-
时间序列预测实战(十七)PyTorch实现LSTM-GRU模型长期预测并可视化结果(附代码+数据集+详细讲解)

一、本文介绍
本文给大家带来的实战内容是利用PyTorch实现LSTM-GRU模型,LSTM和GRU都分别是RNN中最常用Cell之一,也都是时间序列预测中最常见的结构单元之一,本文的内容将会从实战的角度带你分析LSTM和GRU的机制和效果,同时如果你是时间序列中的新手,这篇文章会带你了解整个时间序列的建模过程,同时本文的实战代码支持多元预测单元、单元预测单元、多元预测多元,本文的实战内容通过时间序列领域最经典的数据集——电力负荷数据集为例进行预测。
内容回顾->时间序列预测专栏——包含上百种时间序列模型带你从入门到精通时间序列预测
预测类型->单元预测、多元预测、长期预测
目录
二、LSTM和GRU的机制原理
2.1LSTM的机制原理
LSTM(长短期记忆,Long Short-Term Memory)是一种用于处理序列数据的深度学习模型,属于循环神经网络(RNN)的一种变体,其使用一种类似于搭桥术结构的RNN单元。相对于普通的RNN,LSTM引入了门控机制,能够更有效地处理长期依赖和短期记忆问题,是RNN网络中最常使用的Cell之一。
LSTM通过刻意的设计来实现学习序列关系的同时,又能够避免长期依赖的问题。它的结构示意图如下所示。

在LSTM的结构示意图中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。其中“+”号代表着运算操作(如矢量的和),而矩形代表着学习到的神经网络层。汇合在一起的线表示向量的连接,分叉的线表示内容被复制,然后分发到不同的位置。
如果上面的LSTM结构图你看着很难理解,但是其实LSTM的本质就是一个带有tanh激活函数的简单RNN,如下图所示。

LSTM这种结构的原理是引入一个称为细胞状态的连接。这个状态细胞用来存放想要的记忆的东西(对应简单LSTM结构中的h,只不过这里面不再只保存上一次状态了,而是通过网络学习存放那些有用的状态),同时在加入三个门,分别是。
忘记门:决定什么时候将以前的状态忘记。
输入门:决定什么时候将新的状态加进来。
输出门:决定什么时候需要把状态和输入放在一起输出。
从字面上可以看出,由于三个门的操作,LSTM在状态的更新和状态是否要作为输入,全部交给了神经网络的训练机制来选择。
下面分别来介绍一下三个门的结构和作用。
2.2.1忘记门
下图所示为忘记门的操作,忘记门决定模型会从细胞状态中丢弃什么信息。
忘记门会读取前一序列模型的输出
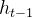 和当前模型的输入
和当前模型的输入 来控制细胞状态中的每个数是否保留。
来控制细胞状态中的每个数是否保留。例如:在一个语言模型的例子中,假设细胞状态会包含当前主语的性别,于是根据这个状态便可以选择正确的代词。当我们看到新的主语时,应该把新的主语在记忆中更新。忘记们的功能就是先去记忆中找到一千那个旧的主语(并没有真正执行忘记的操作,只是找到而已。

在上图的LSTM的忘记门中,
 代表忘记门的输出, α代表激活函数,
代表忘记门的输出, α代表激活函数, 代表忘记门的权重,
代表忘记门的权重,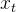 代表当前模型的输入,代表前一个序列模型的输出,
代表当前模型的输入,代表前一个序列模型的输出, 代表忘记门的偏置。
代表忘记门的偏置。2.2.2输入门
输入门可以分为两部分功能,一部分是找到那些需要更新的细胞状态。另一部分是把需要更新的信息更新到细胞状态里

