
原创/朱季谦
最近在阅读Kafka的源码,想可以在阅读过程当中,在代码写一些注释,便决定将源码部署到本地运行。
日常开发过程中,用得比较多一个版本是Kafka2.7版本,故而在MacBook Pro笔记本上用这个版本的源码进行搭建,进行Kafka源码的阅读学习。在搭建的过程当中,遇到不少坑,顺便记录了下来,方便以后重新搭建时,不至于又从头开始。
在本地搭建Kafka2.7源码,需要准备以下环境,我本地用的是MacBook Pro M1笔记本,windows的话应该也是类似思路:
- Zulu JDK1.8
- Scala 2.13.1
- Gradle6.6
- Zookeeper3.4.6
- Kafka2.7
基于以上需要的环境,一一讲解。
一、Zulu JDK1.8
这个没啥好讲的,基本用MBP做开发的,几乎都有安装了一个JDK,区别是不同版本而已。我用的是OpenJDK 的Zulu JDK1.8版本,印象中是可以通过直接下载 .dmg 格式一键安装的,同时会自动配置好系统环境,默认安装路径在 /Library/Java/JavaVirtualMachines。
二、Scala 2.13.1
我没有在系统里安装Scala,而是直接用IDEA的。
按照Preferences -> Plugins -> 选择Scala点击Installed。

这样可以基于IDEA选择不同版本的Scala JDK——

三、安装Gradle6.6
可以通过官网https://gradle.org/releases/下载Gradle6.6版本——

官网下载,若是国内下载会很慢,我将当时下载的安装包放在了百度网盘里,可以直接网盘下载——
网盘链接: https://pan.baidu.com/s/1zmV2LNan0-lNEndPZ-H_Qw 提取码: agu5
下载下来后,直接解压,我放在了目录/Users/helloword/software/gradle-6.6,在mac终端执行指令——
vim ~/.bash_profile
在bash_profile文件里加入以下内容,这里的GRADLE_HOME即解压存放gradle-6.6的目录——
GRADLE_HOME=/Users/helloword/software/gradle-6.6
export GRADLE_HOME
保存,执行source ~/.bash_profile刷新,输入gradle -v验证一下,若是出现以下信息,表示gradle安装成功——
zhujiqian@zhujiqiandeMacBook-Pro ~ % gradle -v
------------------------------------------------------------
Gradle 6.6
------------------------------------------------------------
Build time: 2020-08-10 22:06:19 UTC
Revision: d119144684a0c301aea027b79857815659e431b9
Kotlin: 1.3.72
Groovy: 2.5.12
Ant: Apache Ant(TM) version 1.10.8 compiled on May 10 2020
JVM: 1.8.0_282 (Azul Systems, Inc. 25.282-b08)
OS: Mac OS X 12.5.1 aarch64
三、Zookeeper3.4.6安装
同理,避免读者额外去找这个包,我把它放到了百度网盘上——
链接: https://pan.baidu.com/s/1sTJVzDH5q4Jw5biAzTs3Mw 提取码: 6v87
3.1、分别将zookeeper-3.4.6.tar.gz拷贝到三台机器上,例如下面三台机器上,放到app目录下——
| 服务器名字 | 服务器IP |
|---|---|
| hadoop1 | 192.168.31.130 |
| hadoop2 | 192.168.31.131 |
| hadoop3 | 192.168.31.132 |
3.2、在三台机器的/app/zookeeper-3.4.6目录下,各创建一个data目录,然后各建立一个命名为myid的文件,分别按照以下方式写入一个数字——
- 192.168.31.130的/app/zookeeper-3.4.6/data/myid写入数字1
- 192.168.31.130的/app/zookeeper-3.4.6/data/myid写入数字2
- 192.168.31.130的/app/zookeeper-3.4.6/data/myid写入数字3
cat查看192.168.31.130的/app/zookeeper-3.4.6/data/myid,值为1——

