-
C及C++每日练习(2)
1.选择:
1.使用printf函数打印一个double类型的数据,要求:输出为10进制,输出左对齐30个字符,4位精度。以下哪个选项是正确的?
A.%-30.4e B.%4.30e C.%-30.4f D.%-4.30
在上一篇文章中,提到了对于打印字符串时,其打印模板%
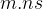 中各个字母的含义,对于
中各个字母的含义,对于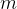 ,表示输出的字符串的宽度,对于
,表示输出的字符串的宽度,对于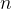 表示在打印时,打印左起字符串的前个字符。并且是右对齐,且字符不足时会自动补充空格。当字符串长度
表示在打印时,打印左起字符串的前个字符。并且是右对齐,且字符不足时会自动补充空格。当字符串长度 时,失效,当
时,失效,当 字符串长度时,直接打印到结尾。
字符串长度时,直接打印到结尾。对于本题,则是考察对于数字的打印格式。对于打印十进制的
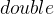 ,采用的格式是%
,采用的格式是%
对于题目中的%
 ,是表示按照指数类型打印。
,是表示按照指数类型打印。对于对齐问题,主要由
控制,表示右对齐打印个字符。但是题目中要求左对齐,因此需要采用 的形式。对于,主要用于控制打印精度,即表示打印到小数点的后位。
的形式。对于,主要用于控制打印精度,即表示打印到小数点的后位。因此,对于本体题目要求,对应答案
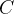
2.请找出下面程序中有哪些错误()
- int main(){
- int i = 10;
- int j = 1;
- const int *p1;//(1)
- int const *p2 = &i; //(2)
- p2 = &j;//(3)
- int *const p3 = &i;//(4)
- *p3 = 20;//(5)
- *p2 = 30;//(6)
- p3 = &j;//(7)
- return 0;
- }
A.1,2,3,4,5,6,7
B. 1,3,5,6
C.6,7
D.3,5
在正式讲解题目之前,首先需要介绍两个概念,即:指针常量、常量指针。
对于常量指针:表示指针指向的内容是常量内容,因此,指针指向的内容不能被修改,也就是说,不能通过解引用的方式来改变指针指向的内容,但是,可以改变指针本身的指向。
对于指针常量:表示指针本身就是一个常量,指针的指向不能发生更改,但是可以通过解引用的方式改变空间中内容。
而对于如何区分指针常量和常量指针,可以通过
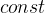 和
和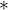 的相对位置来判断。
的相对位置来判断。例如,对于题目中的
 ,
, 因为在前面,所以表示常量指针,即:
因为在前面,所以表示常量指针,即: 指向的内容不能通过解引用进行修改,但是的指向可以修改。
指向的内容不能通过解引用进行修改,但是的指向可以修改。对于题目中的
 ,
, &
&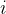 ,表示常量指针,与不同的是,此处进行了对于指针的初始化。
,表示常量指针,与不同的是,此处进行了对于指针的初始化。对于题目中的
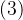 ,表示改变指针
,表示改变指针 的指向,由于是常量指针,故正确。
的指向,由于是常量指针,故正确。对于题目中的
 ,此时在前面,表示指针常量,即指针是一个常量,指针的指向不能被更改,但是指向的内容可以修改。
,此时在前面,表示指针常量,即指针是一个常量,指针的指向不能被更改,但是指向的内容可以修改。对于题目中的
 ,表示对指针
,表示对指针 解引用,更改指针指向的内容,由于是一个指针常量,因此,可以更改指针指向的内容。正确。
解引用,更改指针指向的内容,由于是一个指针常量,因此,可以更改指针指向的内容。正确。对于题目中的
 ,表示对指针解引用,修改指向的内容,由于指针式常量指针,即指针指向的内容是常量,可以修改指针的指向,但是不能更改指针指向的内容,因此错误。
,表示对指针解引用,修改指向的内容,由于指针式常量指针,即指针指向的内容是常量,可以修改指针的指向,但是不能更改指针指向的内容,因此错误。对于题目中的
 ,表示更改的指向,由于指针是指针常量,因此,指针指向不能被改变,所以错误。
