-
UNIAPP微信小程序中使用Base64编解码原理分析和算法实现
为何要加上UNIAPP及微信小程序,可能是想让检索的翻围更广把。😇 Base64的JS原生编解码在uni的JS引擎中并不能直接使用,因此需要手写一个原生的Base64编解码器。正好项目中遇到此问题,需要通过URLLink进行小程序跳转并携带Base64参数进行数据传递,从而更好的在跳转后的初始化中进行鉴权等其他操作。特此将Base64的相关内容进行分析。需要具体实现算法的直接跳到最后即可Base64分析
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符 来表示二进制数据的方法。简单来说就是一种编码的格式。为了更方便的进行数据传递。为什么不直接用ascii编码传递,可见后续ascii编码表的一堆其他符号,由于不同的设备对字符处理的方式有一些不同,所以用纯文本格式是最安全且高效的,因此base64的作用用于将非文本数据转换为可安全传输的文本格式,如果你希望你要发送的东西最后能完整的呈现的话,这是非常好的编解码方案。同理还有Base16 32 等,掌握其算法,可以根据业务需求自己编写编解码器并指定编码表。
为何要编码呢?我直接传递不行么?
首先这个问题很好回答,如果你的场景支持你预想的方式进行传递,那你完全可以不用Base64进行数据传递,而是采用更方便的JSON或其他传输格式。总的来说Base64并没有什么好神奇的,不过是一个不同载体之间的传递方案罢了,例如URL中拼接URL就需要对拼接的URL进行URL编码,例如需要结构化描述性强的数据传输,则用XML格式。(解决问题的方案很多种,并非一定是用某种方案,而经验更丰富的人会明白不同的方案间带来的长期维护以及后续迭代的方便性以及后续业务的拓展约束性)
有哪些场景可以使用Base64?
例如网站证书的编码,电子邮件的附件传递,再比如要传输 XML 格式文件,其中内嵌一段 XML 格式代码,那此时标签会造成混淆,因此可以将内嵌的 XML 进行Base64编码,接收方再通过解码拿到关键数据。还有网页中的小icon或小图片等,可以利用Base64进行直接内嵌,减少网络请求。也有可能是你要传输一段纯文本的格式数据,但是你想在其中内嵌一张图片,那么你可以在数据中嵌入Base64编码的图片字符。
ASCII编码
如果你是计科的,那你一定听过ASCII码,这是一个历史悠久的字符编码格式,如果是非科班,你可能又有疑问?整这么多码干啥?
首先需要明白计算机内部进行存储数据的最基本单位是 Bit 也就是 0 或者 1的二进制数字,在最初的编码员操作的时候,都是手敲这些玩意,你比如要表示 666,就是1010011010。就这二进制,你除非背过不然也一时半会看不出来,得通过运算得出表示的是 666 。那更别说字符了。
更早之前都没有操作系统这回事的时候,基本都是输入输出系统,用于军事科学或高级复杂计算,那会儿每个厂商比如IBM、DEC等自己都涉及了一套编码的方案,用于表示字符,那这样的话其实兼容性就十分的不好,不同厂商之间的电脑数据传输也需要进行不同的编解码。后来就美国国家标准协会发布了一套统一的编码格式,就叫ASCII码(如下图),虽然是美国发布的,但起技术的前沿发展性,几乎全球都认可并使用。后续的Base64编码也需要用到ASCII编码表

好了相信你已经知道了这些码的作用,其实是必要的,否则无法进行数据的直观展示,因为目前计算机是普及的,人们希望直观的看到数据,现在ASCII也是过去式了,主流是Unicode,Unicode 提供了超过 140000 个字符的编码空间,也叫万国码,涵盖了世界上几乎所有的语言字符,是一种跨平台跨国家的乱码解决方案。然后unicode仅是一个编码的方案,并没有规定具体的编码方式(直接按照unicode硬存也行,只是没有算法的加持效率非常低),所以UTF-8出现了。具有变长编码的算法,能够大幅度节省存储的空间,也能确保数据转换的覆盖性,还有就是完美向下兼容ASCII,所以说UTF-8是unicode这种编码集的最终的优化实现。
Base64原理分析
相信你已经了解编码这回事了,接下来直接上图,计算机的底层虽然是2进制组成,但展示的时候通常是10进制的