3.3、在192.168.31.130的/app/zookeeper-3.4.6/conf/目录下,其本身就有一个zoo_sample.cfg文件,通过cp zoo_sample.cfg zoo.cfg指令复制生成一个zoo.cfg文件,在zoo.cfg文件里修改为以下内容——
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/app/zookeeper-3.4.6/data
quorumListenOnAllIPs=true
clientPort=2181
dataLogDir=/app/zookeeper-3.4.6/dataLog
server.1=192.168.31.130:2888:3888
server.2=192.168.31.131:2888:3888
server.3=192.168.31.132:2889:3889
保存完成后,分别复制到192.168.31.131、192.168.31.132这两台机器的/app/zookeeper-3.4.6/conf/目录下——
scp zoo.cfg root@192.168.31.131:/app/zookeeper-3.4.6/conf/
scp zoo.cfg root@192.168.31.132:/app/zookeeper-3.4.6/conf/
3.4、然后,就可以正常启动了,分别在三台机器的/app/zookeeper-3.4.6/bin目录下,执行./zkServer.sh start,执行完成后,通过指令执行./zkServer.sh status 观察集群状态,若是如下mode字段显示follower或者leader的话,说明集群已经成功启动——

四、Kafka2.7源码部署
4.1、源码部署搭建
读者可以自行到官网https://kafka.apache.org/downloads下载

当然,也可以直接从网盘下载,我已经放到网盘了,后续等我阅读完后,会把有源码注释的,同步到网盘里——
链接: https://pan.baidu.com/s/1KhW8V5UIcgtvXlCfAMNZeA 提取码: 31te
我把源码下载到目录/Users/helloword/software/kafka/kafka-2.7.0-src里。
Kafka源码需要依赖Gradle构建代码,就类似SpringBoot依赖Maven来构建代码,故而在将Kafka源码导入Idea前,先通过Gradle命令进行环境构建。
打开mac的终端,进入到源码路径——

然后分别执行以下指令——
#更新gradle
gradle
#只需执行一次,会在当前目录的/gradle/wrapper/目录里生成一个gradle-wrapper.jar
gradle wrapper
执行以上指令后,主要生成一个gradle-wrapper.jar,它是用来构建项目及打包的。

接下来,分别继续执行以下指令,这部分指令运行很慢,需要一段时间——
#在 Gradle 项目中构建可执行的 JAR 文件
./gradlew jar
#构建的项目中生成 IntelliJ IDEA 的工程文件和配置,若是用的eclipse,就运行./gradlew eclipse
./gradlew idea
#生成源代码 JAR 文件
./gradlew srcJar
执行完以上指令,完成Gradle的代码运行环境,就可以通过Idea导入Kafak2.7源码——
正常情况下,左边栏会出现Gradle菜单选项,若没有的话,就双击源码里的build.gradle后,选择Link Gradle Project——

这时候,源码项目真正成为一个Gradle构建的项目,可以看到右边菜单多了一个Gradle菜单选项,点击,可以看到Gradle栏目里出现了一个kafka-2.7.0-src,双击后,选择Reload Gradle Project就可以加载项目及依赖了。

4.2、源码运行
4.2.1、源码运行打印日志
若要在源码里运行能够打印日志,需要满足以下两个条件——
1、复制config的log4.properties到core的 resources目录
2、在build.gradle的project(':core') 的dependencies {}增加log4配置
4.2.1.1、复制config的log4.properties到core的 resources目录
在源码/core/src/main/目录下,新建一个resource资源目录。
而在源码的config目录下,有一个log4j.properties。
可以直接将/config/log4j.properties复制到/core/src/main/resources目录里——

