-
记录下学的性能优化
一、性能优化的指标和工具
1.1 谷歌浏览器
- 拿淘宝网站为例,可以看到当前网页的加载信息

- 这个是瀑布图,瀑布图有横向和纵向

- 横向是具体的加载数据,悬浮看详情列表,可以看出下载时最后一个步骤,在这之前会先排队,浏览器会对优先级进行安排,它会对高优先级的请求优先请求.然后通过DNS查找域名,进行http连接,ssl验证等等,就开始发出请求,在发出请求到响应下载的过程是正在等待服务器响应(TTFB),这东西是快是慢很大程度影响用户的观感.这东西快慢一是考验后台服务器处理能力,二是网络问题.
- 最后才到下载,下载的蓝条越大,说明资源大,容易造成堵塞,等待的时间就长
- 竖向是资源与资源之间的联系,如果是串行的,容易造成堵塞,如果是并行的就会加快资源加载,也是资源加载的一个点

- 瀑布图还有两根线,蓝色那根是dom加载完成的时间,红色那根是页面所有声明的资源加载完成的时间

- 右键可保存当前性能结果

- 点击lighthouse可以查看网页评分,这些指标需要权衡来看,如果是搜索页,那么加载就快,如果是淘宝这种商城,势必会在首页中展示很多商品图片,那自然慢一点


-
页面加载过程

-
交互的三个指标:
-
1.交互响应: 例如搜索,例如二级菜单响应
-
2.页面要足够流畅:例如动画不卡顿,下滑不白屏等等
-
-
如果想要动画达到流畅的效果,就要一秒达到60帧
Ctrl + shift + p调出窗口查询frame或者搜索"每",就会出现这个监控

总结:
1.理解加载瀑布图
2.基于HAR储存与重建性能信息
3.速度指数
4.重要测量指标
性能优化-响应
1.交互动作的反馈时间
2.帧率FPS
3.异步请求的完成时间1.2RAIL测量模型
Response 响应(点击响应,不是请求响应)
Animation 动画
Idle 空闲
Load 加载RAIL评估标准:
- 响应: 处理事件应在50ms以内完成

-
动画: 每10ms产生一帧
-
空闲:尽可能增加空闲时间
尽可能把需要运算的东西给后端做,不然浏览器可能抽不出时间来响应 -
加载: 在5s内完成内容加载并可以交互
1.3性能测试工具
- Chrome DevTools开发调试、性能评测
- Lighthouse 网站整体质量评估
- WebPageTest 多测试地点、全面性能报告
1.3.1使用WebPageTest评估web网站性能
- 打开https://www.webpagetest.org/
- waterfall chart 请求瀑布图
- first view 首次访问
- repeat view 二次访问



经过等待,这是测试结果:



1.3.2如何在本地部署WebPageTest工具
- 如果项目还没上线,但是还是想看看性能,那么可以通过本地或者局域网查看
需要下载WebPageTest,为了保证通用性,使用了官方提供的docker镜像
docker安装:
- 访问Docker官网文档,按需下载对应版本安装
https://docs.docker.com/get-docker/ - 注册docker id
https://hub.docker.com/signup - 安装后点击工具栏的Docker图标,使用注册的docker id登录
- WebPageTest本地部署
(我尝试docker拉取webpagetest/server的时候发现它不在了,尝试了好久也不知道怎么下载,如果你知道,请告诉我.)
window
-
拉取镜像
docker pull webpagetest/server docker pull webpagetest/agent- 1
- 2
- 3
-
运行实例
docker run -d -p 4000:80 --rm webpagetest/server docker run -d -p 4001:80 --network="host" -e "SERVER_URL=http://localhost:4000/work/" -e "LOCATION=Test" webpagetest/agent- 1
- 2
- 3
mac 用户自定义镜像
- 创建server目录
mkdir wpt-mac-server cd wpt-mac-server- 1
- 2
- 创建Dockerfile,添加内容
vim Dockerfile FROM webpagetest/server ADD locations.ini /var/www/html/settings/- 1
- 2
- 3
- 4
- 创建locations.ini配置文件,添加内容
vim locations.ini [locations] 1=Test_loc [Test_loc] 1=Test label=Test Location group=Desktop [Test] browser=Chrome,Firefox label="Test Location" connectivity=LAN- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 创建自定义server镜像
docker build -t wpt-mac-server .- 1
- 创建agent目录
mkdir wpt-mac-agent cd wpt-mac-agent- 1
- 2
- 创建Dockerfile,添加内容
vim Dockerfile FROM webpagetest/agent ADD script.sh / ENTRYPOINT /script.sh- 1
- 2
- 3
- 4
- 5
- 创建script.sh, 添加内容
vim script.sh #!/bin/bash set -e if [ -z "$SERVER_URL" ]; then echo >&2 'SERVER_URL not set' exit 1 fi if [ -z "$LOCATION" ]; then echo >&2 'LOCATION not set' exit 1 fi EXTRA_ARGS="" if [ -n "$NAME" ]; then EXTRA_ARGS="$EXTRA_ARGS --name $NAME" fi python /wptagent/wptagent.py --server $SERVER_URL --location $LOCATION $EXTRA_ARGS --xvfb --dockerized -vvvvv --shaper none- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 修改script.sh权限