例如我现在需要将 “Base64” 这个字符串进行 Base64编码,简单来说就是将字符的二进制转为Base64编码,将字符转为二进制的过程又需要依赖ASCII编码,具体实现步骤如下
1、首先拆分一下,得到如下6个字符

2、此时按照将字符进行二进制的转换(此时用到了ASCII编码)

3、将二进制进行拼接串联

4、按照 6 位为单位进行分组

5、将分组的二进制转10进制

6、用10进制对照Base64编码表进行取值

base64编码总结:字符 → 转十进制 → 转二进制 → 以6位分组组成新的二进制组 → 十进制 → 转base64表字符
浏览器Base64编码结果对照:

至此已经实现Base64的编码流程推理,且得到了验证,同理进行解码的逻辑则相反,这里有一个点需要注意,就是最终的base64编码的长度需要是4的倍数,如果不是就要在结尾用
=补齐,这里的逻辑可以用HelloWorld去进行编码尝试最终的结果为SGVsbG9Xb3JsZA==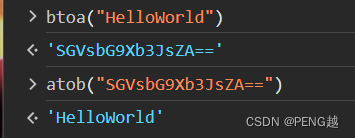
Base64 算法实现
首先需要实现的就是Base64编解码的定义,所以这里先定义一个常量用来存储base64的编码表,索引就是其value,这里合计65个字符,是因为把后续编码不足4位需要补
=的情况也考虑进来,直接放到编码表中,方便后续处理。// Base64编码表 const base64Table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/='; // Base64编码 export function encode(str) { console.log(str); } // Base64解码 export function decode(str) { }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Base64编码
处理最佳理想情况,输入字符为3个,转为4个整的base64字符
// Base64编码 export function encode(str) { let result = '' // 循环遍历字符串,每次处理3个字符 // 一个字符对应一个ASCII,一个ASCII对应8bit,总24bit,即3byte,一个base64为6bit // 因此3个输入字符为一组正好能转为4个base64字符 --> 3byte * 8 = 6bit * 4 for (let i = 0; i < str.length; i += 3) { // 分别计算每个字符对应的base64编码值 let char1 = str.charCodeAt(i) >> 2; // 取byte1前6位 let char2 = (str.charCodeAt(i) & 3) << 4 | str.charCodeAt(i + 1) >> 4; // 取byte1后2位+byte2前4位 let char3 = (str.charCodeAt(i + 1) & 15) << 2 | str.charCodeAt(i + 2) >> 6; // 取byte2后4位+byte3前2位 let char4 = str.charCodeAt(i + 2) & 63; // 取byte3的后6位 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这是非异常情况,进行编码的字符的二进制位数正好是能被6整除的情况,如果最终转换不足6位的话,按照base64的编码规则需要在后面加
=号进行填充,以确保编码后的长度是4的倍数具体来说,如果原始数据的字节数为1个字节,那么对应的Base64编码结果会有2个填充字符“=”;如果原始数据的字节数为2个字节,那么对应的Base64编码结果会有1个填充字符“=”。举例如下:

