-
redis的性能管理和雪崩
redis的性能管理
redis的数据是缓存在内存当中的
系统巡检:
硬件巡检、数据库、nginx、redis、docker、k8s
运维人员必须要关注的redis指标
在日常巡检中需要经常查看这些指标使用情况
- info memory
- #查看redis使用内存的指标
- used_memory:11285512
- #数据占用的内存(单位是字节)
- used_memory_rss:24285184
- #向操作系统申请的内存(单位是字节)
- used_memory_peak:23952088
- #redis使用内存的峰值(单位是字节)
- 内存碎片率:used_mem0ry_rss/used_memory
- #系统已经分配给了redis,但是未能够有效利用的内存
如何查看内存碎片率?
- 内存碎片率:used_mem0ry_rss/used_memory
- #系统已经分配给了redis,但是未能够有效利用的内存
- redis-cli info memory | grep ratio
- #查看内存碎片率
- allocator_frag_ratio:1.03
- #分配器碎片比例。由redis主进程调度时产生的内存,比例越小越好,值越高,内存浪费越多。
- allocator_rss_ratio:1.80
- #表示分配器占用物理内存的比例,主进程调度过程中占用了多少物理内存
- rss_overhead_ratio:1.13
- #RSS是向系统申请的内存空间,redis占用物理空间额外的开销比例。比例越低越好。redis实际占用的物理内存和向系统申请的内存越接近额外的开销就越低
- mem_fragmentation_ratio:2.16
- #内存碎片的比例。值越低越好。表示内存的使用率越高
如何来进行清理碎片?
- 自动清理碎片
- vim /etc/redis/6379.conf
- 最后一行插入
- activedefrag yes
- #自动清理碎片
- /etc/init.d/redis_6379.conf restart
- #重启redis服务
- 手动清理碎片
- redis-cli memory purge
- #手动清理碎片
设置redis的最大内存阈值
- vim /etc/redis/6379.conf
- 567行
- maxmemory 1gb
- #一旦到达阈值会开始自动清理,开启key的回收机制
key的回收机制是什么?
就是回收键值对
key回收的策略
- vim /etc/redis/6379.conf
- 598行
- maxmemory-policy volatile-lru
- #使用redis内置的LRU算法。把已经设置了过期时间的键值对淘汰出去。移除最近最少使用的键值对(只是针对已经设置了过期时间的键值对)
- maxmemory-policy volatile-ttl
- #在已经设置了过期时间的键值对中,挑选一个即将过期的键值对(针对的是有设置生命周期的键值对)。
- maxmemory-policy volatile-random
- #在已经设置了过期时间的键值对中,挑选数据然后随机淘汰一个键值对(对设置了过期时间的键值对进行随机移除)
- allkeys-lru
- #根据redis内置的lru算法,对所有的键值对进行淘汰。移除最少使用的键值对。(针对所有的键值对)
- allkeys-random
- #在所有键值对中,任意选择数据进行淘汰
- maxmemory-policy noeviction
- #禁止对键值对回收(不删除任何键值对,知道redis把内存塞满,写不下,报错为止)
工作用要么保证数据完整性使用maxmemory-policy noeviction 要么使用maxmemory-policy volatile-ttl挑选一个即将过期的键值对清除
在工作当中一定要给redis占用内存设置阈值否则会将整个系统内存占满为止
redis的雪崩
缓存雪崩:大量的应用请求无法在redis缓存当中处理,请求会全部发送到后台数据库。数据库并发能力并发能力本身就差,数据库会很快崩溃
什么情况可能会导致雪崩出现?