chmod u+x script.sh- 1
- 创建自定义agent镜像
docker build -t wpt-mac-agent .- 1
- 用新镜像运行实例 (注意先停掉之前运行的containers)
docker run -d -p 4000:80 --rm wpt-mac-server- 1
- 2
docker run -d -p 4001:80 --network=“host” -e “SERVER_URL=http://localhost:4000/work/” -e “LOCATION=Test” wpt-mac-agent
```1.3.3 使用Lighthouse分析性能
- 谷歌的,除了会生成性能报告以外,还会针对性地生成优化建议
- 谷歌浏览器也有自带的Lighthouse,
下载
npm install -g lighthouse- 1
使用: lighthouse 网站
lighthouse http://www.bilibili.com- 1
等到生成这个链接测试报告就是完成了
复制这个链接直接到浏览器就可以查看报告了,红色就代表做的还不够好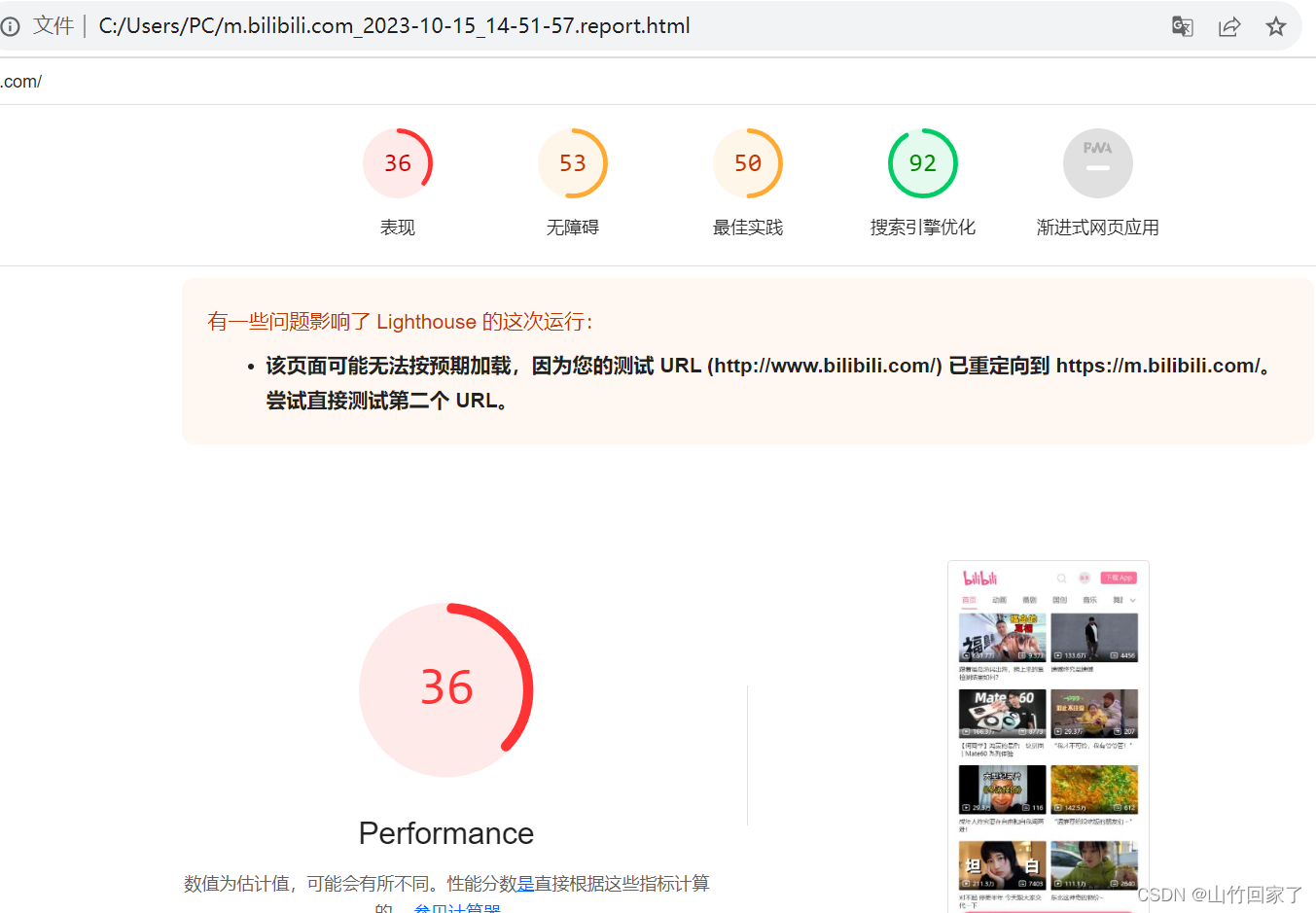

这些地方代表哪些是可以优化的建议,告诉你可以做什么,做了以后可以提升多少

例如删除一些没有使用的js,(也可能是有用的,只是后面才用到)

这些是没有问题的

如何判断js是不是必须得东西,可不可以推迟?
- 刚刚上面警告有个文件是不用显示的,我们可以在B站看到这个文件在head中,可能会引起阻塞

- Cltr + shift + p 调出窗口,查询block,选择“ show request blocking”,然后按Enter.或者中文版的选择"网络请求屏蔽"

- 输入log试一下,这时候是可以正常访问B站的,因为不受影响


- 但这是别人的网站,我们不清楚这个到底是不是必须的,只是做个比喻.如果自己网站有提示这样的警告,该资源非必须的,或者往后才使用,就无需加载着先
谷歌浏览器自带的lighthouse

1.3.4使用Chrome DevTools分析性能
- 网络传输大小可以跟实际大小不相同,例如:
- 资源返回给前端之前可以做压缩,这样经过网络的时候大小就会变小,在拿到手的时候再做解压

打开性能

- 尝试点一下刷新,箭头所指方向是主线程,随着时间推移都做了哪些任务,可以通过滚轮放大缩小,或者ctrl + 鼠标拖拽


- 开发的时候可以勾选上,测性能的时候可以去掉,可以看看再次访问时的效果

1.3.5常用的性能测量APIs
web标准APIs
- 关键时间节点
之间那些测量工具会帮我发现关键的测量节点,这些节点就是浏览器通过特定API去获取的,我们可以利用API接口直接获取数据,例如监听长任务.
<script> // 通过PerformanceObserver得到所有的long tasks对象 let observer = new PerformanceObserver((list) => { for (const entry of list.getEntries()) { console.log(entry) } }) // 监听long tasks observer.observe({ entryTypes: ['longtask'] }) </script>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

比如你做的是一个视频网站,但此时用户已经不再看你的网站了,这时候你可能考虑节流,就是不再给它进行视频的加载.那么下面这个就是知道用户是不是还在看我们的页面
<script> let vEvent = 'visibilitychange' if (document.webkitHidden != undefined) { // webkit 事件名称 vEvent = 'webkitvisibilitychange' } function webkitvisibilitychange() { if (document.hidden || document.webkitHidden) { console.log('页面不可见') } else { console.log('页面可见') } } document.addEventListener(vEvent, webkitvisibilitychange, false) </script>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

获取用户网络状态,使用场景是当用户网络好可以使用高清图,网络不好就用体积小一点的<script> let connection = navigator.connection || navigator.mozConnection || navigator.webkitConnection let type = connection.effectiveType function updateConnectionStatus() { console.log("connection type changed fron" + type + "to" + connection.effectiveType) } connection.addEventListener('change', updateConnectionStatus) </script>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

- 网络状态
- 客户端服务端协商(HTTP Client Hints) & 网页显示状态(UI APIs)
二、现代浏览器网页渲染原理
当浏览器拿到服务端返回来的资料都做了什么?
1.通过解释器将代码文本转换为浏览器能理解的数据结构浏览器是怎么转换HTMl的?
1.将文本转换为单个的字符
2.识别标签转化为节点,放到链型树形结构里,通过这棵树可以把html的属性/关系表达清楚.这棵树就叫dom浏览器构建对象模型
- 构建DOM对象
HTML => DOM - 构建CSSOM对象
CSS => CSSOM
浏览器构建渲染树
- 合并的作用就是把真正需要展示的内容留下,不需要展示的内容去除掉,例如display:none

2.1关键渲染路径
描述了触发到渲染的过程
- js: 我们可以通过Js来实现我们页面上的视觉的变化.比如添加一个dom元素,或者一个库,比如jq做一个动画,这些都会触发视觉变化.除了用js还可以有其他方法,比如用css做动画过渡,这些都可以触发视觉变化,所以这里只是叫js不太准确,它主要想说的是我们这一步是用来触发我们的视觉变化的.
