-
爬虫工程师基本功,什么是静态网页与动态网页
一、静态网页
静态网页
静态网页就是直接固定的数据,数据直接是在Html返回的时候,Html中已经包含了相应的数据,这个数据对爬虫来说最友好的。爬虫只需要请求数据,不用再去单独的分析,将请求直接从页面中去提取出数据。像百度百科,维基百科这种实际上很少变动,偶尔编辑一次这种页面就非常适合用来做静态网页。
静态网页相对的几个最重要的优点,就是它相对稳定,静态网页的内容相对固定,且不需要连接后台数据库,因此响应速度非常快,更利于SEO,像百度搜索引擎,道理也是一样的。它们查数据也会简单很多。因为像百度谷歌这种搜索引擎,因为它们爬取的网站太多了,它们不可能针对每个网站去分析它们的请求,所以它们一般直接分析HTML返回的内容是什么,它就是什么。如果做的内容尽量直接展示在HTML讲义当中。爬虫它就能够直接爬取这些数据,然后网站的排名就会上升。
静态网页是网站建设的基础,早期的网站一般都是由静态网页制作的。静态并非静止不动,它也包含一些动画效果,这一点不要误解
二、动态网页
动态网页就是有交互的网页,比如数据通过ajax请求动态加载了数据。动态网页体验好,数据部分加载,对服务器友好,扩展性好
什么是服务器友好呢?
假如静态网页展示的内容和动态网页展示的内容是一样的,有一部分内容动态网页通过某些请求,服务器就可以尽快的返回简单的Html。
它能够先展示出来的部分就会先展示出来,所以对服务器来说就比较友好,服务器的压力不会过大。
如果是静态网页,它也需要同样的内容的,就意味着服务端必须将所有的数据组装好了之后才能够返回。这样服务器可能就会响应比较慢什么是扩展性好?
动态页面上很多数据分成很多接口来完成,这样就可以做成APP,去做小程序等多端服务,就不需要再做额外的开发了
注意:一般网站通常会使用动静相结合的方式,使其达到一种平衡的状态。
抓取动态网页的过程较为复杂,需要通过动态抓包来获取客户端与服务器交互的 JSON 数据。抓包时,可以使用谷歌浏览器开发者模式(快捷键:F12)
Network选项,然后点击XHR,找到获取 JSON 数据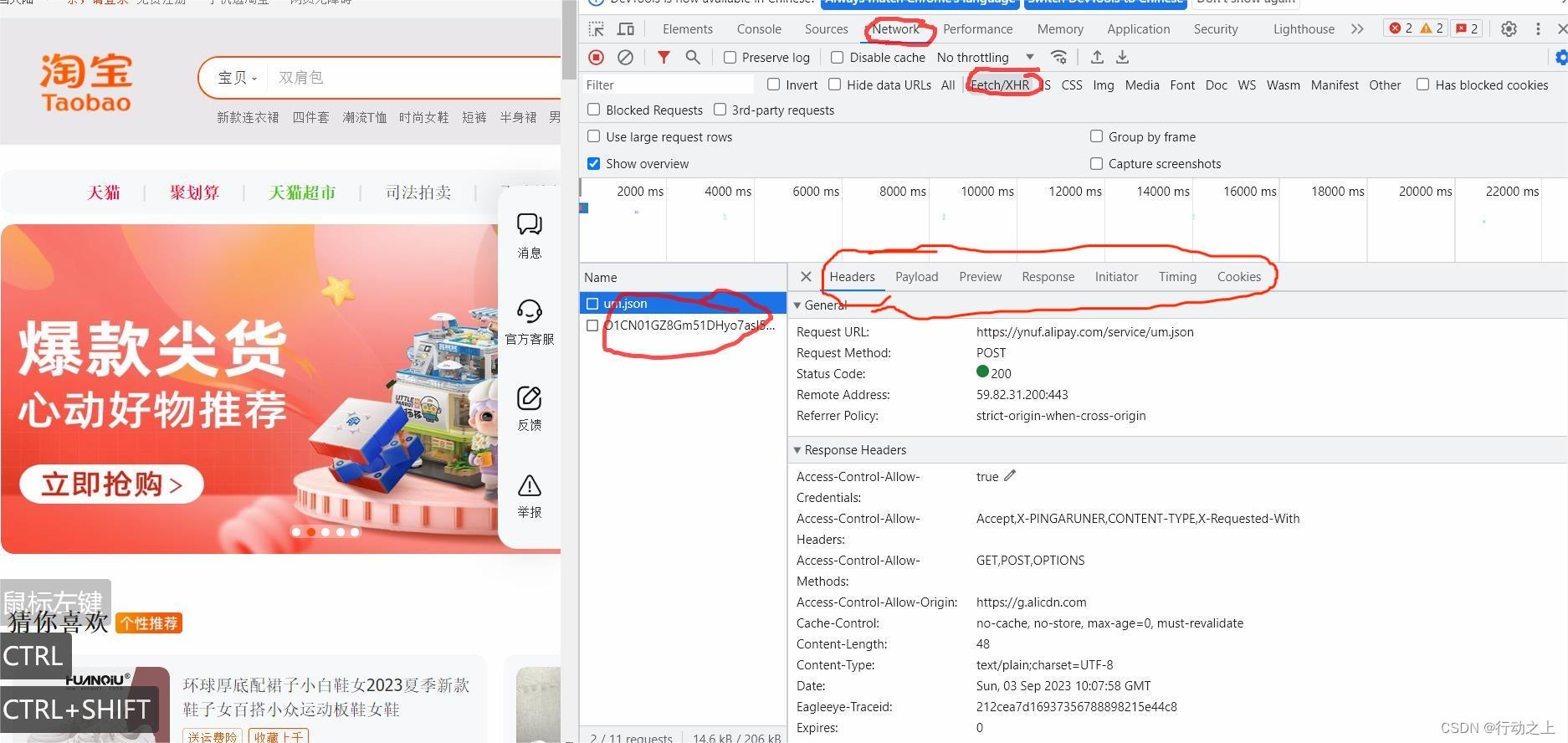
Network`选项 : 查看网络请求
XHR : 抓取与服务器的交互数据
左侧栏 : 抓取的数据包
标签栏 :网络请求信息,响应信息等也可以使用专业的抓包工具 Fiddler
-
相关阅读:
Python(9)面对对象高级编程
【AUTOSAR-CanIf】-2.3-对接收的L-PDU进行的Validation check
音视频从入门到精通——FFmpeg结构体:AVCodecContext分析
java实际项目反射、自定义注解的运用实现itext生成PDF的详细应用教程
Js将时间戳转成日期格式
移动端页面秒开优化总结
JDK8使用Optional避免NullPointerException
静态web页面网站课程设计
SpringMVC的上传下载
16 - 多线程调优(下):如何优化多线程上下文切换?
- 原文地址:https://blog.csdn.net/weixin_36643308/article/details/132652374