1、 redis集群大面积故障
2、 redis缓存中,大量数据同时过期,大量的请求无法得到处理
3、 redis实例宕机
防止雪崩出现的方法
事前:高可用架构,防止整个缓存故障。主从复制和哨兵模式、redis集群
事中:在国内用得较多的方式:HySTRIX有三种方式:熔断、降级、限流。可以使用这三个手段来降低雪崩发生之后的损失。确保数据库不死即可,慢可以,但是不能没有响应。
事后:redis数据备份的方式来恢复数据或使用快速缓存预热的方式
redis的缓存击穿
缓存击穿主要是热点数据缓存过期或者被删除,多个请求并发访问热点数据。请求也是转发到后台数据库了,导致数据库的性能快速下降。
经常被请求的缓存数据最好设置为永不过期
redis缓存穿透
缓存中没有数据,数据库中也没有对应数据,但是有用户一直发起这个没有的请求,而且请求的数据格式很大。
可能是黑客在利用漏洞攻击,压垮应用数据库。
redis的集群架构
高可用方案:
1、 持久化
2、 高可用:主从复制、哨兵模式、集群
主从复制
主从复制是redis实现高可用的基础,哨兵模式和集群都是在主从复制的基础上实现高可用。
主从复制实现数据的多机备份,以及读写分离(主服务器负责写,从服务器只能读)
缺陷:故障无法自动恢复,需要人工干预。无法实现写操作的负载均衡
主从复制的工作原理
1、 主节点(master)和从节点(slave)组成。数据的复制时单项的,只能从主节点到从节点。
主从复制节点最少要有三台
主从复制的数据流向和工作流程图:
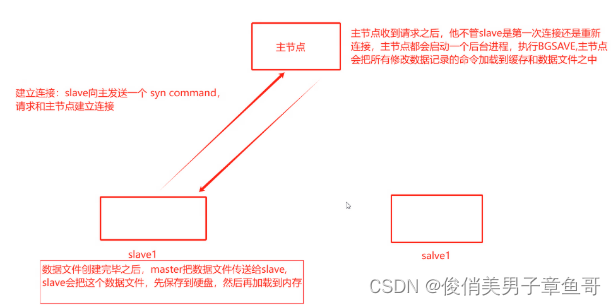
1、 从与主建立连接。从会发送一个syn command,请求和主建立连接
2、 主节点收到请求之后,不管slave是第一次连接还是重新连接。主节点都会启动一个后台进程。执行BGsave。
3、 主节点会把所有修改数据记录的命令也加载到缓存和数据文件之中。
4、 数据文件创建完毕之后,是由主系欸但把数据文件传送给从节点,从节点会把数据文件保存到硬盘当中后再加载到内存中去。
主从复制推荐使用AOF,通过AOF文件实现实时持久化,主从节点都开启AOF持久化服务。从节点同步的就是aof文件。
主从复制工作流程图:
主从复制实验
- 实验准备:
- 20.0.0.26 master
- 20.0.0.27 slave1
- 20.0.0.28 slave2
- 三台机器都需要安装redis服务
- 做完后拍个快照
- systemctl stop firewalld
- setenforce 0
- #关闭三台机器的防火墙和安全机制
- 主节点:
- vim /etc/redis/6379.conf
- 修改网段 0.0.0.0
- daemonize yes
- 700行
- 开启aof模式
- /etc/init.d/redis_6379 restart
- 从节点1:
- vim /etc/redis/6379.conf
- 修改网段 0.0.0.0
- 288行
- replicaof
- replicaof 20.0.0.26 6379
- #指向主的ip和端口
- 700行
- 开启aof模式
- /etc/init.d/redis_6379 restart
- 开启了指向后从节点将变为只读模式
- 从节点2:
- vim /etc/redis/6379.conf
- 修改网段 0.0.0.0
- 288行
- replicaof
- replicaof 20.0.0.26 6379
- #指向主的ip和端口
- 700行
- 开启aof模式
- /etc/init.d/redis_6379 restart
- 开启了指向后从节点将变为只读模式
- 主节点:
- tail -f /var/log/redis_6379.log
- #查看主节点日志,看是否指向成功
- 验证效果:
- 主从都登录redis
- 主节点:
- set test1 1
- #创建一个键值对
- 主上创建成功后到两台从节点查看一下看是否可以查看到
- 从节点:
- set test2 2
- #在从节点上测试是否为只读模式
- 报错,说明搭建成功从节点已经设置为只读模式了
- 实验完成!
