-
【C++初阶】C++入门(上)
C++的认识
①什么是C++?
C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。
于是1982年,Bjarne Stroustrup(本贾尼)博士在C语言的基础上引入并扩充了面向对象的概念,发明了一 种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。因此:C++是基于C语言而 产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。
所以说,C++是祖师爷在C语言的基础上,发明了C++语言,C++是兼容C语言的,C语言程序是可以在C++上运行的,而C++程序是不能在C语言上运行的,所以我们在学习C++语言时,最好把C语言学习一下,打好基础,以便于在后续的C++学习中事半功倍。
祖师爷的帅照:

②C++的发展阶段:
阶段 内容 C with classes 类及派生类、公有和私有成员、类的构造和析构、友元、内联函数、赋值运算符重载等 C++1.0 添加虚函数概念,函数和运算符重载,引用、常量等 C++2.0 更加完善支持面向对象,新增保护成员、多重继承、对象的初始化、抽象类、静态成员以及const成员函数 C++3.0 进一步完善,引入模板,解决多重继承产生的二义性问题和相应构造和析构的处理 C++98 C++标准第一个版本,绝大多数编译器都支持,得到了国际标准化组织(ISO)和美国标准化协会认可,以模板方式重写C++标准库,引入了STL(标准模板库) C++03 C++标准第二个版本,语言特性无大改变,主要:修订错误、减少多异性 C++05 C++标准委员会发布了一份计数报告(Technical Report,TR1),正式更名 C++0x,即:计划在本世纪第一个10年的某个时间发布 C++11 增加了许多特性,使得C++更像一种新语言,比如:正则表达式、基于范围for循 环、auto关键字、新容器、列表初始化、标准线程库等 C++14 对C++11的扩展,主要是修复C++11中漏洞以及改进,比如:泛型的lambda表 达式,auto的返回值类型推导,二进制字面常量等 C++17 在C++11上做了一些小幅改进,增加了19个新特性,比如:static_assert()的文 本信息可选,Fold表达式用于可变的模板,if和switch语句中的初始化器等 C++20 自C++11以来最大的发行版,引入了许多新的特性,比如:**模块(Modules)、协 程(Coroutines)、范围(Ranges)、概念(Constraints)**等重大特性,还有对已有 特性的更新:比如Lambda支持模板、范围for支持初始化等 C++23 制定ing ③C++的重要性
下图数据来自TIOBE编程语言社区2023年-2024年最新的排行榜,在30多年的发展中,C/C++几乎一 致稳居前5。