- Style: 有了样式第二步就是浏览器要重新对样式进行计算,这个过程它会根据选择器进行匹配,计算出来哪些元素css受到了影响?新的规则是怎么样,应该绘制成什么样,
- Layout:就是把元素按照样式绘制到页面上,关心位置跟大小
- paint:真正把东西画到页面上
- Composite:绘制还需要跟复合结合起来.浏览器为了提高效率,不会把所有东西都放在一个层里,是分不同层去绘制,最终把它们合在一起显示给用户
理论上从第一步到最后一步都是需要经历的,但是有一些样式不会影响布局,也不会影响绘制.所以浏览器做了一些优化,实际上我们可以不经历布局和绘制这样的过程,这样渲染就大大被加速,

2.1.1布局与绘制
这是我们关键渲染路径中最重要、开销最高的两个步骤,先看看布局和绘制做了什么,然后再看如何减少布局和绘制的发生,甚至避免布局和绘制。
布局关心的是样式与大小,就是元素的几何问题,所以样式不是像高度或者offset这些的话,修改不会触发布局改变。例如修改背景图,颜色,这些不需要重新进行布局。所以在关键渲染路径中layout这步就会被跳过直接进行重绘。
绘制是像素化每个节点的过程.
有没有不进行布局与重绘的情况?
有的,有些动画是通过GPU进行加速,它是直接走Composite2.1.2影响回流的操作
通常我们第一次页面加载完把东西放到页面上的过程叫布局,如果由于之后页面又发生了一些视觉上的变化的就叫回流
- 添加/删除元素
- 操作styles
- display: none
- offset,scroll.clientWitdth
- 移动元素位置
- 修改浏览器大小,字体大小
2.1.3如何通过工具查看回流发生
<div class="MuiCardMedia-root"></div> <script> let cards = document.getElementsByClassName('MuiCardMedia-root') const update = () => { cards[0].style.width = '800px' } window.addEventListener('load', update) </script>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
打开控制台=>性能=>刷新=>查看load之后做了什么

2.1.4避免Layout thrashing(布局抖动)
当回流无法避免的时候还要注意布局抖动
let cards = document.getElementsByClassName('MuiPaper-root') const update = (timestamp) => { // 浏览器为了提升性能会把宽度这些属性操作推迟,但是当需要获得布局相关 // 的属性时,例如offsetTop ,它会不得不立即进行最新的计算,以保证能拿取最新 // 的值,所以在赋值前它被强制去进行了一次计算,但是这里是一个循环,下一轮 // 它又会执行这个操作,就会卡 for (let index = 0; index < cards.length; index++) { cards[index].style.width = ((Math.sin(cards[index].offsetTop + timestamp / 1000) + 1) * 500) + 'px' } window.requestAnimationFrame(update) } window.addEventListener('load', update)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
此时页面动画非常卡,来看看性能怎么说

每次连续不断地读写导致强制回流,会导致页面布局抖动情况,变得很卡

注意:1.避免回流,例如使用translate等,位移不会发生回流重绘,或者现在框架中的xunidom,它会先进行一个批量处理再放到真正的dom上
2.读写分离2.1.5使用FastDom
FastDom 的 git
将读跟写分离,再通过调度函数安排批量的进行读,批量的进行写,这样达到消除页面抖动的效果
使用官网查看效果

上面旧代码改造
<script> let cards = document.getElementsByClassName('MuiPaper-root') const update = (timestamp) => { for (let index = 0; index < cards.length; index++) { // cards[index].style.width = ((Math.sin(cards[index].offsetTop + timestamp / 1000) + 1) * 500) + 'px' fastdom.measure(() => { // 读取top值 let top = cards[i].offsetTop fastdom.mutate(() => { // 获取offsetTop,设置新的width cards[i].style.width = ((Math.sin(top + timestamp / 1000) + 1) * 500) + 'px' }) }) } window.requestAnimationFrame(update) } window.addEventListener('load', update) </script>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.1.6复合线程与图层
复合是关键渲染路径中的最后一步,但它跟绘制是密切相关的,为了提高绘制的效率,浏览器才有这个复合.
复合线程做什么?
- 将页面拆分图层进行绘制再进行复合
- 利用DevTools了解网页的图层拆分情况
- 哪些样式仅影响复合
复合它主要做什么?
就是把页面拆解成不同的图层,当页面图层发生视觉变化的时候,有时候这个变化可能只影响其中一个图层的变化,而其他图层不受影响,这样绘制过程就可以更高效地完成.怎么拆图层的?拆的规则是什么?
- 1.默认情况下是由浏览器来决定的,它会根据一些规则来判断是否要将我们页面去拆分成多个图层,又把哪些元素拆分成一个单独的图层,它主要分析的就是元素和元素之间是否有相互的影响,如果某些元素它对其他元素造成的影响非常的多,那它就会被提取成一个单独的图层,这样的好处是如果它发生变化,我们只对它这个图层进行相关的重绘,不影响其他图层.
- 2.我们可以主动地把这些元素提取成一个单独的图层,这样的好处是我们知道本身会影响其他元素,我们把它提取出来,让它的变化变得更加独立
如何看图层?