在上面输入门的结构中,
 代表要更新的细胞状态,α代表激活函数,代表当前模型的输入,代表前一个序列模型的输出,
代表要更新的细胞状态,α代表激活函数,代表当前模型的输入,代表前一个序列模型的输出, 代表计算的权重,
代表计算的权重, 代表计算的偏置,
代表计算的偏置,
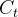 代表使用tanh所创建的新细胞状态,
代表使用tanh所创建的新细胞状态, 代表计算的权重,
代表计算的权重,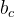 代表计算的偏置。
代表计算的偏置。忘记门找到了需要忘掉的信息
后,在将它与旧状态相乘,丢弃确定需要丢弃的信息。(如果需要丢弃对应位置权重设置为0),然后,将结果加上 * 使细胞状态获得新的信息。这样就完成了细胞状态的更新,如下图输入门的更新图所示。
再上图LSTM输入门的更新图中,
 代表忘记门的输出结果, 代表忘记门的输出结果,
代表忘记门的输出结果, 代表忘记门的输出结果, 代表前一个序列模型的细胞状态,代表要更新的细胞状态,
代表前一个序列模型的细胞状态,代表要更新的细胞状态, 代表使用tanh所创建的新细胞状态。
代表使用tanh所创建的新细胞状态。2.2.3输出门
如下图LSTM的输出门结构图所示,在输出门中,通过一个激活函数层(实际使用的是Sigmoid激活函数)来确定哪个部分的信息将输出,接着把细胞状态通过tanh进行处理(得到一个在-1~1的值),并将它和Sigmoid门的输出相乘,得出最终想要输出的那个部分,例如,在语言模型中,假设已经输入了一个代词,便会计算出需要输出一个与该代词相关的信息(词向量)