TIOBE 编程语言社区排行榜是编程语言流行趋势的一个指标,每月更新,这份排行榜排名基于互联网上有经验的程序员、 课程和第三方厂商的数量。排名使用著名的搜索引擎(诸如 Google、 MSN、Yahoo!、Wikipedia、YouTube 以及 Baidu 等)进行计算。
注意:排名不能说明那个语言好,那个不好,每门编程语言都有适应自己的应用场景。
④C++在工作领域
- 操作系统以及大型系统软件开发
- 服务器端开发
- 游戏开发
- 嵌入式和物联网领域
- 数字图像处理
- 人工智能
- 分布式应用
总结:C++语言可以有各种各样的商业编译器或专有领域编译器,但是由开源社区积极维护的免费编译器,始终都唾手可得。如C++宇宙编译器VS,这一切,加上C++与时俱进的实现更新,配套完善的标准跟进,都使得C++语言的生命力长盛不衰。
C++的学习是一个长期漫长的过程,一定不能急于求成,我们一起加油!
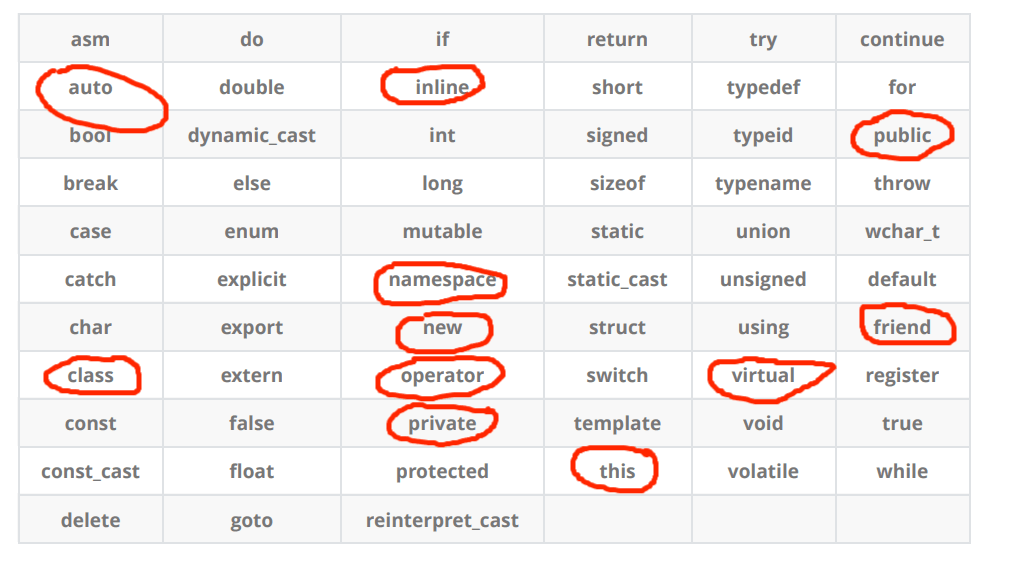
1.C++关键字
在C语言中关键字有32个,而C++中关键字有63个。下面画红圈圈的就是C++中新增的一些关键字,当然并没有圈完,这些关键字后续学习到了再说。
2.命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化, 以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
在C语言中:
#include#include int strlen= 10; int main() { //strlen函数是存在于string.h头文件中 printf("%d\n",strlen); //错误C2365 “strlen” : 重定义;以前的定义是“函数” return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里可以看出,在C语言中函数是不可以重新定义成变量,所以C++中就引入了namespace关键字,来解决这种命名冲突。
2.1 命名空间定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字(这个你随便取名字),然后接一对{}即可,{} 中即为命名空间的成员。
命名空间中可以定义变量/函数/类型:
namespace CSJ { int rand = 10;//变量 int Add(int left, int right)//函数 { return left + right; } struct Node//结构体类型 { struct Node* next; int val; }; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
命名空间还可以嵌套使用:
//test.cpp namespace N1 { int a=10; int b=20; int Add(int left, int right) { return left + right; } namespace N2 { int c=30; int d=40; int Sub(int left, int right) { return left - right; } } } //同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。 // 一个工程中的test.h和上面test.cpp中两个N1会被合并成一个 // test.h namespace N1 { int Mul(int left, int right) { return left * right; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中。
2.2 命名空间使用
命名空间的使用有三种方式:
-
(一)加命名空间的名称及作用域限定符(::)
像上述的使用rand变量就可以这样操作:
int main() { printf("%d\n", CSJ::rand); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
-
(二)使用using将命名空间中的某个成员引入
using N1::b; int main() { printf("%d\n", N1::a); printf("%d\n", b); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
(三)使用using namespace命名空间名称引入
using namespace N1; int main() { printf("%d\n", N1::a); printf("%d\n", b); Add(10, 20); return 0; } 注意:在上述的嵌套的命名空间中,如果要使用N2中的变量,函数等时,必须先把N1的空间先打开,再把N2的空间打开,才能使用N2空间中的内容。 ```cpp namespace N1 { int a=10; int b=20; int Add(int left, int right) { return left + right; } namespace N2 { int c=30; int d=40; int Sub(int left, int right) { return left - right; } } } using namespace N1; using namespace N2;//而且使用命名空间,必须在定义命名空间的下面才行 int main() { printf("%d\n", d); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3.C++输入&输出
在C语言中我们对于输入和输出使用的是scanf和printf,头文件是
。而对于C++的输入和输出,它们存在于iostream库中,iostream库中包含两个基础类型istream和ostream,分别表示输入流和输出流。cin就是标准输入,cout就是标准输出。 #include// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中 //cout,cin,endl这些都是存放在std的命名空间中 using namespace std; int main() { cout<<"Hello world!!!"<<endl;//endl是换行的意思,相当于C语言中的\n return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
C++的输入输出比较于C语言的输入输出,还具有一些优势,在C语言中你的输入输出还需要指定变量的类型,而C++的输入输出可以自动识别变量类型。这里可以提供一个关键字typeid,可以得到变量的类型。
#includeusing namespace std; int main() { int a; double b; char c; cin >> a; cin >> b >> c;//>>是流提取运算符,<<是流插入运算符 cout << a << endl; cout << b << " " << c << endl; cout << "a:" << typeid(a).name() << endl; cout << "b:" << typeid(b).name() << endl; cout << "c:" << typeid(c).name() << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