当前页面所有图层

以下几个属性如果提取到一个单独的图层,当发生视觉变化的时候只会触发复合,不会触发重绘,可以极大提高关键渲染路径的效率
- translate
- scale
- rotate
- opacity
2.1.7减少重绘
测试使用transform前后对比
@keyframes rotate { 0% { transform: rotate(0deg); opacity: 0.1; /*width: 300px;*/ /*transform: scaleX(1);*/ } 50% { opacity: 0.5; } 100% { transform: rotate(360deg); opacity: 0.1; /*width: 600px;*/ /*transform: scaleX(2);*/ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
使用前
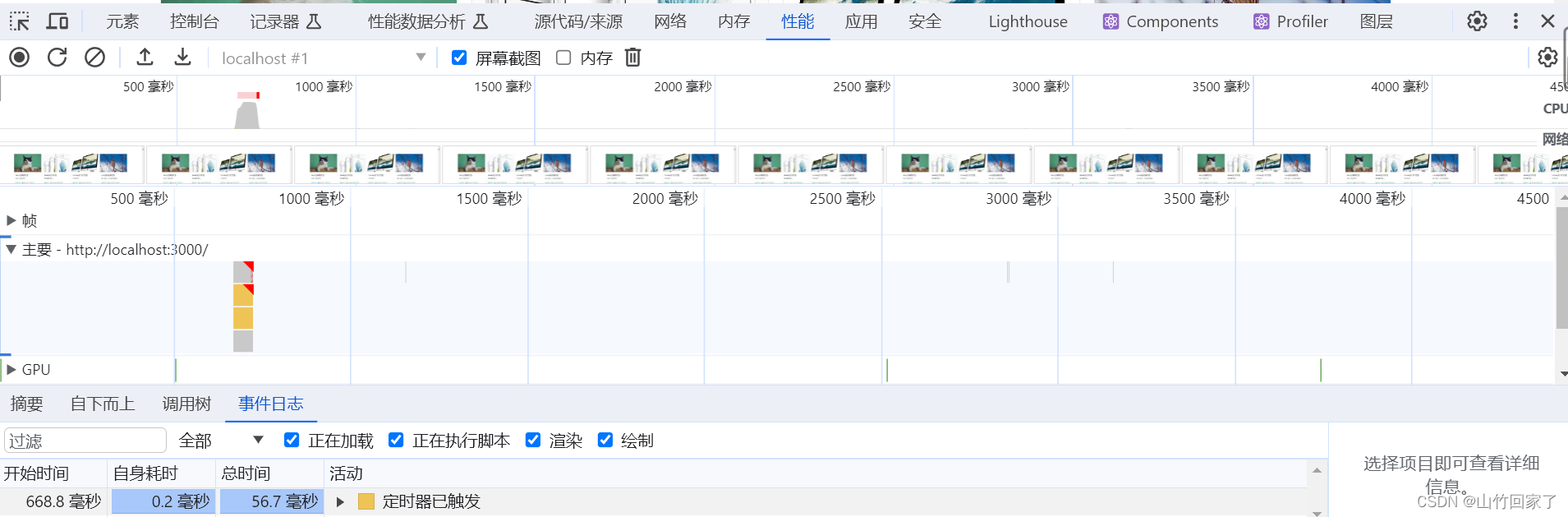
使用后它变得繁忙,但是没有导致堵塞,长任务,布局抖动之类的

没有发生布局和重绘操作

2.1.8观察页面有没有发生重绘
Ctrl + shift + p

如果有重绘的话,会在绿色区域标记出来

测试一下
@keyframes rotate { 0% { transform: rotate(0deg); /* opacity: 0.1; */ width: 300px; /*transform: scaleX(1);*/ } 50% { opacity: 0.5; } 100% { transform: rotate(360deg); /* opacity: 0.1; */ width: 600px; /*transform: scaleX(2);*/ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
绿了

对浏览器声明要提取到单独的图层去
root: { margin: theme.spacing(1), willChange: 'transform' },- 1
- 2
- 3
- 4
2.1.9高频事件处理函数 防抖
什么是高频事件?
比如scroll , touch , touch star , touch move等,这些触发频率特别高,甚至可能一帧里触发多次,也就是在一帧里要对这类事件进行多次响应.
很多时候我们并不关心滚动了多少次,只关心滚动到了哪里,如果前面滚动的任务比较重,没办法在16毫秒内完成,那就会出现卡顿测试一下
<script> let cards = document.getElementsByClassName('MuiPaper-root') // 修改图片宽度 function changeWidth(rand) { for (let index = 0; index < cards.length; index++) { cards[index].style.width = (Math.sin(rand / 1000) + 1) * 500 + 'px' } } window.addEventListener('pointermove', (e) => { let pos = e.clientX changeWidth(pos) }) </script>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

一帧的生命周期
- 事件触发 => js触发视觉的变化 => 开始一帧 => 调用rAF函数(requestAnimationFrame) => payout => 绘制
浏览器会自动帮调rAF,尽量达到60FPS的效果
requestAnimationFrame 是一个用于创建动画效果的浏览器API,它通常用于执行在浏览器的下一次重绘之前运行的函数。这是一个非常有用的功能,特别是在需要实现流畅的动画和视觉效果时。
用途:requestAnimationFrame 主要用于执行动画效果,例如平滑滚动、对象的运动、渐变变化等。通过使用这个函数,你可以确保你的动画在浏览器的每一帧之间都是平滑的,因为它会在每个浏览器重绘帧之前执行指定的回调函数。
工作原理:当你调用 requestAnimationFrame 并传递一个回调函数时,浏览器会安排这个函数在下一次重绘之前执行。这确保了动画在浏览器的帧更新周期内进行,以产生流畅的效果。浏览器通常以每秒60次(60帧/秒)的速度进行重绘。

修改完代码页面丝滑了一点
<script> let cards = document.getElementsByClassName('MuiPaper-root') function changeWidth(rand) { for (let index = 0; index < cards.length; index++) { cards[index].style.width = (Math.sin(rand / 1000) + 1) * 500 + 'px' } } // 一帧内多次触发事件,requestAnimationFrame也是没有意义的,需要的是一帧触发一次 // 防抖(debounce):把频率很高的事情变成我们需要的频率 let ticking = false window.addEventListener('pointermove', (e) => { let pos = e.clientX // 执行一次requestAnimationFrame的时候让ticking变成true // 如果为true说明有一个requestAnimationFrame的请求发出去了,那么不需要再调用 if (ticking) return ticking = true window.requestAnimationFrame(() => { changeWidth(pos) // 如果requestAnimationFrame里面的事情做完了,那再改回来,表示可以再触发 ticking = false }) }) </script>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2.1.10React时间调度实现
react 16以后实现了一个叫fiber的,就是可以将dom的修改一个批量的任务拆解成许多的小任务,然后通过时间调度,在保证高效率的同时还能保证用户的交互有足够的空闲时间.react的时间调度实现方法就是借用了上面说的requestAnimationFrame

requestIdleCallback要做什么?在什么时候做?
requestIdleCallback就是一帧的时间内做完了事情,还有剩余时间,那就可以做其他事.那request auto callback就是这个机会做额外的事情 .它跟requestAnimationFrame不同.requestAnimationFrame是在layout 和 paint之前触发,equest auto callback是在这之后.即便是能做额外的事情,但也会有一个度,因为要给主线程留更多的空余时间处理与用户的交互,至少50毫秒.
requestAnimationFrame就可以算出这个空闲时间,因为requestAnimationFrame是一帧开始的时间,然后又知道这一帧的上限时间(deedline)
但是rIC并没有被浏览器很好地支持,所以使用rAF模拟的rIC.

三、JavaScript的开销和如何缩短解析时间
3.1开销在哪里?
