-
机器学习复习(8)——逻辑回归
- ### numpy版本为1.20.3
- import numpy as np
- ### 定义sigmoid函数
- def sigmoid(x):
- z = 1 / (1 + np.exp(-x))
- return z
- # 定义参数初始化函数
- def initialize_params(dims):
- W = np.zeros((dims, 1))#初始化W为0
- b = 0
- return W, b
- X: 输入特征矩阵,大小为 m×n,其中 m 是样本数量,n 是特征数量。
- y: 输出标签向量,大小为 m×1,包含每个样本的真实标签(0或1)。
- W: 权值参数,大小为 n×1,代表特征权重。
- b: 偏置参数,是一个标量,代表模型的偏置项。
- ### 定义对数几率回归模型主体
- def logistic(X, y, W, b):
- '''
- 输入:
- X: 输入特征矩阵
- y: 输出标签向量
- W: 权值参数
- b: 偏置参数
- 输出:
- a: 逻辑回归模型输出
- cost: 损失
- dW: 权值梯度
- db: 偏置梯度
- '''
- # 训练样本量
- num_train = X.shape[0]
- # 训练特征数
- num_feature = X.shape[1]
- # 逻辑回归模型输出
- a = sigmoid(np.dot(X, W) + b)
- # 交叉熵损失
- cost = -1/num_train * np.sum(y*np.log(a) + (1-y)*np.log(1-a))
- # 权值梯度
- dW = np.dot(X.T, (a-y))/num_train#dot()函数是矩阵乘法,eg:[n,m]@[m,p]=[n,p]
- # 偏置梯度
- db = np.sum(a-y)/num_train
- # 压缩损失数组维度
- cost = np.squeeze(cost) #压缩损失值的维度,以确保输出的损失值是一个标量而不是一个数组。例如:[[3.]]变成了3.0
- return a, cost, dW, db#返回逻辑回归模型输出、损失、权值梯度、偏置梯度
-
模型输出(a)的计算:使用sigmoid函数作为激活函数,计算模型的输出。公式为
 ,其中 σ 是sigmoid函数,它将线性回归输出转换为概率值(介于0和1之间)。
,其中 σ 是sigmoid函数,它将线性回归输出转换为概率值(介于0和1之间)。 -
交叉熵损失(cost)的计算:使用交叉熵损失函数来衡量模型预测值与真实值之间的差异。对于二分类问题,交叉熵损失的公式为
![-\frac1m\sum_{i=1}^m[y^{(i)}\log(a^{(i)})+(1-y^{(i)})\log(1-a^{(i)})]](https://1000bd.com/contentImg/2024/03/06/042150119.png) ,其中 m 是样本数量。这个损失函数针对每个样本计算预测值与实际值的差异,然后取平均值。
,其中 m 是样本数量。这个损失函数针对每个样本计算预测值与实际值的差异,然后取平均值。 -
权值梯度(dW)和偏置梯度(db)的计算:这两个梯度用于根据损失函数的梯度下降法更新权值和偏置。权值梯度计算公式为
 ,偏置梯度计算公式为
,偏置梯度计算公式为  。这里,
。这里, 是特征矩阵的转置,确保梯度与权重矩阵的维度一致。
是特征矩阵的转置,确保梯度与权重矩阵的维度一致。 -
损失压缩:最后,使用
np.squeeze(cost)压缩损失值的维度,以确保输出的损失值是一个标量而不是一个数组。
- ### 定义对数几率回归模型训练过程
- def logistic_train(X, y, learning_rate, epochs):
- '''
- 输入:
- X: 输入特征矩阵
- y: 输出标签向量
- learning_rate: 学习率
- epochs: 训练轮数
- 输出:
- cost_list: 损失列表
- params: 模型参数
- grads: 参数梯度
- '''
- # 初始化模型参数
- W, b = initialize_params(X.shape[1]) #X.shape[1]表示特征数
- # 初始化损失列表
- cost_list = []
- # 迭代训练
- for i in range(epochs):
- # 计算当前次的模型计算结果、损失和参数梯度
- a, cost, dW, db = logistic(X, y, W, b)
- # 参数更新
- W = W -learning_rate * dW
- b = b -learning_rate * db
- # 记录损失
- if i % 100 == 0:
- cost_list.append(cost)
- # 打印训练过程中的损失
- if i % 100 == 0:
- print('epoch %d cost %f' % (i, cost))
- # 保存参数
- params = {
- 'W': W,
- 'b': b
- }
- # 保存梯度
- grads = {
- 'dW': dW,
- 'db': db
- }