std命名空间的使用惯例:
std是C++标准库的命名空间,如何展开std使用更合理呢?
1.在日常练习中,建议直接using namespace std即可,这样就很方便。
2.using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对象/函数,就存在冲突问题。
该问题在日常练习中很少出现,但是项目开发中代码较多、规模大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 + using std::cout展开常用的库对象/类型等方式。
4.缺省参数
4.1 缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
void Func(int a = 0) { cout<<a<<endl; } int main() { Func(); // 没有传参时,使用参数的默认值,打印0出来 Func(10); // 传参时,使用指定的实参,打印10出来 return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.2 缺省参数分类
-
全缺省参数(顾名思义:函数的参数全给缺省值)
void Func(int a = 10, int b = 20, int c = 30) { cout<<"a = "<<a<<endl; cout<<"b = "<<b<<endl; cout<<"c = "<<c<<endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
半缺省参数
void Func(int a, int b = 10, int c = 20) { cout<<"a = "<<a<<endl; cout<<"b = "<<b<<endl; cout<<"c = "<<c<<endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
**注意:**半缺省参数,只能从右往左给缺省值,不能间隔写。比如:
void Func(int a=10, int b , int c = 20)//这样写就是错误的- 1
还有缺省参数不能在函数声明和定义中同时出现,而且缺省参数必须是常量或者全局变量。
// a.h void Func(int a = 10); // a.cpp void Func(int a = 20) {} // 注意:如果生命与定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该用那个缺省值。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
5.函数重载
5.1 函数重载的概念
众所周知:C语言中的函数名称是不能相同的,而C++为了解决这个问题,于是函数重载就被发明出来了。
**函数重载:**在同一个作用域内,可以声明几个功能类似的同名函数,但是这些同名函数的形式参数(指参数的个数、类型或者顺序)必须不同。您不能仅通过返回类型的不同来重载函数。
1.参数类型不同:
// 1、参数类型不同 int Add(int left, int right) { cout << "int Add(int left, int right)" << endl; return left + right; } double Add(double left, double right) { cout << "double Add(double left, double right)" << endl; return left + right; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.参数个数不同
// 2、参数个数不同 void f() { cout << "f()" << endl; } void f(int a) { cout << "f(int a)" << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.参数类型顺序不同
// 3、参数类型顺序不同 void f(int a, char b) { cout << "f(int a,char b)" << endl; } void f(char b, int a) { cout << "f(char b, int a)" << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这几个函数你都可以传入不同的参数来调用它们。

6.引用
6.1 引用概念
引用变量是一个别名,也就是说,它是某个已存在变量的另一个名字。一旦把引用初始化为某个变量,就可以使用该引用名称或变量名称来指向变量。**编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。**就好比我们给一个人取了一个外号,我们叫他真名和这个外号都是这个人。
#includeint main() { int a = 10; int& ra = a;//ra就是引用了变量a printf("%p\n", &a); printf("%p\n", &ra); //这里的地址打印出来都是一样的,如下图所示 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