- 加载
- 执行
- 解析&编译
资源差不多的情况下, js的消耗更大

可以通过"性能"查看网站主要的js


js耗时占总的网络加载三分之一,js的加载很可能造成阻塞,用户即使看到了页面也没办法交互,那js执行越早,用户可以跟页面进行交互的时间就越早,所以要提高js的加载过程

3.2解决方案
- code splitting 代码拆分,按需加载,也就是当前访问的路径需要哪些资源就加载哪些资源
- Tree shaking 代码减重,比如引入一个第三方库,实际只用到1%的功能,那剩下的功能就不打进包里
从解析跟执行来看,以下几点需要注意
减少主线程工作量
- 避免长任务
- 避免超过1KB的行键脚本
- 使用rAF和rIC进行时间调度
渐进式的启动
Prigressive Bootstrapping- 可见不可交互VS最小可交互资源集
- 用户访问的三个问题:
1.让用户知道是不是发生了?
所以可以通过减少白屏时间,让用户知道访问成功了
2.这个东西是不是有用的?
有用的就是由绘制出有用的东西来决定的,可以加载一些文本或图片出来,让用户知道用户访问的对不对,有没有他想要的东西
3.能不能用?
能不能用就是能不能交互

3.3 V8编译原理
- V8是谷歌浏览器的JS引擎,它是目前做的最好,效率最高的JS引擎,也是这个原因,node js也是采用了V8这个引擎
- JS引擎拿到js脚本之后要做的第一件事就是进行解析工作,把它翻译成抽象语法树(AST),所有的编辑语言都有这个过程,它要把你的文本先识别成字符,然后再把里面重要的信息提取出来,变成节点,然后储存在数据结构里,接下来利用这个数据结构再去理解你写的东西是什么意义.
- 理解这个意义就是解析器要做的事情,再把我们的代码变成机器码去运行之前,实际上编译器会进行一些优化的工作,但是有时候它所做的自动优化工作并不一定合适,所以在运行时,当它发现它所做的这个优化不合适的时候,它还会发生逆优化的过程,就是把刚才做的优化又给去掉,反而会降低我们的运行效率
- 我们在代码层面所做的就是要尽量满足它的优化条件,它怎么去做优化,我们就按照它希望的去写代码,回避可能会造成它反优化过程的代码


3.4 V8优化机制
- 脚本流 :正常情况下是应该先下载,再解析,再执行.但是谷歌这里做了优化,它觉得如果在下载过程中也可以同时进行解析的话,可以加快这个过程.
于是它的做法是如果下载一个脚本,当超过30KB的时候就认为已经足够大,可以对这30KB的内容先进行解析,所以它会单独开一个线程给这一段进行解析,那么等所有的都加载完成之后再进行解析的时候,效率就大大提高了.这也是流式处理的特点 - 字节码缓存 :有一些东西使用的频率比较高,可以把它进行缓存,这样再次访问的时候可以加快访问.所谓字节码就是我们的源码被翻译成了字节码之后,发现其中有一些可能不仅在我当前页面,在其他页面也会被重复使用的片段.它就会把字节码缓存起来,这样当我在其他页面再次访问相同的逻辑时候可以直接从缓存中读取
- 懒解析: 这个主要是对函数而言的,虽然我们声明了函数,但是我们不一定马上会用到它,所以默认情况下会进行懒解析,就是先不去解析函数内部的逻辑,用到再解析.
3.5函数优化
函数的解析方式
- lazy parsing懒解析 vs eager parsing 饥饿解析
- 利用Optimize.js优化初次加载时间
- 我们有些函数是需要立即执行的,但是立即执行的函数默认也是先执行懒解析,等发现需要立即执行时再执行饥饿解析,实际会导致效率反而降低一半.所以需要告诉解析器,哪些函数需要立即被执行
对比一下声明前后
src\test.js
export default () => { const add = (a, b) => a*b; //只是记下,并没有解析 const num1 = 1; const num2 = 2; add(num1, num2); //开始解析 }- 1
- 2
- 3
- 4
- 5
- 6
src\App.jsx
import test from './test.js' //引入并在constructor调用 constructor(props) { super(props); this.calculatePi(1500); // 测试密集计算对性能的影响 test(); // 测试函数lazy parsing, eager parsing }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
webpack.config.js
entry: { app: './src/index.jsx', test: './src/test.js' // 测试函数lazy parsing, eager parsing }, output: { path: `${__dirname}/build`, filename: '[name].[hash].bundle.js', chunkFilename: '[name].[chunkhash:8].bundle.js' },- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
npx start
现在解析的时间是总时间1.29 毫秒,现在还是懒解析

我们自己的代码自己知道.如果当下的函数体是需要立即执行的,那么就希望解析器在记下函数的时候也把里面的逻辑解析了,这样我们调用的时候效率会高一点
src\test.js
export default () => { //在原先代码基础上加上(),表示在声明的时候,是希望同时解析,走eager parsing const add = ((a, b) => a*b); const num1 = 1; const num2 = 2; add(num1, num2); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到时间缩短了一点,(每次测的效果不一样,多测几次求平均值)

- 但是这样也会有一个问题,我们一般会对js进行压缩,webpack4之前, 当我们使用一些工具进行压缩的时候,实际又会把()给去掉,那就没办法通知到浏览器了,那么为了解决这个问题又来了一个工具叫:Optimize.js,可以帮我们把这个去除掉的括号又加回来
3.6optimize
3.7对象优化
3.7.1对象的优化有哪些?
- 以相同顺序初始化对象成员, 避免隐藏类的调整
- 实例化后避免添加新属性
- 尽量使用Array代替array-like对象
- 避免读取超过数组的长度
- 避免元素类型转换
3.7.1.1以相同顺序初始化对象成员, 避免隐藏类的调整
V8引擎解析代码时的一个小原理: JS是一个弱类型语言,我们在写的时候不会强调或声明它这个变量的类型,但实际上对于编译器而言,它最终还是得知道一个确定的类型才行.所以它会在解析的时候会推断,给变量附一个具体的类型.有21种类型,叫隐藏类型hidden class,之后所做的优化都是基于hidden class去进行的,
如下例子就创建了三个hidden class
class RectArea { // hidden class0 constructor(l, w) { this.l = l// hidden class1 this.w = w// hidden class2 } } const rect1 = new RectArea(3, 4) const rect2 = new RectArea(5, 6)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
对于编辑器而言,如果你在接下来再去创建对象的时候,还能按照这样的顺序去做,那么它就能同样地去复用这三个hidden class,也就是优化可以被复用.
反面例子
const car1 = { color: 'red' }//hidden class 0 car1.seats = 4 //hidden class 1 const car2 = { seats: 2 }//hidden class 2 (因为属性跟顺序不一致,所以没办法复用优化) car2.color = 'blue' //hidden class 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.7.1.2实例化后避免添加新属性
尽量不要以这种方式, 已经声明对象后再去给它追加属性
这样会有什么问题呢?有什么区别?// 首先我们刚开始给它进行初始化的时候,它实际上叫in object属性,就是对象从 // 开始创建就带有的属性, const car1 = { color: 'red' } // 后来追加的这种是不一样的,叫Normal/Fast属性,存储在property store里. // 它是需要通过一个描述数组间接的去查找,这样就没有对象本身的in object属性查找快 car1.seats = 4- 1
- 2
- 3
- 4
- 5
- 6
这种写法是一些老的写法,推荐写法是上面那种class写法,先声明一个class,再通过构造函数声明来初始化对象
3.7.1.3尽量使用Array代替array-like对象
什么是array-like对象?
js函数里都有一个叫arguments的对象,它包含了函数参数变量的信息.
