k近邻模型
基本思想
其本质思想是将特征空间划分成一个个的单元(

如上图所示:
考虑样本
- 对于
- 对于
- 对于
- 对于
因此,
再考虑样本
- 对于
- 对于
- 对于
- 对于
因此,
同理我们可以得到
这样一来,有所有
上面只是理想中的方式,是一种辅助理解的办法,存在诸多问题,比如区域不好定义,上面的示例中我们只是规定了一个
在实际中,我们往往直接使用与每个样本
其中
曼哈顿距离(L1范数):
三种距离在二维空间中的等距图如下:

对于
kd树
从上面的介绍可知,若想找去每个样本的
平衡树的建立
假设样本为
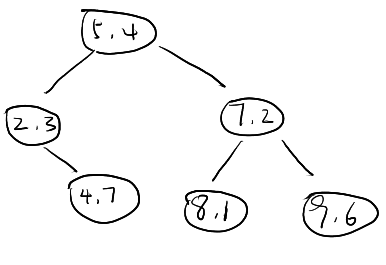
示例:
有以下二维空间中的数据集,要求建立一个
首先让所有样本在
得到中位数
因此得到
继续构建下一层
对于
对于
至此,原始样本的对应的平衡
下面是图例:
树的查找
树的查找包括正向和反向两个过程,正向和建树类似只需一一判断即可,反向也是必须的,因为正向过程不能保证所查找到的一定是其最近邻(需要参见
- 正向递归查找。当给出一个样本在查找与它的最近邻样本时(限定
- 反向回溯查找。在得到正向查找中与样本点
示例:
我们考虑比机器学习课本更复杂一些的情况,如下。
首先我们容易根据正向查到找到样本点
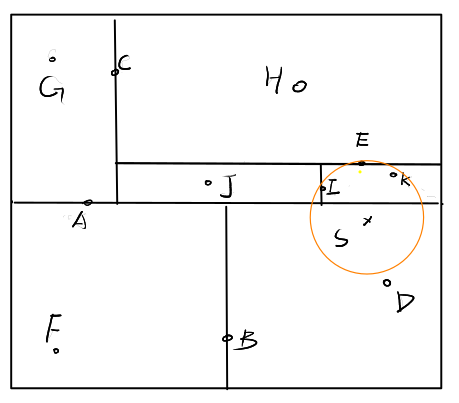
继续检查