-
【激光SLAM】基于滤波的激光SLAM方法(Grid-based)
- 目前大部分的基于状态估计的算法都是基于贝叶斯滤波的
- 粒子滤波是贝叶斯滤波的一种实现方式。在视觉SLAM中,滤波器会同时估计机器人的位姿和特征地图,速度慢,只能在小环境内用。在激光SLAM中,把位姿和地图的估计分开了,对稍微大一些的环境也适用。但随着地图增大,会造成粒子耗散的问题。
- FastSLAM基于粒子滤波
贝叶斯滤波
数学概念

贝叶斯滤波特性
- 估计的是概率分布(贝叶斯——最大后验估计:估计出数值的后验概率分布,找到最大值的地方),不是具体数值(频率学派——极大似然估计:找到一个数值,使得我当前发生的概率最大)二者在高斯分布的情况下等价。
- 是一大类方法的统称
- 是一个抽象的表达形式——对于不同问题有不同的实现方式(卡尔曼、粒子滤波)
- 迭代估计形式
贝叶斯滤波的推导


粒子滤波(Particle filter)
特性
- 贝叶斯估计的一种实现方式
- 能处理非线性情况
- 能处理多峰分布的情况(全局定位)
- 用一系列粒子(particle)近似概率分布
- 非参滤波器

流程
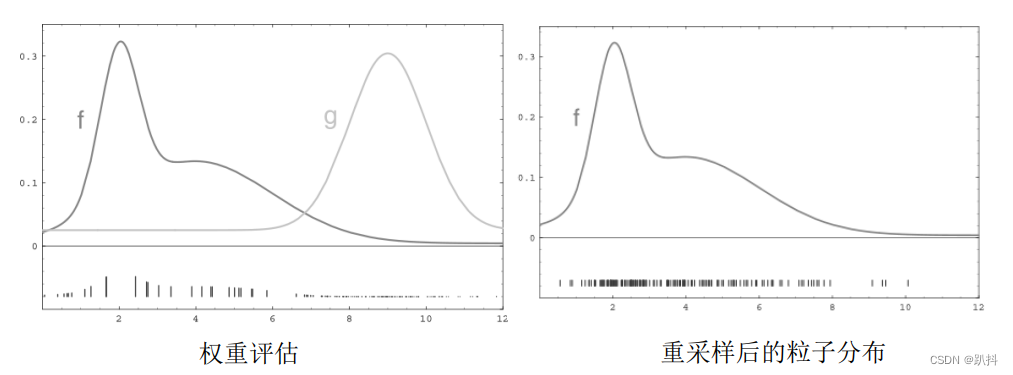
粒子滤波由一系列粒子来表示分布,权重用于评估假设符不符合真实情况,即观测数据能否与地图匹配上,或者说:用一个假设位姿跟机器人地图的匹配度来评估其权重:

具体流程如下:
重采样: 用于去除权重小的粒子
权重清零: 如果有n个粒子,则权重清零后,每个粒子的权重为n分之一每次重采样后,每个粒子的权重都相等。随着新的观测数据进来,粒子就会不断更新,粒子的权重也随之更新。
状态传播

第一条式子得到的是一个分布,而第三条式子对每一个粒子单独去预测,得到的是一个具体的位姿。粒子传播的方式即为运动学模型:

当没有观测值的时候,粒子云范围会越来越大,最终趋于均匀分布,如右图。当有观测值的情况下,每次进行重采样的时候都会把权重低的粒子去掉,不断缩小粒子云范围,聚集在真实位姿的地方。权重评估
机器人位姿跟地图的匹配程度


重采样
重采样的目的:用proposal分布的粒子和观测模型的权重生成符合后验概率分布的粒子群

权重大的粒子会被多次选中,相当于该粒子被多次复制;权重小的粒子选中次数较少或没有被选中,相当于该粒子被删除。
算法流程

存在的问题
- 粒子耗散问题(多样性散失)
- 维数灾难
- 当proposal比较差的时候,需要用很多的粒子才能较好的表示机器人的后延概率分布
FastSLAM的原理及优化
FastSLAM是Gmapping的基础,采用RBPF,用粒子滤波来估计机器人的位姿,然后分别为每一个粒子计算地图。
FastSLAM介绍

算法流程

FastSLAM优化
存在的问题及优化
问题1: 每一个粒子都包含自己的栅格地图。对于稍微大一点的环境来说,每一个粒子都会占用比较大的内存。如果机器人的里程计误差比较大,即proposal分布跟实际分布相差较大,则需要较多的粒子才能比较好的表示机器人位姿的后验概率分布,会造成内存爆炸。
目的: 要保持粒子的数量在一个比较小的数值。
方法: 提升proposal分布采样的位姿质量。

问题2: 粒子耗散问题,因此每一次进行重采样都有一定的随机性。随着重采样次数的加多,粒子的多样性会耗散掉,即最终的所有粒子都来自同一个粒子或者少数的几个粒子的复制。如此一来,就无法通过粒子切换来达到“回环检测”的效果(但是滤波算法本身不具备回环检测的步骤,只是看起来像)。
目的: 尽量缓解粒子耗散的问题。
方法: 减少重采样的次数,用一个量来表示当前估计和真实分布的差异性:

进一步优化proposal分布
上面的优化方式: 首先从proposal分布进行采样,然后进行极大似然估计提升采样的质量。
本次优化方式: 考虑最近一帧的观测,把proposal分布限制在一个狭小的有效区域。然后在正常的对proposal分布进行采样。
假设:
激光雷达的匹配比里程计的测量精确很多,从分布上来说,激光雷达匹配的方差要比里程计模型的方差小很多。如图所示,激光匹配的方差比里程计要小很多,如果proposal分布用激光匹配来表示,则可以把采样范围限制在一个比较小的区域,因此可以用更少的粒子覆盖机器人的概率分布。
激光雷达观测模型的方差较小,假设其服从高斯分布:

高斯分布的求解:


最终算法流程


Gmapping介绍
- 目前使用的最为广泛的2D激光SLAM算法
- 在较小的环境中能实现较好的建图效果
- 以FastSLAM为基本原理
- 在FastSLAM的基础上进行了优化1和优化2
Gmapping算法流程

引用
-
相关阅读:
Linux基本指令(二)
PhPstudy搭建本地WordPress
一键体验 Istio
vue 实现图片以鼠标为中心放大,并可以随意在div内拖动
MindFusion.Diagramming 6.8.4 Crack
【已解决】钉钉审批流回调瞬间返回两次通知
全量知识系统 详细程序设计 之“编程理念”(Q&A SmartChat)
Ansible概述和模块解释
黑客入门指南,学习黑客必须掌握的技术
《C++Primer》-1-前序与基础第I部分重点
- 原文地址:https://blog.csdn.net/PuddleRubbish/article/details/136205803