它有什么特点?为什么叫array-like?
它本身是一个对象,但是可以通过索引访问里面的属性,它还有一个length的属性,所以就像是一个array一样,但实际上又不是数组,因为它不具有数组带的方法.例如不能用forEach遍历.
实际上如果真的是一个数组的话,V8引擎会对数组进行极大的性能优化,但只是array-like数组的话,它就做不了这些.比如调用array上的方法的时候,通过间接的方法可以达到遍历的效果,但是效率是没有真实数组上那么高.比如刚刚举的例子,我们对argument的对象里面的元素进行遍历,我们该如何做?
// 它可以是arguments对象,也可以是拿到的dom元素, // 拿到dom元素,它本身是个list,它本身也是一个类数组的对象 // 它不是数组,但是有索引,有length,往往我们要对这个list去遍历 Array.prototype.forEach.call(arrObj, (value, index) => { //不如真实数组上效率高 // 类数组可以以这种方式打印出来 console.log(`${index}:${value}`) }) // V8官方推荐:类数组还是先转为数组,然后再进行遍历 // 但是转的这步是有代价的,那这个开销跟后面做的性能优化比怎么样? // V8给出的结论就是即便把类数组对象转化为真实数组也比直接遍历强 // 类数组对象转化为真实数组 const arr = Array.prototype.slice.call(arrObj, 0) // 再遍历 arr.forEach((value, index) => { console.log(`${index}:${value}`) })- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.7.1.4避免读取超过数组的长度
这个差距可以相差6倍
function foo(array) { //length 是3,而数组是从0开始算的,所以=length时实际会越界 // 这里故意越界 for (let index = 0; index <= array.length; index++) { const element = array[index]; // 1.会造成undefined跟数字进行比较 // 2.除了即便数据类型以外所有都是对象,数组也是对象,那要是在对象找不到 // 属性以后,它会沿着原型链往上找,所以会造成额外的开销 // 3.会造成业务上代码无效/出错 if (element > 1000) { console.log(element) } } } // foo([10, 100, 1000])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.7.1.5避免元素类型转换
// 对js来讲都是数字类型,但是对编译器来讲有整数类型 // 原先定义的是整数,packed:表示数组是满的,例如定义了3个,3个都有值, // smi:代表small int 意思是在整型 const array = [3, 2, 1] //PACKED_SMI_ELEMENTS // 后面改为了4.4,那么针对上面数组所做的优化都无效了,它要对数组的类型进行 // 整改,造成额外的开销,效率就不高了 array.push(4.4) //PACKED_DOUBLE_ELEMENTS- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果类型越具体, 编辑器做的优化就更高,holey类型就是例如声明了长度为3,但是数组里面有null这样的类型也会降低优化

3.8HTML优化
html的优化空间很小,因为html在资源占比本身就比较小
3.8.1减少iframes使用
- 减少iframes使用: 在我们页面原本的基础上再嵌入独立的文档,但是额外添加了这个文档,它需要加载的过程,而且它会阻碍副文档加载的过程,如果iframes没加载完成,那副文档onload事件就不会触发.而且在iframes创建的元素相较在副文档创建同样的元素开销要高很多.
如果一定要用iframes那么可以做一个延迟加载,在副文档加载完后再加载iframes
<iframe id="a"></iframe> document.getElementById("a").setAttribute('src', 'url')- 1
- 2
3.8.2压缩空白符
空白符是为了我们开发方便阅读的,但是空白符也是占用空间的,所以在打包的时候可以去除空白符
3.8.3避免节点深层次嵌套
节点越多,最后行层dom树的时候消耗越高
3.8.4避免table布局
首先table布局使用起来没有那么地灵活,而且它造成的开销很大
3.8.5删除注释
跟删除空白符一样的道理,
3.8.6CSS&js尽量外链
行内写多了对于引擎来说不好做优化,但也有的时候是需要做在旁边,这是首屏优化的考虑方案
3.8.7删除元素的默认属性
3.9css对性能的影响
3.9.1样式计算开销
利用DevTools测量样式计算开销
样式计算所需要的开销时间

以前我们谈论到css优化的时候主要是谈论到它的复杂度计算,以及怎么降低它的复杂度,比如以前定义元素定义样式的时候会尽量就给他定单一的样式类描述样式,尽量不要使用伪类或者多层级联,因为css是自右往左读取,会把所有影响的元素过滤出来,再进行筛选.
但是随着浏览器的进步,这些复杂度已经不是最主要的问题了3.9.2降低css对渲染的阻塞
但这是无法避免的,所以1.尽量早地完成css的下载,让它尽早地解析.2.降低css的大小,例如首次加载只加载对首屏有用的css,那些用不到的就做推迟加载
3.9.3利用GPU进行完成动画
例如transform和opacity进行优化,让它们不影响我们的布局,不进行重绘跟渲染
3.9.4使用contain属性

3.9.4使用font -disply属性
让我们文字更早地显示在页面上,同时减轻文字闪动
四、资源优化
4.1资源压缩与合并
4.1.1为什么要压缩&合并
- 减少http请求数量
- 减少请求资源的大小
4.1.2HTML压缩
优化的空间并不大,包括一些谷歌代码也是没有压缩的
- 使用在线工具进行压缩
- 使用html-minifier等npm工具 :webpack压缩的时候就是集成了这个工具,可以直接github搜这个工具
4.1.3css压缩
- 使用在线工具进行压缩
- 使用clean-css等npm工具: html-minifier已经包含了
4.1.4js压缩与混淆
- 使用在线工具进行压缩
- 使用webpack对js在构建时压缩
4.1.5CSS JS文件合并
将若干个资源合并成一个文件,例如页面有20个css,如果合并成一个css可能比分开加载速度快.