在LSTM的输出门结构图中,
 代表要输出的信息,α代表激活函数,
代表要输出的信息,α代表激活函数, 代表计算 的权重,
代表计算 的权重, 代表计算的偏置,代表更新后的细胞状态,
代表计算的偏置,代表更新后的细胞状态, 代表当前序列模型的输出结果。
代表当前序列模型的输出结果。2.2GRU的机制原理
2.2.1GRU的基本原理
GRU(门控循环单元)是一种循环神经网络(RNN)的变体,主要用于处理序列数据,它的基本原理可以概括如下:
-
门控机制:GRU的核心是门控机制,包括更新门(update gate)和重置门(reset gate)。这些门控制着信息的流动,即决定哪些信息应该被保留,哪些应该被遗忘。
-
更新门:更新门帮助模型决定过去的信息有多少需要保留到当前状态。它是通过当前输入和前一个隐状态计算得出的,用于调节隐状态的更新程度。
-
重置门:重置门决定了多少过去的信息需要被忘记。它同样依赖于当前输入和前一个隐状态的信息。当重置门接近0时,模型会“忘记”过去的隐状态,只依赖于当前输入。
-
当前隐状态的计算:利用更新门和重置门的输出,结合前一隐状态和当前输入,GRU计算出当前的隐状态。这个隐状态包含了序列到目前为止的重要信息。
-
输出:GRU的最终输出通常是在序列的每个时间步上产生的,或者在序列的最后一个时间步产生,取决于具体的应用场景。
总结:GRU相较于传统的RNN,其优势在于能够更有效地处理长序列数据,减轻了梯度消失的问题。同时,它通常比LSTM(长短期记忆网络)更简单,因为它有更少的参数。
2.2.1GRU的基本框架
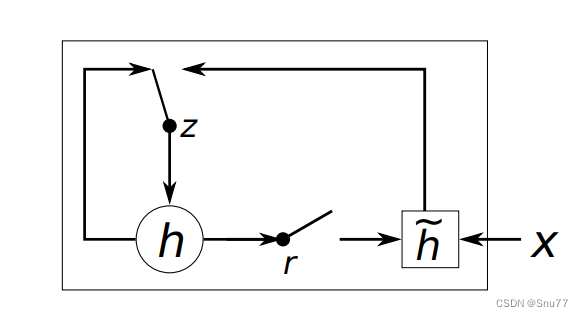
上面的图片为一个GRU的基本结构图,解释如下->
- 更新门(z) 在决定是否用新的隐藏状态更新当前隐藏状态时扮演重要角色。
- 重置门(r) 决定是否忽略之前的隐藏状态。
这些部分是GRU的核心组成,它们共同决定了网络如何在序列数据中传递和更新信息,这对于时间序列分析至关重要。
2.3 融合思想
三、数据集介绍
我们本文用到的数据集是官方的ETTh1.csv,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是ETTh1.csv数据集的一些内容:数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->
四、参数讲解
下面的代码是我定义的所有参数,目前只有这些,这个框架我会进行补充,后期也会在这里进行更新。
- parser = argparse.ArgumentParser(description='Time Series forecast')
- parser.add_argument('-model', type=str, default='LSTM-GRU', help="模型持续更新")
- parser.add_argument('-window_size', type=int, default=48, help="时间窗口大小, window_size > pre_len")
- parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")
- # data
- parser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")
- parser.add_argument('-data_path', type=str, default='ETTh1.csv', help="你的数据数据地址")
- parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')
- parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')
- parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')
- # learning
- parser.add_argument('-lr', type=float, default=0.001, help="学习率")
- parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")
- parser.add_argument('-epochs', type=int, default=15, help="训练轮次")
- parser.add_argument('-batch_size', type=int, default=128, help="批次大小")
- parser.add_argument('-save_path', type=str, default='models')
- # model
- parser.add_argument('-hidden-size', type=int, default=64, help="隐藏层单元数")
- parser.add_argument('-kernel-sizes', type=str, default='3')
- # device
- parser.add_argument('-use_gpu', type=bool, default=False)
- parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")
- # option
- parser.add_argument('-train', type=bool, default=True)
- parser.add_argument('-predict', type=bool, default=True)
- parser.add_argument('-test', action='store_true', default=False)
- parser.add_argument('-lr-scheduler', type=bool, default=True)
- args = parser.parse_args()
参数的详细讲解->
参数名称 参数类型 参数讲解 1 model str 模型名称 2 window_size int 时间窗口大小大小需要注意window_size需要大于pre_len 3 pre_len int 预测未来数据的长度 4 shuffle bool 是否打乱dataloader中的数据 5 data_path str 你的数据地址 6 target str 你需要预测的特征列,这个值最后会保存在csv的文件里 7 input_size int 你的特征列个数不算时间那一列 8 feature str [M, S, MS],多元预测多元,单元预测单元,多元预测单元 9 lr float 学习率大小, 10 drop_out float 随机丢弃概率,不要太大 11 epochs int 训练轮次,小于30一般比较合理 12 batch_size int 一个批次的大小 13 svae_path str 模型的保存的路径 14 hidden_size int 隐藏层的单元个数 15 kernel_sizes int 卷积核大小 16 use_gpu bool 是否使用GPU 17 device int GPU的编号 18 train bool 是否进行训练 19 predict bool 是否进行预测 20 lr_scheduler bool 是否使用学习率计划。 五、模型实战
5.1 模型完整代码
下面是模型的暂时代码,后期会持续更新内容,以后的实战也会基于这个版本的框架下进行。
我们将下面的代码创建一个py文件复制进去即可运行。
- import argparse
- import time
- import numpy as np
- import pandas as pd
- import torch
- import torch.nn as nn
- from matplotlib import pyplot as plt
- from sklearn.preprocessing import MinMaxScaler
- from torch.utils.data import DataLoader
- import torch
- from torch.utils.data import Dataset
- import torch.nn.functional as F
- # 随机数种子
- np.random.seed(0)
- class TimeSeriesDataset(Dataset):
- def __init__(self, sequences):
- self.sequences = sequences
- def __len__(self):
- return len(self.sequences)
- def __getitem__(self, index):
- sequence, label = self.sequences[index]
- return torch.Tensor(sequence), torch.Tensor(label)
- def create_inout_sequences(input_data, tw, pre_len):
- # 创建时间序列数据专用的数据分割器
- inout_seq = []
- L = len(input_data)
- for i in range(L - tw):
- train_seq = input_data[i:i + tw]
- if (i + tw + pre_len) > len(input_data):
- break
- train_label = input_data[i + tw:i + tw + pre_len]
- inout_seq.append((train_seq, train_label))
- return inout_seq
- def calculate_mae(y_true, y_pred):
- # 平均绝对误差
- mae = np.mean(np.abs(y_true - y_pred))
- return mae
- def create_dataloader(config, device):
- print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")
- df = pd.read_csv(config.data_path) # 填你自己的数据地址,自动选取你最后一列数据为特征列 # 添加你想要预测的特征列
- pre_len = config.pre_len # 预测未来数据的长度
- train_window = config.window_size # 观测窗口
- # 将特征列移到末尾
- target_data = df[[config.target]]
- df = df.drop(config.target, axis=1)
- df = pd.concat((df, target_data), axis=1)
- cols_data = df.columns[1:]
- df_data = df[cols_data]
- # 这里加一些数据的预处理, 最后需要的格式是pd.series
- true_data = df_data.values
- # 定义标准化优化器
- scaler_train = MinMaxScaler(feature_range=(0, 1))
- scaler_valid = MinMaxScaler(feature_range=(0, 1))
- scaler_test = MinMaxScaler(feature_range=(0, 1))
- # 训练集、验证集、测试集划分
- train_data = true_data[:int(0.75 * len(true_data))]
- valid_data = true_data[int(0.75 * len(true_data)):int(0.80 * len(true_data))]
- test_data = true_data[int(0.80 * len(true_data)):]
- print("训练集尺寸:", len(train_data), "测试集尺寸:", len(test_data), "验证集尺寸:", len(valid_data))
- # 进行标准化处理
- train_data_normalized = scaler_train.fit_transform(train_data)
- test_data_normalized = scaler_test.fit_transform(test_data)
- valid_data_normalized = scaler_valid.fit_transform(valid_data)
- # 转化为深度学习模型需要的类型Tensor
- train_data_normalized = torch.FloatTensor(train_data_normalized).to(device)
- test_data_normalized = torch.FloatTensor(test_data_normalized).to(device)
- valid_data_normalized = torch.FloatTensor(valid_data_normalized).to(device)
