-
LoRA Land:性能优于 GPT-4 的微调开源 LLMs
我们很高兴发布 LoRA Land,这是 25 个经过微调的 Mistral-7b 模型的集合,根据任务的不同,它们的性能始终比基本模型高出 70%,GPT-4 高出 4-15%。LoRA Land 的 25 个任务专用大型语言模型 (LLMs) 都使用 Predibase 进行了微调,平均每个模型不到 8.00 美元,并且都使用 LoRAX 从单个 A100 GPU 提供服务,LoRAX 是我们的开源框架,允许用户在单个 GPU 上提供数百个基于适配器的微调模型。这一系列专门的微调模型(全部使用相同的基础模型进行训练)为寻求高效且经济高效地部署高性能 AI 系统的团队提供了蓝图。
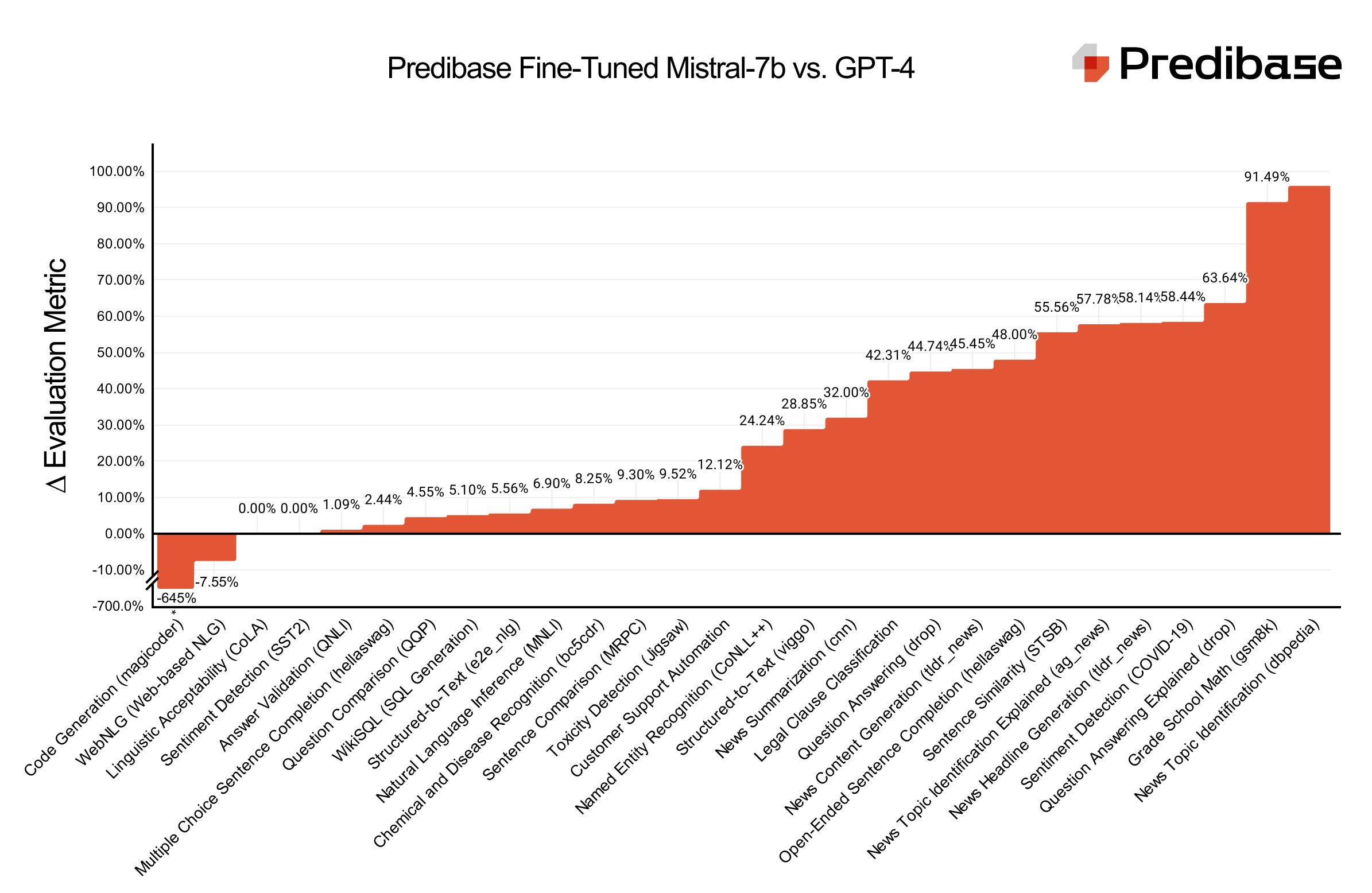
LLM基准测试:25 个经过微调的 Mistral-7b 适配器,性能优于 GPT-4。
需要高效的微调和服务
随着基于 Transformer 的预训练语言模型 (PLM) 参数数量的持续增长以及具有数十亿个参数的大型语言模型 (LLMs) 的出现,使其适应特定的下游任务变得越来越具有挑战性,尤其是在计算资源或预算有限的环境中。参数高效微调 (PEFT) 和量化低秩自适应 (QLoRA) 通过减少微调参数的数量和内存使用量,同时实现与完全微调相当的性能,提供了一种有效的解决方案。
Predibase 已将这些最佳实践整合到其微调平台中,为了证明基于适配器的开源微调的可访问性和可负担性,就 GPU 成本而言LLMs,已经微调了 25 个模型,每个模型的平均成本不到 8 美元。
从历史上LLMs看,微调投入生产和服务的成本也非常高,每个微调模型都需要专用的 GPU 资源。对于计划部署多个微调模型以解决一系列用例的团队来说,这些 GPU 费用通常可能是创新的瓶颈。LoRAX 是由 Predibase LLMs 开发的用于提供微调服务的开源平台,它使团队能够部署数百个微调,LLMs而成本仅为一个 GPU。

无服务器微调端点:经济高效地在单个 GPU 上提供 100 个服务LLMs。
通过将 LoRAX 构建到 Predibase 平台中并从单个 GPU 为许多微调模型提供服务,Predibase 能够为客户提供无服务器微调端点,这意味着用户不需要专用的 GPU 资源来提供服务。这样可以:
- 显著节省成本:只需按实际使用量付费。当您不需要专用 GPU 时,无需再为其付费。
- 可扩展的基础设施:LoRAX 使 Predibase 的服务基础设施能够随着您的 AI 计划而扩展。无论您是测试一个微调模型,还是在生产环境中部署一百个模型,我们的基础设施都能满足您的需求。