但是合并这件事有人觉得好,有人觉得不好,不好是没办法渐进式加载/命名冲突等等,还有就是现在使用的缓存技术,如果全部打包成一个文件,那修改一点小小的东西也会导致整个文件过期需要重新加载.- 如果是有很多小的文件,那可以考虑合并
- 如果没有命名等冲突,并且服务于相同的模块,那可以合并
- 如果只是为了单纯优化加载,那不建议
4.2图片优化

4.2.1图片格式优化
4.2.1.1图片格式比较
JPEG/JPG
- jpg是有损压缩的图片,也就是这图片进行了很好地压缩减少体积,但还能保持色彩丰富,当压缩比达到50%的时候,画质还能保持60%.它采用24位的储存格式,2的24次方就是16000种颜色,所以看上去色彩感比较好.缺点是压缩比比较高,如果图片比较强调纹理或者边缘就不太合适.因为会模糊,例如logo就不适合用jpg.
imagemin可以生成jpg的图片,或者进一步的压缩
PNG
- 可以做透明背景的图片,色彩方面跟JPG不相上下.因为png也是24位储存,最主要可以对JPG的缺点做弥补,例如线条/边缘这些细腻的方面JPG可能不好,但png可以做到.缺点: 因为保留了比较多的细节,所以体积比较大
imagemin-pngquant可以对png图片做优化
webP
- webP是谷歌推出的图片格式,声称能跟png同样的质量,但是压缩率比png好,但其实相差不是特别大.缺点:兼容性不太好
4.2.2图片加载优化
当图片比较大的时候可以用压缩的方式减少体积,但当图片本身就已经比较小了,但是有非常多的图片时,可以考虑懒加载、渐进式图片、响应式图片
4.2.3图片的懒加载
- 原生的图片懒加载方案: 在image标签上添加loading="lazy"属性就可以了,只要浏览器支持就可以做到原生加载.但是自定义和可扩展性不是很好.
- 第三方图片懒加载的方案: verlok/lazyload , yall.js , Blazy
4.2.4使用渐进式图片
这是jpg的模式,有两种模式,一种是横扫描模式,就是加载多少展示多少,一种是渐进式,由模糊到清晰. 让UI切成这种类型保存就好

渐进式图片的优点与不足
等待时间长
渐进式图片的解决方案
如果你的美工不帮你切成渐进式,那就自己来
- progressive-image
- imageMagick
- libjpeg
- jpegtran
- jpeg-recompress
- imagemin
4.2.5使用响应式图片
需要切多张不同大小的图片, 浏览器会根据大小加载其中一张图片
- Srcset属性的使用
- Sizes属性的使用
- picture的使用 :兼容性不太好
4.3字体优化
4.3.1什么是FOIT和FOUT
- 字体未下载完成时,浏览器隐藏或自动降级,导致字体闪烁
- Flash Of Invisible Text :文字从看不到到看得到
- Flash Of Unstyled Text: 文字开始的时候是一种样式,后面变成另一种样式
这两个问题都是没办法避免的,字体网络下载需要一定的时间,只要没下载完成,那浏览器就必须做出一个选择,要么等待字体下载完把字体显示出来,要么先用已有的字体等下载完再更改.
但是总归到底,我们都希望内容先显示,所以会选择第二种状态,这个可以用一个属性控制这种行为,那就是font-display

font-display有以下几个值
- auto: 默认的值,没有什么意义
- block: 一开始不显示,如果3秒内下载完,那就显示,如果3秒没下载完,那就先用默认的字体,下载完了才换成你需要的字体
- swap: 一开始先用默认字体,等下载完以后才替换成你的字体
- fallback: block的优化,只是等待的时间变短了
- optional:判断网络好不好来决定显示默认字体还是你需要的字体,弊端是一旦做出选择就无法变更

五、构建优化
前面说的都是需要自己手动设置,但现在可以依赖webpack这些构建工具帮我们自动化完成这些任务,可以大大提升效率.
用过webpack的都知道它有很多plugin和loader帮我们做很多不同的工作,但是我们很难记住所有plugin和loader,我们每要做一个事情的时候可能要查一查用哪个plugin或者哪个loader比较合适.所以在wabpack4开始引入一个叫mode模式.
通过配置它给我们约定俗成的两个模式–开发模式和生产模式, 就可以使用它给我们默认配置好的插件,帮我们达到想要的效果,这也是计算机常用的模式,叫convention over configuration(约定大于配置).
那我们就使用它给我们配置好的就可以了,如果想对它做调整,也可以重载里面的配置,但不用大规模从头到尾进行全新的配置了.
如果对于这两个模式具体有哪些插件的话可以去官方文档查看

5.1tree shaking
很多代码在生产的包里是用不到的,所以打包前可以把这些用不到的代码去除,减少打包的体积.但无论是自己的代码还是第三方引入的代码都要基于模块化,基于ES6 import export.
如何启用tree shaking?
我们在生产模式里默认就会启用tree shaking,在配置mode中启用production就可以了.在这里它会启用TerserPlugin做压缩

webpack配置里会有一个入口,相当于一棵树的根节点,去看他引入了哪些东西,然后又会分析引入的包里面有没有引入别的东西…不断地分支分析,它会把我们需要的东西保留下来.然后那些虽然包里有引用但是没用到的东西去除.
最后留下的东西打成的包叫bundle,只包含了我们运行代码时真正需要的东西.

TerserPlugin虽然好,但是也有局限性,它的实现是基于定的规则,就是es的导入导出.但是我们js有时候会涉及到修改全局作用域, 我们的全局作用域对于前端或浏览器而言就是window对象,你可能在全局上新增了方法或者修改了属性,但是这个东西在export中是体现不出来的,如果tree shaking把这摇掉了,那代码就会出问题.
所以我们可以自己声明哪些东西不被清除.
package.json的sideEffects可以声明一个数组,把你不希望被清除的东西列出来.
最主要要列的是包含所有的css,因为我们可能会单独写css,最终会被引入到模块里,由于css肯定不是用这种模块化方式写的,所以很可能出问题.再有就是自己编写的js,如果你清楚里面可能会有影响全局作用域等,都可以列出来.

注意babel默认配置的影响
preset把常用的babel插件做了集合,相当是一个预置的集合,只要调一下这个集合就可以用到这些插件了.
我们比较常用的是preset-env,这个preset里我们可以做很多配置,但是有个问题,就是转码的时候会把es6这种模块化的语法转成其他的模块化语法,我们是肯定希望保留es6语法,所以需要加个配置 modules: false,表示不需要转成其他模块化语法

5.2js压缩
js包含我们所有的逻辑,而且往往体积比较大,所以主要做的压缩就是对js做的压缩.
webpack4刚退出来的时候是引入uglifyjs-webpack-plugin做压缩的,后来改为了terser-webpack-plugin,后者效率跟效果都比前者好,已经作为了生产环境下默认使用的插件.
5.3作用域提升
生产环境自带
- 代码体积减少: 会把有依赖关系的代码进行合并,这样就可以减少调用关系的逻辑代码
- 提升执行效率
- 同样注意babel的modules配置 : modules: false,因为这些也是要基于es6的import export语法
5.4Babel7优化配置
- 在需要的地方引入polyfill : polyfill是兼容旧浏览器进行一些新的功能或者新的规范的实现.