- # 定义训练器的的输入
- train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)
- test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)
- valid_inout_seq = create_inout_sequences(valid_data_normalized, train_window, pre_len)
- # 创建数据集
- train_dataset = TimeSeriesDataset(train_inout_seq)
- test_dataset = TimeSeriesDataset(test_inout_seq)
- valid_dataset = TimeSeriesDataset(valid_inout_seq)
- # 创建 DataLoader
- train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)
- test_loader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)
- valid_loader = DataLoader(valid_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)
- print("通过滑动窗口共有训练集数据:", len(train_loader))
- print("通过滑动窗口共有测试集数据:", len(test_loader))
- print("通过滑动窗口共有验证集数据:", len(test_loader))
- print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器完成<<<<<<<<<<<<<<<<<<<<<<<<<<<")
- return train_loader, test_loader, valid_loader, scaler_test
- class LSTM_GRU(nn.Module):
- def __init__(self, args, device):
- super(LSTM_GRU, self).__init__()
- self.args = args
- self.device = device
- self.dropout = nn.Dropout(args.drop_out)
- self.lstm = nn.LSTM(args.input_size, args.hidden_size , batch_first=True)
- self.gru = nn.GRU(input_size=args.hidden_size , hidden_size=args.hidden_size, num_layers=1, batch_first=True)
- self.linearOut = nn.Linear(args.hidden_size, args.input_size)
- def forward(self, x):
- hidden = ((torch.zeros(1, x.size(0), self.args.hidden_size ).to(self.device)),
- (torch.zeros(1, x.size(0), self.args.hidden_size ).to(self.device)))
- x, lstm_h = self.lstm(x, hidden)
- x = self.dropout(x)
- x = F.tanh(torch.transpose(x, 1, 2))
- x = x.permute(0, 2, 1)
- x, gru_ = self.gru(x)
- x = self.dropout(x)
- x = F.tanh(torch.transpose(x, 1, 2))
- x = x.permute(0, 2, 1)
- x = self.linearOut(x)
- x = x[:, -args.pre_len:, :]
- return x
- def train(model, args, device, scaler):
- losss = []
- lstm_model = model
- loss_function = nn.MSELoss()
- optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)
- epochs = args.epochs
- lstm_model.train() # 训练模式
- for i in range(epochs):
- start_time = time.time() # 计算起始时间
- for seq, labels in train_loader:
- lstm_model.train()
- optimizer.zero_grad()
- y_pred = lstm_model(seq)
- single_loss = loss_function(y_pred, labels)
- single_loss.backward()
- optimizer.step()
- print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')
- losss.append(single_loss.detach().numpy())
- torch.save(lstm_model.state_dict(), 'save_model.pth')
- print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")
- test(model, args, scaler)
- # valid()
- def test(model, args, scaler):
- lstm_model = model
- # 加载模型进行预测
- lstm_model.load_state_dict(torch.load('save_model.pth'))
- lstm_model.eval() # 评估模式
- results = []
- reals = []
- losss = []
- for seq, labels in test_loader:
- pred = lstm_model(seq)
- mae = calculate_mae(pred.detach().numpy(), np.array(labels.detach())) # MAE误差计算绝对值(预测值 - 真实值)
- losss.append(mae)
- for j in range(args.batch_size):
- for i in range(args.pre_len):
- reals.append(labels[j][i].detach().numpy())
- results.append(pred[j][i].detach().numpy())
- reals = scaler.inverse_transform(np.array(reals))
- results = scaler.inverse_transform(np.array(results))
- print("测试集预测结果:", results)
- print("测试集误差MAE:", losss)
- plt.figure()
- plt.style.use('ggplot')
- # 创建折线图
- plt.plot(reals[:, -1], label='real', color='blue') # 实际值
- plt.plot(results[:, -1], label='forecast', color='red', linestyle='--') # 预测值
- # 增强视觉效果
- plt.grid(True)
- plt.title('real vs forecast')
- plt.xlabel('time')
- plt.ylabel('value')
- plt.legend()
- plt.savefig('test——results.png')
- def pre_dict():
- # 后期补充预测功能
- pass
- if __name__ == '__main__':
- parser = argparse.ArgumentParser(description='Time Series forecast')
- parser.add_argument('-model', type=str, default='LSTM-GRU', help="模型持续更新")
- parser.add_argument('-window_size', type=int, default=48, help="时间窗口大小, window_size > pre_len")
- parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")
- # data
- parser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")
- parser.add_argument('-data_path', type=str, default='ETTh1.csv', help="你的数据数据地址")
- parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')
- parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')
- parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')
- # learning
- parser.add_argument('-lr', type=float, default=0.001, help="学习率")
- parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")
- parser.add_argument('-epochs', type=int, default=15, help="训练轮次")
- parser.add_argument('-batch_size', type=int, default=128, help="批次大小")
- parser.add_argument('-save_path', type=str, default='models')
- # model
- parser.add_argument('-hidden-size', type=int, default=64, help="隐藏层单元数")
- parser.add_argument('-kernel-sizes', type=str, default='3')
- # device
- parser.add_argument('-use_gpu', type=bool, default=False)
- parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")
- # option
- parser.add_argument('-train', type=bool, default=True)
- parser.add_argument('-predict', type=bool, default=True)
- parser.add_argument('-lr-scheduler', type=bool, default=True)
- args = parser.parse_args()
- if isinstance(args.device, int) and args.use_gpu:
- device = torch.device("cuda:" + f'{args.device}')
- else:
- device = torch.device("cpu")
- # 读取数据地址,创建数据加载器
- train_loader, test_loader, valid_loader, scaler = create_dataloader(args, device)
- # 实例化模型
- model = LSTM_GRU(args, device).to(device)
- # 训练模型
- if args.train:
- print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始{args.model}模型训练<<<<<<<<<<<<<<<<<<<<<<<<<<<")
- train(model, args, device, scaler)
- if args.predict:
- print(f">>>>>>>>>>>>>>>>>>>>>>>>>预测未来{args.pre_len}条数据<<<<<<<<<<<<<<<<<<<<<<<<<<<")
- pre_dict()
5.2 模型训练
当我们通过章节四配置好所有的参数之后,我们就可以运行我们创建的py文件了,控制台就会进行训练,输出如下内容->