- 即时部署和提示:无需等待冷 GPU 启动后再提示每个微调的适配器,您可以更快地测试和迭代模型。
Predibase 中内置的这些基础技术和微调最佳实践大大简化了创建此微调集合的过程LLMs。正如你所看到的,我们能够创建这些特定于任务的模型,这些模型的性能优于 GPT-4,大部分是开箱即用的训练配置。
方法论
我们首先选择了具有代表性的数据集,然后使用 Predibase 对模型进行了微调并分析了结果。我们将更详细地介绍每个步骤。
数据集选择
我们从广泛可用的数据集中选择数据集,这些数据集通常用于基准测试或作为行业任务的代理。反映行业常见任务的数据集包括内容审核 (Jigsaw)、SQL 生成 (WikiSQL) 和情感分析 (SST2)。我们还包括了对研究中更常评估的数据集的评估,例如用于 NER 的 CoNLL++、用于问题比较的 QQP 等等。我们微调的任务从经典文本生成到更结构化的输出和分类任务。
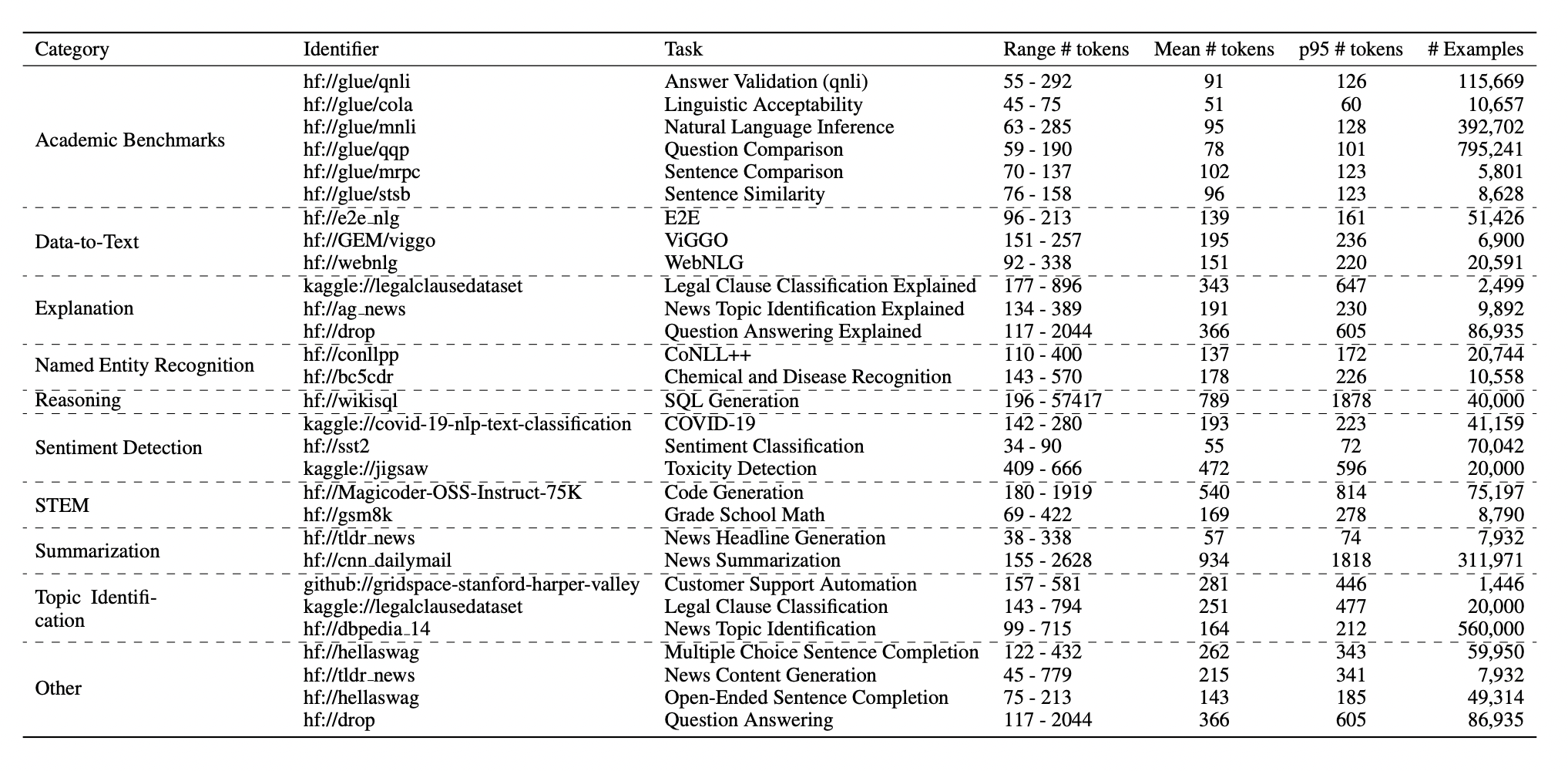
LoRA Land 数据集表,涵盖学术基准、摘要、代码生成等。输入文本的长度因任务而异,从相对较短的文本到超长的文档不等。许多数据集表现出长尾分布,其中少数样本的序列明显长于平均值。为了在容纳较长的序列和保持计算效率之间取得平衡,我们选择使用最大文本长度的 p95 百分位数来训练模型。
我们根据已公布的训练-验证-测试分割(如果可用)定义固定拆分以提高可重复性。
培训配置模板
Predibase 建立在开源 Ludwig 框架之上,这使得通过简单的配置 YAML 文件定义微调任务成为可能。我们通常不动 Predibase 中的默认配置,主要专注于编辑提示模板和输出。虽然 Predibase 允许用户手动指定各种微调参数,但默认值已通过微调 100 多个模型来优化,以最大限度地提高大多数开箱即用任务的性能。
以下是我们使用的配置之一的示例:
prompt: template: >- FILL IN YOUR PROMPT TEMPLATE HERE output_feature: label_and_explanation preprocessing: split: type: fixed column: split adapter: type: lora quantization: # Uses bitsandbytes. bits: 4 base_model: mistralai/Mistral-7b-v0.1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
简单的 YAML 模板,用于微调 Mistral 模型的 LoRA 适配器。
提示选择