- redis-cli info replication
- #查看主从配置信息
- 停止一个从节点来测试。停机期间插入的数据,服务重启后依旧可以同步
哨兵模式
哨兵模式依赖于主从模式,先有主从再有哨兵
哨兵模式是在主从复制的基础上实现主节点故障的自动切换
哨兵模式的工作原理
哨兵:是一个分布式系统。部署在每一个redis节点上用于在主从结构之间对每台redis的服务进行监控。
哨兵模式的投票机制
主节点出现故障时,从节点通过投票的方式选择一个新的master
哨兵模式也需要至少三个节点
哨兵模式的结构
哨兵节点和数据节点
哨兵节点:监控,不存储数据
数据节点:主节点和从节点,都是数据节点
哨兵模式的工作机制
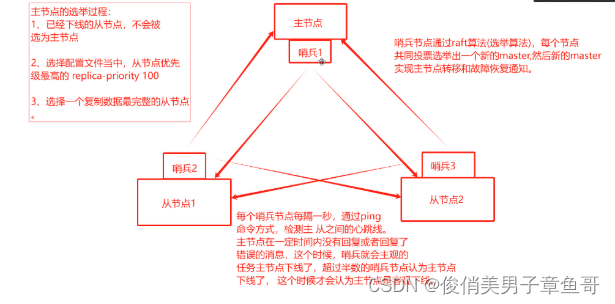
哨兵模式的架构和工作机制图:
哨兵1节点会对应监控从节点1和从节点2
哨兵2节点会对应监控主节点和从节点2
哨兵3节点会监控主节点和从节点1
哨兵节点会互相监控架构内的其他节点主机
哨兵模式的投票机制:
1、 每个哨兵节点每隔1秒,通过ping命令的方式检测主从之间的心跳线。
2、 当主节点在一定时间内没有回复或者回复了错误的信息。哨兵会主观的认为主节点下线了。
3、 当有超过半数的哨兵节点认为主节点下线了,才会认为主节点是客观下线了
主节点选举过程:
哨兵节点会通过redis自带的raft算法(选举算法),每个节点共同投票,选举出一个新的master。
新的master来实现主节点的转移和故障恢复通知
1、 已经下线的从节点,不会被选择为主节点
2、 选择配置文件当中,从节点优先级最高的 replica-priority 100
3、 选择一个复制数据最完整的从节点
哨兵模式监控的是节点不是哨兵
故障恢复可能会优点延迟
最好是以复制数据最完整的从节点作为新的主节点
哨兵模式实验
- 主节点:
- cd redis-5.0.7
- vim sentinel.conf
- #哨兵模式的配置文件
- 17行
- protected-mode no
- #解除注释
- daemonize yes
- #开启后台运行逃兵模式
- 36行
- logfile "/var/log/sentinel.log"
- #指定日志文件的存放位置
- 65行
- dir"/var/lib/redis/6379"
- #指定数据库存放的位置
- 85行
- sentinel monitor mymaster 20.0.0.26 6379 2
- #声明主节点的IP和端口号.2代表至少要有2台服务认为主已经下线才会进行主从切换。一般配置为主从服务器的一半
- 113行
- sentinel down-after-milliseconds mymaster 30000
- #服务器宕机的最小时间。单位是毫秒。30秒之内如果主节点但没有响应,主观认为主下线了。时间可以改可以自定义
- 146行
- sentinel failover-timeout mymaster 180000
- #服务器宕机的最大时间,180秒之内如果主节点但没有响应,从节点开始投票,客观认为主下线了。时间可以改可以自定义
- 两台从节点配置和主节点配置一致即可
- 三台配置完成后需要先起主节点再起从节点
- 三台主机在redis的源码包中启动哨兵模式
- redis-sentinel sentinel.conf &
- #启动哨兵模式。&表示后台运行
- 主节点:
- redis-cli -p 26379 info Sentinel
- #查看整个集群的哨兵情况
- 查看主从信息:
- tail -f /var/log/redis_6379.log
- #查看主节点日志,查看主从信息
- 模拟故障切换:
- 可能会有延迟不是立刻切换
- ps-elf | grep redis
- #查看主节点
- kill -9 redis的主进程或者/etc/init.d/redis_6379 stop停止redis都可以测试
- 测试新主是否可以正常插入数据
- 测试两从是否可以数据同步
- 测试旧主机是否还有插入数据
- 旧主失去写的功能,新主增加写的功能。从2的配置文件指向了新的主
- 而旧主的配置文件中指向自己的配置将会消失
小模式用哨兵,大模式用集群
总结
运维人员日常巡检中关注的指标
- #查看redis使用内存的指标
- used_memory:11285512
- #数据占用的内存(单位是字节)
- used_memory_rss:24285184
- #向操作系统申请的内存(单位是字节)
- used_memory_peak:23952088
- #redis使用内存的峰值(单位是字节)
内存碎片:
- 内存碎片率:used_mem0ry_rss/used_memory
- #系统已经分配给了redis,但是未能够有效利用的内存
- redis-cli info memory | grep ratio
- #查看内存碎片率
- allocator_frag_ratio:1.03
- #分配器碎片比例。由redis主进程调度时产生的内存,比例越小越好,值越高,内存浪费越多。
- allocator_rss_ratio:1.80
