建
准备工作
操作系统 主机 IP centos7 master 192.168.29.201 centos7 slave 192.168.29.202 环境搭建的步骤:
- 在master主机上安装MySQL
- 修改主机名,添加主机名与IP对应关系
- 时间同步
- 克隆master主机为salve,修改主机名,并修改UUID
- 修改各自的配置文件
- 设置主从同步
1. master主机配置
修改主机名
hostnamectl set-hostname master- 1
添加主机名与IP对应关系
vim /etc/hosts 192.168.29.201 master 192.168.29.202 slave- 1
- 2
- 3

时间同步
yum -y install chrony systemctl start chronyd systemctl enable chronyd chronyc sources -v- 1
- 2
- 3
- 4

2. slave配置
克隆
克隆master主机为salve(克隆CentOS7-MySQL-Master为CentOS7-MySQL-Slave)
修改IP地址
修改主机名称
hostnamectl set-hostname slave- 1
修改UUID
vi /usr/local/mysql/data/auto.cnf #按下键盘上的i键,修改UUID的值 #按下ESC键 #输入:wq保存并退出- 1
- 2
- 3
- 4
重启MySQL
service mysqld restart- 1
如果重启失败报错
......... Starting MySQL.my_print_defaults: [Warning] World-writable config file '/etc/my.cnf' is ignored. my_print_defaults: [Warning] World-writable config file '/etc/my.cnf' is ignored. Logging to '/usr/local/mysql/data/slave.err'.- 1
- 2
- 3
- 4
 那就去/usr/local/mysql/data下面查看slave.err里面的报错,其中有一句:
那就去/usr/local/mysql/data下面查看slave.err里面的报错,其中有一句:Unable to lock ./ibdata1 error: 11,说明MySQL进程被占用着,那么就kill -9 杀mysql进程了
 然后再重启
然后再重启service mysqld restart就可以了3.配置文件修改
修改master主机的配置文件
vim /etc/my.cnf #添加以下内容 server-id=1 log-bin=/var/lib/mysql/master-bin log-slave-updates=true relay-log=relay-log-bin relay-log-index=slave-relay-bin.index- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
重启MySQL服务:
service mysqld restart修改slave主机的配置文件
vim /etc/my.cnf #添加以下内容 server-id=2 log-bin=/var/lib/mysql/master-bin log-slave-updates=true relay-log=relay-log-bin relay-log-index=slave-relay-bin.index- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
重启MySQL服务:
service mysqld restart【附录】其他配置项
#是否只读,1代表只读,0代表读写 read-only=0 #忽略的数据,指不需要同步的数据库 binlog-ignore-db=mysql_001 #指定同步的数据库 binlog-do-db=db01- 1
- 2
- 3
- 4
- 5
- 6
4.设置主从同步
master节点创建主从同步时使用的账号
#登录mysql: mysql -uroot -p grant replication slave on *.* to replicate@'%' identified by '123456'; GRANT ALL PRIVILEGES ON *.* TO replicate@'%' IDENTIFIED BY '123456';- 1
- 2
- 3
- 4
查看master_log_file以及master_log_pos
show master status;- 1
 这里有的是master-bin.000001,无论是哪个,只要跟slave指定的保持一致就可以了
这里有的是master-bin.000001,无论是哪个,只要跟slave指定的保持一致就可以了5.slave节点建立主从同步
#登录mysql mysql -uroot -p change master to master_host='192.168.29.100',master_user='replicate',master_password='123456',master_log_file='master-bin.000002',master_log_pos=1405;- 1
- 2
- 3
解析
- master_host_name : MySQL主机地址
- replication_user_name : 备份账户用户名
- replication_password :备份账户密码
- recorded_log_file_name :bin-log的文件名
- recorded_log_position : bin-log的位置(数字型)
6.开启同步
start slave;- 1
7.查看同步状态
show slave status\G;- 1
8.测试主从数据同步
主库创建库、表、加数据

从库查看

-
相关阅读:
息肉分割(Polyp Segmentation)方向常用数据集汇总
Docker高级-1.复杂安装示例(mysql主从复制、redis集群)
短信在企业中的应用有哪些?
XML文件格式学习
【C++·峰顶计划】引用操作及底层原理深析,七夕也要学习哦
docker搭建nacos2.x集群
Citrix Hypervisor升级vGPU 14.0
JS快速入门
Nginx的重写功能——Rewrite
概率论与数理统计 P6 条件概率
- 原文地址:https://blog.csdn.net/weixin_37833693/article/details/136700287