- return cost_list, params, grads
- ### 定义预测函数
- def predict(X, params):
- '''
- 输入:
- X: 输入特征矩阵
- params: 训练好的模型参数
- 输出:
- y_prediction: 转换后的模型预测值
- '''
- # 模型预测值
- y_prediction = sigmoid(np.dot(X, params['W']) + params['b'])#模型预测值
- # 基于分类阈值对概率预测值进行类别转换
- for i in range(len(y_prediction)):
- if y_prediction[i] > 0.5:
- y_prediction[i] = 1
- else:
- y_prediction[i] = 0
- return y_prediction
输入参数
- X: 输入特征矩阵,大小m×n,其中 m 是样本数量,n 是特征数量。这代表要进行预测的新数据集。
- params: 训练好的模型参数,是一个字典,包含了权重 W 和偏置 b。其中,W 是权值参数,大小为 n×1,而 b 是偏置参数,是一个标量。
输出参数
- y_prediction: 转换后的模型预测值,是一个大小为 m×1 的向量,包含了对每个样本的二分类预测结果(0或1)。
-
模型预测值的计算:首先,函数使用sigmoid函数计算模型的预测概率。这一步是通过对输入特征矩阵 X 和模型参数 W 进行矩阵乘法,然后加上偏置 b,并将结果通过sigmoid函数转换为概率值。计算公式为
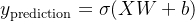 ,其中 σ 是sigmoid函数。
,其中 σ 是sigmoid函数。 -
概率到分类的转换:接下来,函数遍历预测概率向量
 ,将每个概率值与分类阈值(通常为0.5)进行比较。如果概率值大于0.5,则将该样本的预测类别设置为1(表示属于正类);如果概率值小于或等于0.5,则将预测类别设置为0(表示属于负类)。这个步骤将连续的概率预测转换为明确的类别预测,便于后续的分类任务。
,将每个概率值与分类阈值(通常为0.5)进行比较。如果概率值大于0.5,则将该样本的预测类别设置为1(表示属于正类);如果概率值小于或等于0.5,则将预测类别设置为0(表示属于负类)。这个步骤将连续的概率预测转换为明确的类别预测,便于后续的分类任务。 -
返回预测结果:最后,函数返回转换后的预测值
。
- # 导入matplotlib绘图库
- import matplotlib.pyplot as plt
- # 导入生成分类数据函数
- # from sklearn.datasets.samples_generator import make_classification
- from sklearn.datasets import make_classification
- # 生成100*2的模拟二分类数据集
- X, labels = make_classification(
- n_samples=100,
- n_features=2,
- n_redundant=0,
- n_informative=2,
- random_state=1,
- n_clusters_per_class=2)
- # 设置随机数种子
- rng = np.random.RandomState(2)
- # 对生成的特征数据添加一组均匀分布噪声
- X += 2 * rng.uniform(size=X.shape)
- # 标签类别数
- unique_lables = set(labels)
- # 根据标签类别数设置颜色
- colors = plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))
- # 绘制模拟数据的散点图
- for k,col in zip(unique_lables, colors):
- x_k=X[labels==k]
- plt.plot(x_k[:,0],x_k[:,1],'o',markerfacecolor=col,markeredgecolor="k",
- markersize=14)
- plt.title('Simulated binary data set')
- plt.show();

- print(X.shape, labels.shape)
- labels = labels.reshape((-1, 1))
- data = np.concatenate((X, labels), axis=1)
- print(data.shape)
- # 训练集与测试集的简单划分
- offset = int(X.shape[0] * 0.9)
- X_train, y_train = X[:offset], labels[:offset]
- X_test, y_test = X[offset:], labels[offset:]
- y_train = y_train.reshape((-1,1))
- y_test = y_test.reshape((-1,1))
- print('X_train=', X_train.shape)