如果按照 abc 3个字符为1组 进行转码, 将得到
3 * 8bit,将正好转换为4 * 6的base64编码,也就是3个输入字符对应了4个base64编码字符,这也是为什么说经过base64编码后的数据长度会比之前多出1/3。因此,无论原始数据的长度如何,Base64编码后的结果字符串长度都会是4的倍数。
处理非理想情况
// Base64编码 export function encode(str) { let result = '' // 循环遍历字符串,每次处理3个字符 // 一个字符对应一个ASCII,一个ASCII对应8bit,总24bit,即3byte,一个base64为6bit // 因此3个输入字符为一组正好能转为4个base64字符 --> 3byte * 8 = 6bit * 4 for (let i = 0; i < str.length; i += 3) { // 分别计算每个字符对应的base64编码值 let char1 = str.charCodeAt(i) >> 2; // 取byte1前6位 let char2 = (str.charCodeAt(i) & 3) << 4 | str.charCodeAt(i + 1) >> 4; // 取byte1后2位+byte2前4位 let char3 = (str.charCodeAt(i + 1) & 15) << 2 | str.charCodeAt(i + 2) >> 6; // 取byte2后4位+byte3前2位 let char4 = str.charCodeAt(i + 2) & 63; // 取byte3的后6位 // 判断是否需要填充(每次共处理3个输入字符,只需要判断是否存在第二与第三个字符) // 一个输入字符 8 bit,最起码会产生 2个 base64字符 if (isNaN(str.charCodeAt(i + 1))) { char3 = char4 = 64; // 第二个字符不存在时,填充末尾2个 = } else if (isNaN(str.charCodeAt(i + 2))) { char4 = 64 // 第三个字符不存在时,填充末尾1个 = } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
将转码的10进制数进行查表换取对应字符并返回
// Base64编码 export function encode(str) { let result = '' // 循环遍历字符串,每次处理3个字符 // 一个字符对应一个ASCII,一个ASCII对应8bit,总24bit,即3byte,一个base64为6bit // 因此3个输入字符为一组正好能转为4个base64字符 --> 3byte * 8 = 6bit * 4 for (let i = 0; i < str.length; i += 3) { // 分别计算每个字符对应的base64编码值 let char1 = str.charCodeAt(i) >> 2; // 取byte1前6位 let char2 = (str.charCodeAt(i) & 3) << 4 | str.charCodeAt(i + 1) >> 4; // 取byte1后2位+byte2前4位 let char3 = (str.charCodeAt(i + 1) & 15) << 2 | str.charCodeAt(i + 2) >> 6; // 取byte2后4位+byte3前2位 let char4 = str.charCodeAt(i + 2) & 63; // 取byte3的后6位 // 判断是否需要填充(每次共处理3个输入字符,只需要判断是否存在第二与第三个字符) // 一个输入字符 8 bit,最起码会产生 2个 base64字符 if (isNaN(str.charCodeAt(i + 1))) { char3 = char4 = 64; // 第二个字符不存在时,填充末尾2个 = } else if (isNaN(str.charCodeAt(i + 2))) { char4 = 64 // 第三个字符不存在时,填充末尾1个 = } result += base64Table.charAt(char1) + base64Table.charAt(char2) + base64Table.charAt(char3) + base64Table.charAt(char4) } return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
PS:
在编码的算法中,我使用的是charCodeAt()取获取该字符对应的Unicode 编码值,也就是对应的10进制,在推理图解的过程中,使用的是ASCII做举例。ASCII属于Unicode的子集,在JS中可以利用charCodeAt()拿到对应的10进制数
测试:

可以在实现编码算法后,进行
a、ab、abc的编码算法推理过程,将更好的了解其逻辑
对于输入字符
a的情况,进行str.charCodeAt(i + 1)时候会出现NaN,此时再进行移位操作,NaN会转为0,因此不会引发异常,在获取不到的情况下都会转为00000000,按位与00010000时,即为16,对应base64表为Q,后位字符都为NaN即为=,则最终结果为YQ==
Base64解码
经过base64的编码过程,解码就好处理多了,同理还是利用位计算还原逆推base64编码,将其对表进行转换
先处理异常字符情况
// Base64解码 export function decode(str) { let result = ''; let value1, value2, value3, value4; // 存储4个base64字符所对应的索引 let char1, char2, char3; // 存储解码后的3个原始字符 // 处理字符串中异常字符,仅保留base64字符 str = str.replace(/[^A-Za-z0-9+/=]/g, '') return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
借着按照4个字符一组取出base64的字符,并且取出对应value
// Base64解码 export function decode(str) { let result = ''; let value1, value2, value3, value4; // 存储4个base64字符所对应的索引 let char1, char2, char3; // 存储解码后的3个原始字符 // 处理字符串中异常字符,仅保留base64字符 str = str.replace(/[^A-Za-z0-9+/=]/g, '') for (let i = 0; i < str.length; i += 4) { // 从base64编码表中获取字符所对应的value value1 = base64Table.indexOf(str.charAt(i)); value2 = base64Table.indexOf(str.charAt(i + 1)); value3 = base64Table.indexOf(str.charAt(i + 2)); value4 = base64Table.indexOf(str.charAt(i + 3)); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
将4个base字符解码成3个原始字符
// Base64解码 export function decode(str) { let result = ''; let value1, value2, value3, value4; // 存储4个base64字符所对应的索引 let char1, char2, char3; // 存储解码后的3个原始字符 // 处理字符串中异常字符,仅保留base64字符 str = str.replace(/[^A-Za-z0-9+/=]/g, '') for (let i = 0; i < str.length; i += 4) { // 从base64编码表中获取字符所对应的value value1 = base64Table.indexOf(str.charAt(i)); value2 = base64Table.indexOf(str.charAt(i + 1)); value3 = base64Table.indexOf(str.charAt(i + 2)); value4 = base64Table.indexOf(str.charAt(i + 3)); // 将4个base64字符解码成3个原始字符 char1 = value1 << 2 | value2 >> 4; char2 = (value2 & 15) << 4 | value3 >> 2; char3 = (value3 & 3) << 6 | value4; // 这样会有bug // char1 = value1 << 2 | value2 >> 4; // char2 = value2 << 4 | value3 >> 2; // char3 = value3 << 6 | value4; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
需要注意的是,JavaScript 在 1995 年诞生的时候,Unicode 已经发布。因此 JavaScript 的作者 Brendan Eich 在设计之初就使用 Unicode 作为 JavaScript 的唯一编码方式。我们知道 Unicode 是一个字符集,具体的编码方式有 UTF-8,UTF-16,UTF-32 等等。 JavaScript 语言采用 Unicode 字符集,但是只支持一种编码方法,就是UTF-16。因此这样进行位运算之前,必须清空高位,不然进行左移时,高位会进位,并不会按照ASCII的8 bit 作为一个字符舍弃高位。虽然base64进行转换的时候是只有英文字符加数字等这种简单情况,但是进行转码的是JS的引擎所以需要注意这个问题。
举例:
如果将base64字符W进行解码时就有这个问题的出现,W对应的value是22,分析过程如下
可以发现这里是会进位的
最后进行解码字符拼接,这里同理需要考虑
=的情况,如果是=则是补位,无需拼接// Base64解码 export function decode(str) { let result = ''; let value1, value2, value3, value4; // 存储4个base64字符所对应的索引 let char1, char2, char3; // 存储解码后的3个原始字符 // 处理字符串中异常字符,仅保留base64字符 str = str.replace(/[^A-Za-z0-9+/=]/g, '') for (let i = 0; i < str.length; i += 4) { // 从base64编码表中获取字符所对应的value value1 = base64Table.indexOf(str.charAt(i)); value2 = base64Table.indexOf(str.charAt(i + 1)); value3 = base64Table.indexOf(str.charAt(i + 2)); value4 = base64Table.indexOf(str.charAt(i + 3)); // 将4个base64字符解码成3个原始字符 char1 = value1 << 2 | value2 >> 4; char2 = (value2 & 15) << 4 | value3 >> 2; char3 = (value3 & 3) << 6 | value4; // 解码后字符拼接(最少会有一个字符[依赖value1和value2]) result += String.fromCharCode(char1); if (value3 !== 64) result += String.fromCharCode(char2); if (value4 !== 64) result += String.fromCharCode(char3); } return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
以上就是最终实现了,下面开始测试
JS情况:
自写算法情况:
编码:

解码:

全字符编解码:

完整算法代码
// Base64编码表 const base64Table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/='; // Base64编码 export function encode(str) { let result = ''; // 循环遍历字符串,每次处理3个字符 // 一个字符对应一个ASCII,一个ASCII对应8bit,总24bit,即3byte,一个base64为6bit // 因此3个输入字符为一组正好能转为4个base64字符 --> 3byte * 8 = 6bit * 4 for (let i = 0; i < str.length; i += 3) { // 分别计算每个字符对应的base64编码值 let char1 = str.charCodeAt(i) >> 2; // 取byte1前6位 let char2 = (str.charCodeAt(i) & 3) << 4 | str.charCodeAt(i + 1) >> 4; // 取byte1后2位+byte2前4位 let char3 = (str.charCodeAt(i + 1) & 15) << 2 | str.charCodeAt(i + 2) >> 6; // 取byte2后4位+byte3前2位 let char4 = str.charCodeAt(i + 2) & 63; // 取byte3的后6位 // 判断是否需要填充(每次共处理3个输入字符,只需要判断是否存在第二与第三个字符) // 一个输入字符 8 bit,最起码会产生 2个 base64字符 if (isNaN(str.charCodeAt(i + 1))) { char3 = char4 = 64; // 第二个字符不存在时,填充末尾2个 = } else if (isNaN(str.charCodeAt(i + 2))) { char4 = 64; // 第三个字符不存在时,填充末尾1个 = } result += base64Table.charAt(char1) + base64Table.charAt(char2) + base64Table.charAt(char3) + base64Table.charAt(char4); } return result; } // Base64解码 export function decode(str) { let result = ''; let value1, value2, value3, value4; // 存储4个base64字符所对应的索引 let char1, char2, char3; // 存储解码后的3个原始字符 // 处理字符串中异常字符,仅保留base64字符 str = str.replace(/[^A-Za-z0-9+/=]/g, '') for (let i = 0; i < str.length; i += 4) { // 从base64编码表中获取字符所对应的value value1 = base64Table.indexOf(str.charAt(i)); value2 = base64Table.indexOf(str.charAt(i + 1)); value3 = base64Table.indexOf(str.charAt(i + 2)); value4 = base64Table.indexOf(str.charAt(i + 3)); // 将4个base64字符解码成3个原始字符 char1 = value1 << 2 | value2 >> 4; char2 = (value2 & 15) << 4 | value3 >> 2; char3 = (value3 & 3) << 6 | value4; // 解码后字符拼接(最少会有一个字符[依赖value1和value2]) result += String.fromCharCode(char1); if (value3 !== 64) result += String.fromCharCode(char2); if (value4 !== 64) result += String.fromCharCode(char3); } return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
uni演示项目gitee仓库:
https://gitee.com/pengyue82/JS-base64
总结:其实本来没想写,GPT完全可以搞定,且网上方案一堆,但是想重拾CS的热情,当年学C的时候确实这些计算都笔算的很熟练,所以只是把逻辑组合就好了,虽然现在基本上用不着自己造轮子,但是推理的过程仍然十分有趣
PS:如果文中有理论错误问题,烦请指导,感谢 -
相关阅读:
ExpressGridPack 23 Crack
day61
【数据结构】图的存储结构(邻接矩阵)
Centos7 升级mariadb5.5到10.4
动态规划-矩阵连乘
理解linux进程
苹果审核:2.1性能完整性被拒解决
专利的黑白图片处理:
Nacos源码分析专题(一)-环境准备
“传统技术”快速搭建AI产品的利器——LLM技术
- 原文地址:https://blog.csdn.net/qq_44718932/article/details/136401265