- #表示分配器占用物理内存的比例,主进程调度过程中占用了多少物理内存
- rss_overhead_ratio:1.13
- #RSS是向系统申请的内存空间,redis占用物理空间额外的开销比例。比例越低越好。redis实际占用的物理内存和向系统申请的内存越接近额外的开销就越低
- mem_fragmentation_ratio:2.16
- #内存碎片的比例。值越低越好。表示内存的使用率越高
如何清理碎片:
- 自动清理碎片
- vim /etc/redis/6379.conf
- 最后一行插入
- activedefrag yes
- #自动清理碎片
- /etc/init.d/redis_6379.conf restart
- #重启redis服务
- 手动清理碎片
- redis-cli memory purge
- #手动清理碎片
如何设置阈值:
- vim /etc/redis/6379.conf567行maxmemory 1gb
- #一旦到达阈值会开始自动清理,开启key的回收机制
工作用要么保证数据完整性使用maxmemory-policy noeviction 要么使用maxmemory-policy volatile-ttl挑选一个即将过期的键值对清除
在工作当中一定要给redis占用内存设置阈值否则会将整个系统内存占满为止
redis的缓存击穿:
缓存击穿主要是热点数据缓存过期或者被删除,多个请求并发访问热点数据。请求也是转发到后台数据库了,导致数据库的性能快速下降。
经常被请求的缓存数据最好设置为永不过期
主从复制:
主从复制是redis实现高可用的基础,哨兵模式和集群都是在主从复制的基础上实现高可用。
主从复制实现数据的多机备份,以及读写分离(主服务器负责写,从服务器只能读)
缺陷:故障无法自动恢复,需要人工干预。无法实现写操作的负载均衡
哨兵模式:
哨兵模式监控的是节点不是哨兵
故障恢复可能会优点延迟
最好是以复制数据最完整的从节点作为新的主节点
拓展
运维人员必须要关注的redis指标:
在日常巡检中需要经常查看这些指标使用情况
- info memory
- #查看redis使用内存的指标
- used_memory:11285512
- #数据占用的内存(单位是字节)
- used_memory_rss:24285184
- #向操作系统申请的内存(单位是字节)
- used_memory_peak:23952088
- #redis使用内存的峰值(单位是字节)
如何查看内存碎片率?
- 内存碎片率:used_mem0ry_rss/used_memory
- #系统已经分配给了redis,但是未能够有效利用的内存
- redis-cli info memory | grep ratio
- #查看内存碎片率
- allocator_frag_ratio:1.03
- #分配器碎片比例。由redis主进程调度时产生的内存,比例越小越好,值越高,内存浪费越多。
- allocator_rss_ratio:1.80
- #表示分配器占用物理内存的比例,主进程调度过程中占用了多少物理内存
- rss_overhead_ratio:1.13
- #RSS是向系统申请的内存空间,redis占用物理空间额外的开销比例。比例越低越好。redis实际占用的物理内存和向系统申请的内存越接近额外的开销就越低
- mem_fragmentation_ratio:2.16
- #内存碎片的比例。值越低越好。表示内存的使用率越高
redis占用的内存效率问题如何解决?
1、 日常巡检中,针对redis的占用情况做监控
2、 给redis设置一个占用系统内存的阈值,避免占用系统的全部内容
3、 内存碎片清理,分为手动和自动两种模式
4、配置一个合适的key的回收机制。一般都是设置写满报错的方式(maxmemory-policy noeviction),通过运维人员手动维护。或者挑选一个即将过期的键值对清除(maxmemory-policy volatile-ttl)。
redis的缓存击穿
缓存击穿主要是热点数据缓存过期或者被删除,多个请求并发访问热点数据。请求也是转发到后台数据库了,导致数据库的性能快速下降。
经常被请求的缓存数据最好设置为永不过期
-
相关阅读:
uni-app - 树形结构选择器组件(支持单选 / 多选 / 可选择父级 / 弹框形式)树形控件 tree 无限级节点树,树插件完整源码,最好用的组件教程
31年前的Beyond演唱会,是如何超清修复的?
制造业数字化转型究竟是什么
交换机与路由技术-16-生成树协议STP
nginx 代理接口报404 问题排查
Carla学习笔记(二)服务器跑carla,本地运行carla-ros-bridge并用rviz显示
【正版软件】Navicat Monitor 实时数据库监控工具,一套安全、简单而且无代理的远程服务器监控工具。
ASP.NET WebForm--事件
puppeteer
练习题——【学习补档】库函数的模拟实现
- 原文地址:https://blog.csdn.net/m0_75209491/article/details/134545400