- print('X_test=', X_test.shape)
- print('y_train=', y_train.shape)
- print('y_test=', y_test.shape)
- cost_list, params, grads = logistic_train(X_train, y_train, 0.01, 1000)
- y_pred = predict(X_test, params)
- print(y_pred)
- sigmoid(np.dot(X_test, params['W']) + params['b'])
- from sklearn.metrics import accuracy_score, classification_report
- # print(accuracy_score(y_test, y_pred))
- print(classification_report(y_test, y_pred))
- def accuracy(y_test, y_pred):
- correct_count = 0
- for i in range(len(y_test)):
- for j in range(len(y_pred)):
- if y_test[i] == y_pred[j] and i == j:
- correct_count +=1
- accuracy_score = correct_count / len(y_test)
- return accuracy_score
- accuracy_score_test = accuracy(y_test, y_pred)
- print(accuracy_score_test)
- y_train_pred = predict(X_train, params)
- accuracy_score_train = accuracy(y_train, y_train_pred)
- print(accuracy_score_train)
- ### 绘制逻辑回归决策边界
- def plot_decision_boundary(X_train, y_train, params):
- '''
- 输入:
- X_train: 训练集输入
- y_train: 训练集标签
- params:训练好的模型参数
- 输出:
- 决策边界图
- '''
- # 训练样本量
- n = X_train.shape[0]
- # 初始化类别坐标点列表
- xcord1 = []
- ycord1 = []
- xcord2 = []
- ycord2 = []
- # 获取两类坐标点并存入列表
- for i in range(n):
- if y_train[i] == 1:
- xcord1.append(X_train[i][0])
- ycord1.append(X_train[i][1])
- else:
- xcord2.append(X_train[i][0])
- ycord2.append(X_train[i][1])
- # 创建绘图
- fig = plt.figure()
- ax = fig.add_subplot(111)
- # 绘制两类散点,以不同颜色表示
- ax.scatter(xcord1, ycord1,s=32, c='red')
- ax.scatter(xcord2, ycord2, s=32, c='green')
- # 取值范围
- x = np.arange(-1.5, 3, 0.1)
- # 决策边界公式
- y = (-params['b'] - params['W'][0] * x) / params['W'][1]
- # 绘图
- ax.plot(x, y)
- plt.xlabel('X1')
- plt.ylabel('X2')
- plt.show()
- plot_decision_boundary(X_train, y_train, params)
- from sklearn.linear_model import LogisticRegression
- clf = LogisticRegression(random_state=0).fit(X_train, y_train)
- y_pred = clf.predict(X_test)
- print(classification_report(y_test, y_pred))
-
相关阅读:
安全物理环境(设备和技术注解)
1990-2021年上市公司债务融资成本数据(原始数据+stata处理代码+计算结果)
[附源码]计算机毕业设计JAVA 宠物医院管理系统
shell循环语句
软件版本号详解
基于MobileNet的轻量级卷积神经网络实现玉米螟虫不同阶段识别分析
JavaScript垃圾回收机制
「开源系统」mybatis-plus代码生成工具(自己基于官方的封装的,打包成了maven插件的方式)
Angular 由一个bug说起之四:jsonEditor使用不当造成的bug
记:谷歌开发者大会2022——共码未来
- 原文地址:https://blog.csdn.net/xty123abc/article/details/136422886