当然,直接复制过来时,运行时,可能只会出现以下打印,发现log4j.properties并没有起作用——

这时候就需要接下来在build.gradle增加一些配置。
4.2.1.2、在build.gradle的project(':core') 的dependencies {}增加log4配置
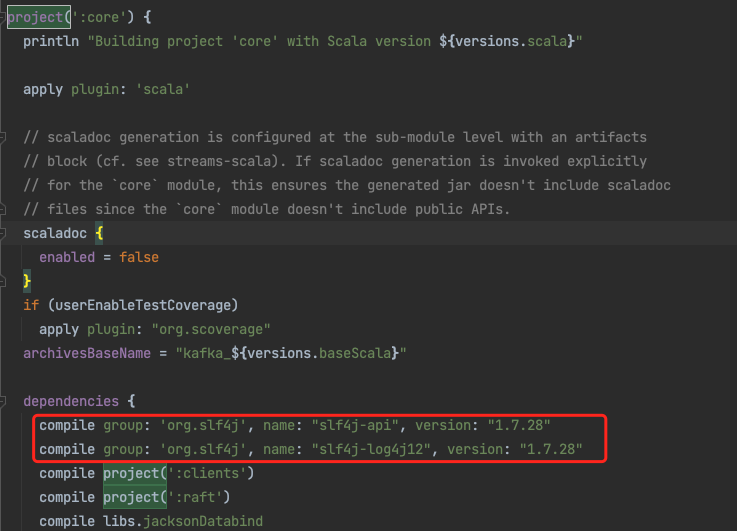
在build.gradle里找到project(':core') {}里的dependencies {}处,增加以下配置——
compile group: 'org.slf4j', name: "slf4j-api", version: "1.7.28"
compile group: 'org.slf4j', name: "slf4j-log4j12", version: "1.7.28"
配置完以上信息后,运行日志时可能还会出现以下异常——
log4j:ERROR setFile(null,true) call failed.
java.io.FileNotFoundException: /server.log (Read-only file system)
at java.io.FileOutputStream.open0(Native Method)
at java.io.FileOutputStream.open(FileOutputStream.java:270)
at java.io.FileOutputStream.<init>(FileOutputStream.java:213)
at java.io.FileOutputStream.<init>(FileOutputStream.java:133)
at org.apache.log4j.FileAppender.setFile(FileAppender.java:294)
at org.apache.log4j.FileAppender.activateOptions(FileAppender.java:165)
at org.apache.log4j.DailyRollingFileAppender.activateOptions(DailyRollingFileAppender.java:223)
我当时的解决该异常的方式是,统一将log4.properties的日志出现以上异常的路径${kafka.logs.dir}改成指定的/Users/helloword/logs例如,/server.log等,统一改成,就正常了/Users/helloword/logs/server.log,就正常了。

4.2.2、修改源码的config/server.properties配置
在运行kafka服务前,需要修改config/server.properties配置里一些信息,主要改两处地方,分别是连接的zookeeper路径和kafka的broker的ip——
broker.id=0 #默认的就好
listeners=PLAINTEXT://192.168.31.110:9092 #改成你的主机ip,需要注意一点是,该ip需要能跟你配置的zookeeper通信
zookeeper.connect=192.168.31.130:2181,192.168.31.130:2181,192.168.31.130:2181 #zookeeper集群地址
4.2.3、配置Kakfa运行的server、consumer、producer三个进程
4.2.3.1、server
按照以下信息配置一个server应用服务——

配置完,点击启动,若打印类似以下正常日志,说明成功了——

4.2.3.2、consumer
这里的--topic test01 --bootstrap-server 192.168.31.110:9092里的ip,即配置config/server.properties文件里listeners=PLAINTEXT://192.168.31.110:9092对应的ip。
该消费者表示监听topic为test01。

运行正常,日志打印同样没问题——

4.2.3.3、producer
跟consumer配置类似——

配置完成后,运行,若没有问题,可以直接在日志控制尝试模拟生产者发送消息,例如,发送一个hello world——
查看consumer端的日志打印,若能收到消息,说明kafka的生产者和消费者能正常进行消息发送了,可以基于这开始debug阅读源码了——

整个kafka2.7版本源码搭建,按照以上步骤就搭建完成。
后续我会将阅读源码的总结写成系列文章。
最近开了一个公众号,方便用来分类归纳自己写的博客,可以关注我的公众号【写代码的朱季谦】。