在微调 时,LLM用户可以定义一个提示模板以应用于数据集中的每个数据点,以指示模型有关任务的细节。我们特意选择了提示模板,使任务对我们的适配器和 GPT-4 等指令调整模型都是公平的。例如,提示不是简单地传入一个只说“{text}”的模板,而是包含有关任务的详细说明。为需要其他上下文(如命名实体识别和数据转文本)的任务提供了单次和小次示例。
评估指标
我们创建了一个并行评估工具,可向 Predibase LoRAX 驱动的 REST API 发送大量查询,这也使我们能够在几秒钟内收集数千个针对 OpenAI、Mistral 和微调模型的响应。
为了评估模型质量,我们在固定的 1000 个样本子集上评估每个适配器,这些子集保留了测试数据,这些测试数据被排除在训练之外。我们通常对分类任务采用准确性,对涉及生成的任务采用 ROUGE。但是,在模型的输出类型不匹配的情况下(例如,当我们的适配器生成索引而 GPT-4 生成实际类时),我们会设计自定义指标以促进分数的公平比较。
我们计划在未来几周内发表一篇综合论文,深入解释我们的方法和发现。
结果
适配器名称 数据 度量 微调 GPT-4的 GPT-3.5-涡轮增压 Mistral-7b-指示 米斯特拉-7b 问答解释(下降) drop_explained label_and_explanation 0.33 0.12 0.09 0 0 命名实体识别 (CoNLL++) 康利普 胭脂 0.99 0.75 0.81 0.65 0.12 毒性检测(拼图) 拼图 准确性 0.84 0.76 0.74 0.52 0 新闻主题识别解释 (ag_news) agnews_explained label_and_explanation 0.45 0.19 0.23 0.25 0 句子比较 (MRPC) glue_mrpc 准确性 0.86 0.78 0.68 0.65 0 句子相似度 (STSB) glue_stsb STSB公司 0.45 0.2 0.17 0 0 WebNLG(基于 Web 的自然语言生成)* 网络NLG 胭脂 0.53 0.57 0.52 0.51 0.17 问题比较 (QQP) glue_qqp 准确性 0.88 0.84 0.79 0.68 0 新闻内容生成 (tldr_news) tldr_news 胭脂 0.22 0.12 0.12 0.17 0.15 新闻标题生成 (tldr_news) tldr_news 胭脂 0.43 0.18 0.17 0.17 0.1 语言可接受性 (CoLA) glue_cola 准确性 0.87 0.87 0.84 0.39 0 客户支持自动化 customer_support 准确性 0.99 0.87 0.76 0 0 开放式句子完成 (hellaswag) hellaswag_processed 胭脂 0.25 0.13 0.11 0.14 0.05 WikiSQL(SQL生成) WikiSQL数据库 胭脂 0.98 0.93 0.89 0.27 0.35 情绪检测 (SST2) glue_sst2 准确性 0.95 0.95 0.89 0.65 0 问答(下降) 落 胭脂 0.76 0.42 0.11 0.11 0.02 新闻摘要 (CNN) cnn 胭脂 0.25 0.17 0.18 0.17 0.14 小学数学 (gsm8k) GSM8K型 胭脂† 0.47 0.04 0.39 0.29 0.05 结构化到文本 (viggo) 维戈 胭脂 0.52 0.37 0.37 0.36 0.15 结构化到文本 (e2e_nlg) e2e_nlg 胭脂 0.54 0.51 0.46 0.49 0.18 化学和疾病识别 (bc5cdr) bc5cdr 胭脂 0.97 0.89 0.73 0.7 0.18 多项选择题句子完成 (hellaswag) 海拉斯赃物 准确性 0.82 0.8 0.51 0 0.03 法律条款分类 法律 胭脂 0.52 0.3 0.27 0.2 0.03 情绪检测 (COVID-19) 新冠病毒 准确性 0.77 0.32 0.31 0 0 自然语言推理 (MNLI) glue_mnli 准确性 0.87 0.81 0.51 0.27 0 新闻主题识别 (dbpedia) dbpedia dbpedia 0.99 0.04 0.06 0.01 0 代码生成 (magicoder)* 魔术师 人性化 0.11 0.82 0.49 0.05 0.01 † ROUGE 是评估模型功效的常用指标,LLMs但在这种情况下不太能代表模型的能力。GSM8K 将需要不同的评估指标。
* 我们观察到,在两个数据集(MagicCoder 和 WebNLG)上使用我们的默认配置对 Mistral-7B 基础模型进行微调时,与 GPT-4 相比,性能明显较低。我们将继续进一步研究这些结果,详细信息将在我们即将发表的论文中分享。
在我们提供的 27 个适配器中,有 25 个在性能上匹配或超过 GPT-4。特别是,我们发现,在基于语言的任务上训练的适配器,而不是基于 STEM 的任务,往往比 GPT-4 具有更高的性能差距。
亲自尝试微调的模型
您可以在 LoRA Land UI 中查询和试用所有微调的模型。我们还在HuggingFace上上传了所有微调的模型,以便您可以轻松下载和使用它们。如果您想尝试从 HuggingFace 查询我们的微调适配器之一,可以运行以下 curl 请求:
``` curl -d '{"inputs": "What is your name?", "parameters": {"adapter_id": "my_organization/my_adapter", "adapter_source": "hub"}}' \ -H "Content-Type: application/json" \ -X POST https://serving.app.predibase.com/$PREDIBASE_TENANT_ID/deployments/v2/llms/llama-2-7b-chat/generate \ -H "Authorization: Bearer ${API_TOKEN}" ```- 1
- 2
- 3
- 4
- 5
- 6
小型、特定任务模型的兴起
虽然自 ChatGPT 于 2022 年底首次亮相以来,组织一直在竞相进行生产,LLMs但许多人选择避免商业LLMs陷阱,转而尝试构建自己的。领先的商业广告LLMs可以帮助团队开发概念验证,并开始在没有任何训练数据的情况下生成高质量的结果,但在以下方面进行权衡:
- 控制:放弃模型权重的所有权
- 成本:为推理支付不可持续的溢价
- 可靠性:努力在不断变化的模型上保持性能
为了克服这些挑战,许多团队要么从头开始构建自己的生成式预训练转换器 (GPT),要么使用数十亿或数万亿个参数对整个模型进行微调。然而,这些方法非常昂贵,并且需要大量的计算资源,而大多数组织都无法企及。
这反过来又推动了采用更小、更专业和更LLMs高效的方法,如上述 PEFT 和 QLoRA。这些技术在计算、时间和数据方面的培训要求降低了几个数量级,即使资源有限、预算较小的团队也可以进行像 LoRA Land 中托管的开发LLMs一样进行微调。
我们构建 LoRA Land 是为了提供一个真实世界的例子,说明更小的、特定于任务的微调模型如何经济高效地优于领先的商业替代方案。Predibase 使组织能够更快、更高效地进行微调和服务,LLMs我们很高兴为想要开始部署专业LLMs化来支持其业务的团队提供工具和基础设施。
-
相关阅读:
mac图像查看器EdgeView for Mac
httprunner4学习总结6 – 手动编写测试用例
每天几道Java面试题:IO流(第五天)
Python笔记二之多线程
【算法训练营】 井字棋
Master PDF Editor v5.9.70便携版
使用OPENROWSET :在一个数据库中查询另一个数据库的数据
南京邮电大学电工电子基础B实验六(组合逻辑电路)
在元宇宙创造可持续财富的3种方式
tomcat架构概览
- 原文地址:https://blog.csdn.net/liferecords/article/details/136248880