,表示更改的指向,由于指针是指针常量,因此,指针指向不能被改变,所以错误。因此答案选择
3.下面叙述错误的是()
- char acX[]="abc";
- char acY[]={'a','b','c'};
- char *szX="abc";
- char *szY="abc";
A.acX与acY的内容可以修改
B. szX与szY指向同一个地址
C.acX占用的内存空间比acY占用的大
D. szX的内容修改后,szY的内容也会被更改
对于代码的前两行,都是创建一个常量字符串,只不过采取的放肆不同,不过需要注意,在第一行代码中,由于是一个完整的字符串,因此,在字符串的末尾带有字符串的结束标志" role="presentation" style="position: relative;">\0。但是第二行代码中,并不存在这个结束标志,因此,对于
选项, 的大小大于
的大小大于 的大小。
的大小。对于
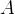 选项,可以通过数组下标进行更改,正确。
选项,可以通过数组下标进行更改,正确。对于
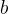 选项,由于两个指针指向的内容相同,因此正确。
选项,由于两个指针指向的内容相同,因此正确。对于
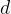 选项,需要注意,题目说的是改变指针
选项,需要注意,题目说的是改变指针 的内容,也就是修改指针指向的地址,并不是修改其指向的内容。所以错误。
的内容,也就是修改指针指向的地址,并不是修改其指向的内容。所以错误。因此选择
4.在头文件及上下文均正常的情况下,下列代码的运行结果是()
- int a[] = {1, 2, 3, 4};
- int *b = a;
- *b += 2;
- *(b + 2) = 2;
- b++;
- printf("%d,%d\n", *b, *(b + 2));
A.1,3
B. 1,2
C.2,4
D.3,2
对于上述代码,首秀按创建了一个指针
,指向了数组的起始地址。随后,对于 ,需要注意,由于的结合优先级高于
,需要注意,由于的结合优先级高于 ,因此,这句代码表示的含义是,解引用,拿到数组中第一个数,随后对这个数
,因此,这句代码表示的含义是,解引用,拿到数组中第一个数,随后对这个数 ,因此,此时的数组为:
,因此,此时的数组为:int a[] = {3, 2, 3, 4};对于
 ,则是表示针对指针的地址进行加
,则是表示针对指针的地址进行加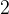 ,由于指针的类型为
,由于指针的类型为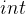 ,因此表示跳过
,因此表示跳过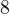 字节,对跳过后的地址进行解引用,再将这个值修改为。因此,此时的数组为:
字节,对跳过后的地址进行解引用,再将这个值修改为。因此,此时的数组为:int a[] = {3, 2, 2, 4};对于
 ,表示修改指针,使得其指向数组中的第二个元素的地址。
,表示修改指针,使得其指向数组中的第二个元素的地址。因此,再打印时,指针
指向数组中第二个元素的下标,此时进行打印,打印的值分别为 ,答案选择。
,答案选择。5. 用变量a给出下面的定义:一个有10个指针的数组,该指针指向一个函数,该函数有一个整形参数并返回一个整型数()
A. int *a[10];
B. int (*a)[10];
C. int (*a)(int);
D. int (*a[10])(int);
本题目涉及到了三个概念:数组指针,指针数组,函数指针,对于数组指针。对于前二者的判断,只需要知道
的结合优先级大于
即可。例如对于选项
,由于结合性问题,因此首先表示一个数组,数组的容量为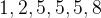 ,其中保存了个
,其中保存了个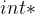 类型的变量,因此表示指针数组。
类型的变量,因此表示指针数组。对于选项
,首先表示一个指针,这个指针指向了一个数组,数组可以存储个类型的变量,因此是数组指针。对于选项
,表示一个指针,外部的括号 是函数指针的标志,因此表示一个函数,参数为一个整型参数。返回值类型为
是函数指针的标志,因此表示一个函数,参数为一个整型参数。返回值类型为对于选项
,首先表示一个数组,这个数组存储的变量为指针,且指针为函数指针,返回值为整型,参数为一个整型参数,所以答案选择6.在32位cpu上选择缺省对齐的情况下,有如下结构体定义:
- struct A
- {
- unsigned a : 19;
- unsigned b : 11;
- unsigned c : 4; unsigned d : 29;
- char index;
- };
则sizeof(struct A)的值为()
A.9 B. 12 C.16 D.20
需要注意,此时的变量是以位断的形式定义的,冒号后面的数组表示这个变量占有多少比特位。
对于一个
 类型的变量,大小为
类型的变量,大小为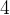 字节,因此会开辟字节,即
字节,因此会开辟字节,即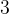 比特位大小的空间,由于占有的比特位小于,因此对于二者只会开辟一次字节大小的空间。
比特位大小的空间,由于占有的比特位小于,因此对于二者只会开辟一次字节大小的空间。对于
,由于此时第一次开辟的空间大小不足,因此会在开辟字节大小的空间。对于,由于此时的空间再次不足,因此会第三次开辟字节空间。对于
 ,由于类型不同,因此会再开辟
,由于类型不同,因此会再开辟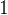 字节的空间。
字节的空间。最后,因为存在内存对齐机制,因此总空间大小必须是最大对齐数的整数倍,因此答案选择
。7.下面代码会输出()
- int main(){
- int a[4]={1,2,3,4};
- int *ptr=(int*)(&a+1);
- printf("%d",*(ptr-1));
- }
A.4 B. 1 C.2 D.3
对于数组名,如果于
 &结合,则表示整个数组,其他情况下均表示数组首元素地址。因此,此处的&
&结合,则表示整个数组,其他情况下均表示数组首元素地址。因此,此处的& ,表示跳过整个数组长度的内容。即数组最后一个内容的下一个位置。对于
,表示跳过整个数组长度的内容。即数组最后一个内容的下一个位置。对于 ,由于指针的类型,因此为指向前四个字节的内容,也就是指向数组的最后一个元素的地址。,因此选择
,由于指针的类型,因此为指向前四个字节的内容,也就是指向数组的最后一个元素的地址。,因此选择2. 编程:
2.1 倒置字符串:

原理较为简单,首先将给定的字符串整体进行逆置,例如对于图中给出的字符串,整体逆置后如下:

对于本题,可采用双指针法进行解决。具体解法如下:
创建两个指针,分别为
,在最开始,两个指针均指向字符串的开头。这里由于使用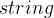 类创建一个对象
类创建一个对象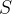 用于存放字符串,因此:
用于存放字符串,因此: 。
。建立循环,循环的条件是

如果
 的位置不指向字符串的结束位置,即:最后一个字符的下一个位置。并且对于
的位置不指向字符串的结束位置,即:最后一个字符的下一个位置。并且对于 ,即不等于空,则让指向下一个位置。
,即不等于空,则让指向下一个位置。如果
 ,则将两个指针区域内的字符串再次逆置。在逆置后,这里有两种情况,一是
,则将两个指针区域内的字符串再次逆置。在逆置后,这里有两种情况,一是 ,则令
,则令 ,再令
,再令 即可。如果
即可。如果 ,则表示,已经将整个字符串遍历结束,直接令即可。此时
,则表示,已经将整个字符串遍历结束,直接令即可。此时 ,循环结束,输出字符串即可。对应代码如下:
,循环结束,输出字符串即可。对应代码如下:- #include
- #include
- #include
- using namespace std;
- int main()
- {
- string s1;
- getline(cin,s1);
- reverse(s1.begin(),s1.end());
- auto start = s1.begin();
- while(start != s1.end())
- {
- auto end = start;
- while(*end != ' ' && end != s1.end())
- {
- end++;
- }
- reverse(start,end);
- if(end != s1.end())
- {
- start = end+1;
- }
- else {
- start = end;
- }
- }
- cout << s1;
- return 0;
- }
2.2 排序子序列:
排序子序列_牛客笔试题_牛客网 (nowcoder.com)

在给出题解之前,首先解释以下题目中提出的两个概念,即:非递增序列,非递减序列。
对于非递增序列,可以看作不严格的递增序列,即存在前后相等元素的递增序列,例如:

对于非递减序列,可以看作不严格的递减序列,即存在前后相等元素的递减序列,例如:

对于本题目的解法,首先利用
 实例化出对象
实例化出对象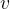 来接收输入元素,利用变量接收输入元素数量:
来接收输入元素,利用变量接收输入元素数量:如果
![v[i] <v[i+1]](https://1000bd.com/contentImg/2024/03/08/051330614.png) ,则表示数组进入了非递增序列。
,则表示数组进入了非递增序列。如果
![v[i] >v[i+1]](https://1000bd.com/contentImg/2024/03/08/051330617.png) ,则表示数组进入了非递减序列
,则表示数组进入了非递减序列对于
![v[i]==v[i+1]](https://1000bd.com/contentImg/2024/03/08/051330656.png) 的情况,指向下一个元素即可。不做处理
的情况,指向下一个元素即可。不做处理如果数组进入了上述序列,需要继续判断,如果出现了相反的情况,例如在非递增序列中,出现了
![v[i] > v[i+1]](https://1000bd.com/contentImg/2024/03/08/051330654.png) ,则表示这部分的数据不再满足非递增性,此时前面的数据构成了一个完成的非递增序列,因此让记录排序子序列数量的变量
,则表示这部分的数据不再满足非递增性,此时前面的数据构成了一个完成的非递增序列,因此让记录排序子序列数量的变量 ++,再令++,作为另一种序列的首个元素。如果没有出现相反的情况,则表示目前数据依旧满足非递增行,需要检测下一个数据,再令++即可。
++,再令++,作为另一种序列的首个元素。如果没有出现相反的情况,则表示目前数据依旧满足非递增行,需要检测下一个数据,再令++即可。不过对于条件的判断需要注意,对于下面的情况:
 ,因为上面给出的序列是一个递增序列,因此当
,因为上面给出的序列是一个递增序列,因此当 时,此时
时,此时![v[i]==3,v[i+1]==4](https://1000bd.com/contentImg/2024/03/08/051330623.png) ,然后令++,此时,对于
,然后令++,此时,对于![v[i+1]](https://1000bd.com/contentImg/2024/03/08/051330023.png) 会造成越界访问的问题。为了方便的解决这个问题,可以在实例化出对象后,利用
会造成越界访问的问题。为了方便的解决这个问题,可以在实例化出对象后,利用 函数,扩容
函数,扩容 数量的空间,并且将这些空间初始化为
数量的空间,并且将这些空间初始化为 。具体代码如下:
。具体代码如下:
- #include
- #include
- using namespace std;
- int main() {
- int n = 0;
- cin >> n;
- vector<int> v;
- v.resize(n+1,0);
- for( int i = 0; i < n; i++)
- {
- cin >> v[i];
- }
- int count = 0;
- int i = 0;
- while( i < n)
- {
- //进入非递减
- if( v[i] < v[i+1])
- {
- while( i < n && v[i] <= v[i+1])
- {
- i++;
- }
- count++;
- i++;
- }
- else if( v[i] == v[i+1])
- {
- i++;
- }
- else
- {
- while( i < n && v[i] >= v[i+1])
- {
- i++;
- }
- count++;
- i++;
- }
- }
- cout << count;
- return 0;
- }
-
相关阅读:
leetcode-1678-设计 Goal 解析器(简单,基本逻辑)
iOS苹果签名共享签名是什么以及如何获取?
Linux文件目录以及文件类型
频控阵(FDA)信号检测
SpringMVC使用(注解、获取各种参数的方式、视图模板、文件上传下载、国际化、RestFul)
Leetcode.965 单值二叉树
Maven
python性能提升之字符串拼接、字节流拼接
全网最全Python系列教程(非常详细)---字符串讲解(学Python入门必收藏)
生成的二维码如何解析出原来的地址?
- 原文地址:https://blog.csdn.net/2301_76836325/article/details/136465332