注意:这里的引用类型必须和引用实体是相同类型,两个都为int,或者两个都为double等。
6.2 引用特性
-
引用在定义时必须初始化
-
一个变量可以有多个引用
-
引用一旦引用一个实体,再不能引用其他实体
#includeint main() { int a = 20; int b = 10; //1.引用在定义的时候必须初始化 //int& r; //报错:“r” : 必须初始化引用 //2.一个变量可以有多个引用 int& ra = a; int& rra = a; //3.引用一旦引用一个实体,再不能引用其他实体 int& ra = b;//错误 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
关于引用在定义时必须初始化的原因:一般在初始化变量时,初始值会被拷贝到新建的对象中。然而定义引用时,程序把引用和它的初始值绑定在一起,而不是将初始值拷贝给引用。一旦初始化完成,引用将和它的初始值对象一直绑定在一起。因为无法令引用重新绑定到另一个对象,因此引用必须初始化。
6.3 常引用
我们把引用绑定到const对象上,就像绑定到其他对象上一样,我们称之为对常量的引用,简称常引用。
int main() { const int a = 10; //int& r1 = a;//报错:ci为常量,“初始化” : 无法从“const int”转换为“int& ” const int& r2 = a; double b= 20; //int& r3 = b;//报错:类型不同,“初始化” : 无法从“double”转换为“int & ” const int& r4 = b;//那为什么这个又能行呢? return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对于**double b=20,const int& r4 = b,**为什么可以,此处 r4 引用了一个int型的数。对 r4 的操作应该是整数运算,但 b 却是一个双精度浮点数而非整数。因此为了确保让 r4 绑定一个整数,编译器把上述代码变成了如下形式:
const int temp=b;//由双精度浮点数生成一个临时的整型变量 const int &r4=temp;//让r4绑定这个临时量- 1
- 2
6.4 使用场景
-
引用做参数
//1.值传递(形参只是实参的一份临时拷贝,形参交换并不会影响实参,故而交换函数不成功) void Swap(int left, int right) { int temp = left; left = right; right = temp; } //2.引用传递(如果形参为引用类型,则形参是实参的别名,进而交换函数成功) void Swap(int& left, int& right) { int temp = left; right = left; left = temp; } //3.指针传递(传入的是地址,因为地址是唯一的,所以指针通过地址的访问进而可修改其内容) void Swap(int* left, int* right) { int temp = *left; *left = *right; *right = temp; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
-
引用做返回值
int& Count() { int n = 10; return n; }- 1
- 2
- 3
- 4
- 5
- 6
对于引用做返回值我们需要注意,如下面的代码:
int& Add(int a, int b) { int c = a + b; return c; } int main() { int& ret = Add(1, 2); std::cout << "Add(1, 2) is :" << ret << std::endl; return 0; } //这里我们以为1+2=3,所以结果就是3,那结果是什么呢?- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

这里可以看出,得到了一个很奇怪的数。这是因为Add函数里面定义了C变量,而C的作用域只限定于Add函数里面,出了函数,C的空间就已经还给操作系统了,你自然没法引用了。
6.5 传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
所以这里我们就比较一下传值和传引用的效率:
- 以函数参数比较两者
#includestruct A { int a[10000]; }; void TestFunc1(A a) {} void TestFunc2(A& a) {} void TestRefAndValue() { A a; // 以值作为函数参数 size_t begin1 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc1(a); size_t end1 = clock(); // 以引用作为函数参数 size_t begin2 = clock(); for (size_t i = 0; i < 10000; ++i) TestFunc2(a); size_t end2 = clock(); // 分别计算两个函数运行结束后的时间 cout << "TestFunc1(A)-time:" << end1 - begin1 << endl; cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl; } int main() { TestRefAndValue(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

#includestruct A { int a[10000]; }; A a; // 值返回 A TestFunc1() { return a; } // 引用返回 A& TestFunc2() { return a; } void TestReturnByRefOrValue() { // 以值作为函数的返回值类型 size_t begin1 = clock(); for (size_t i = 0; i < 100000; ++i) TestFunc1(); size_t end1 = clock(); // 以引用作为函数的返回值类型 size_t begin2 = clock(); for (size_t i = 0; i < 100000; ++i) TestFunc2(); size_t end2 = clock(); // 计算两个函数运算完成之后的时间 cout << "TestFunc1 time:" << end1 - begin1 << endl; cout << "TestFunc2 time:" << end2 - begin2 << endl; } int main() { TestReturnByRefOrValue(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28

通过上述代码的比较,发现**传值和传引用(指针)在作为传参以及返回值类型上效率相差很大。**但是在传引用作为返回值时,就像上面说的,一点要注意变量的生命周期。
6.6 引用和指针的区别
引用在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。(上面已经把地址拿出来比较了,确实是)
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
int main() { int a = 10; int& ra = a; a = 20; int*pa = &a; *pa = 20; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

这里我们可以看出,引用和指针的反汇编代码是一样的。即验证了引用是指针方式来实现的。
引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32 位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
-
相关阅读:
洛谷P4314 CPU【线段树】
IEEE Trans. On Robotics “受护理人员启发的双臂机器人穿衣”研究工作
STM8S系列基于STVD开发,标准外设库函数开发环境搭建
Vue获取methods中方法的return返回值
IntelliJ IDEA新建gradle项目
关于el-upload看这一篇就够了
基于RWEQ模型的土壤风蚀模数估算及其变化归因分析
ORACLE AutoVue 服务器/桌面版/WebService/SDK安装
阶段七-Day02-SpringMVC
手机银行体验性测试:如何获取用户真实感受
- 原文地址:https://blog.csdn.net/adcxhw/article/details/136720658