5.3 模型预测
下面的图片是模型在测试集上的表现, 可以看到效果还可以吧只能说一般,毕竟这两个结构单元只是最普通的,也没有在其中加入任何的其它高等级机制。

5.4 结果分析
当我们预测完成之后,会进行测试集验证同时会输出测试集的表现情况,后期我会添加个绘图功能在这里。

六、全文总结
到此本文已经全部讲解完成了,希望能够帮助到大家,在这里也给大家推荐一些我其它的博客的时间序列实战案例讲解,其中有数据分析的讲解就是我前面提到的如何设置参数的分析博客,最后希望大家订阅我的专栏,本专栏均分文章均分98,并且免费阅读。

-
-
相关阅读:
Excel 宏录制与VBA编程 ——VBA编程技巧篇一 (Union方法、Resize方法、Cells方法、UseSelect方法、With用法)
Java框架 MyBatis自定义映射resultMap
oracle 数据库删除序列
【笔记】Java - VM options、Program arguments、Environment variables、eclipse variables
Numpy:打开通往高效数值计算的大门
360 评估反馈工具 – 它的含义以及使用它的原因
2023 Google 开发者大会,共创、赋能开发者
PHP中的魔术方法并给出一些例子
JAVA:实现Matrix Graphs矩阵图算法(附完整源码)
创维光伏:坚持科技创新,构建中国式现代化光伏生态体系
- 原文地址:https://blog.csdn.net/java1314777/article/details/134397113