- 辅助函数的按需引入
- 根据目标浏览器按需转换代码
5.4.1在需要的地方引入polyfill

安装了polyfill就可以兼容了,但是polyfill把所有可能兼容的都引进来了,包很大,但是我们可能只用到一小部分.有点tree shaking的概念,我们不用的能不能就不要打包进来?
可以,设置"useBuiltIns": “usage”

5.4.2辅助函数的按需引入
什么是辅助函数?
es6中会使用class声明一个类,babel转码后会翻译成辅助函数,每当我们新生成一个类的时候,都会生成一个辅助函数.但是这东西是可以复用的,因为没有任何差异.如果可以复用的话可以减少不少代码.所以说对辅助函数的按需引入就是对辅助函数的复用.

只要把这个插件配置上就可以了
5.4.3根据目标浏览器按需转换代码
如何通过babel设置目标浏览器?
可以在数组内配置很多的配置项,比如这里配置了>0.25%,意思是要对市场份额超过0.25%的所有浏览器进行支持.babel就会根据你的配置决定转码成什么样.

可以通过browserslist查看哪些可以对browsers进行配置.
支持的越多,包越大

5.5webpack的依赖优化
使用webpack打包无论怎样都会得到一定的优化,但是webpack打包有时候本身就有一些慢.有两种方式可以加快webpack本身打包
5.5.1noParse
noParse本身的意思就是不解析
- 提升构建速度
- 直接通知webpack忽略较大的库 :通过直接配置参数告诉webpack有哪些库希望不解析.通常是我们引用的第三方类库或者是工具类可能被考虑在内,它本身是比较大的库,再加上使用的是传统的方式,也就是说没有使用模块化进行编写的,那么它本身也不会有什么外部的依赖.所以这样的库本身比较独立又比较大,可以干脆不对它进行解析了.
- 被忽略的库不能有import,require,define的引入方式
把我们确信不需要递归解析,独立的库写在这

5.5.2DLLPlugin
把经常重复使用的库提取出来变成引用方式, 这样我们就不用每一次都对这些库进行重新的构建,这样可以加速构建时间
- 避免打包时对不变的库重复构建 : 比如react ,react dom,这些从我们开始做工程到上线都不太可能更改.我们可以提取出来,变成像动态链接库的引用.也就是每次打包不需要重新构建了,只需要引用之前构建过的就可以了


运行

引用

最后正常npm run build
5.6基于webpack的代码拆分(code splitting)
代码拆分做什么?
- 把单个bundle文件拆分成若干个小的bundles/chunks
- 缩短首屏加载时间
5.6.1webpack代码拆分的方法
5.6.1.1手工定义入口
webpack.config.js就可以配置, 这种方法比较直接,但是需要自己手动维护和管理比较麻烦,而且我们一个项目里很多东西会有联系,或者重复.比如打包成两个入口,他们都用到了公共的东西,会重复,这样也是会造成浪费.所以推荐第二种

5.6.1.2splitChunks提取公有代码,拆分业务代码与第三方库
业务的东西会经常变,第三方库一般不怎么变动,从缓存的角度来看也应该进行拆分.经常变得就只影响自己,不经常变的那缓存就可以持久一点.
拆分第三方依赖
在webpack.config.js文件下
module.exports = smp.wrap({ ......其他代码 optimization: { // 分组 splitChunks: { // 将第三方库拆分出来成独立的bundle cacheGroups: { vendor: { name: 'vendor', //名字 test: /[\\/]node_modules[\\/]/, //匹配规则(匹配node_modules下所有依赖) minSize: 0,//最小大小,默认30 minChunks: 1,//拆成最小多少段 priority: 10,//设置优先级,比0大的任何数,表明越大越高 chunks: 'initial'//同步加载 }, } } },- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
执行npm run build


提取公共代码
扫自己代码里面公共的引用
module.exports = smp.wrap({ ......其他代码 optimization: { // 分组 splitChunks: { cacheGroups: { common: { name: 'common', test: /[\\/]src[\\/]/, chunks: 'all', //动静态引入都包含 minSize: 0, minChunks: 2 } } } },- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.6.1.3动态加载
不同框架有提供不同的动态加载方案,这里以webpack为例: 当用到card的时候再动态加载,加载完之后再做相关逻辑处理.

5.7基于webpack的资源压缩(minification)
前面也有讲一些资源压缩,这里是系统地去讲webpack是怎么对js、html、css进行压缩的.
- terser压缩js : mode:production时默认配置
- mini-css-extract-plugin压缩css
- HtmlWebpackPlugin-minify压缩HTML
mini-css-extract-plugin
react是用js的形式写样式,这个插件可以帮我们把样式抽离成独立的css文件,这样的好处是把css跟js做了拆分,它们的加载相互不受影响
optimize-css-assets-webpack-plugin
拆分完以后就进行压缩
webpack.config.js
new MiniCssExtractPlugin({ filename: '[name].[contenthash].css', //提取出来对应的js文件名字, chunkFilename: '[id].[contenthash:8].css',//chunk是代码拆分的时候拆出来的代码段 }), new OptimizeCssAssetsPlugin({ cssProcessorPluginOptions: { preset: ['default', {discardComments: {removeAll: true}}], // 去除注释 }, canPrint: true }),- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5.8基于webpack的资源持久化缓存
- 每个打包的资源文件有唯一的hash值
- 修改后只有受影响的文件hash变化
举例子:webpack.config.js
output: { path: `${__dirname}/build`, filename: '[name].[hash].bundle.js', //没有进行按需加载的文件,命名方式:文件名+整个应用唯一哈希值 chunkFilename: '[name].[chunkhash:8].bundle.js' //按需加载被拆出来的代码,命名方式:文件名+chunkhash, //如果代码拆分,每个动态的组件对应若干个不同的chunk|代码段 //每个代码段都有自己唯一的hash },- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
目前打出来的包css跟js都是一样的哈希,如果想让它们更独立一点,就把css的地方从hash改成contenthash

5.9基于webpack的应用大小检测与分析
- 三个工具:
- Stars 分析与可视化图
- webpack-bundle-analyzerc 进行体积分析
- speed-measure-webpack-plugin 速度分析
前两个是对代码进行静态分析,了解bundle里面每一个模块体积是怎么样的?最后一个是关注速度.
5.9.1webpack chart
webpack --profile --json > stats.json- 1
通过命令把我们的分析数据导出,这时候会生成一个stats的文件, 将这个文件上传到这里,就会生成一个分析图表.(我没成功,就不放图了…)
5.9.2 webpack-bundle-analyzerc
5.9.3speed-measure-webpack-plugin
npm install speed-measure-webpack-plugin- 1
webpack.config.js 引入
const SpeedMeasurePlugin = require("speed-measure-webpack-plugin") const smp = new SpeedMeasurePlugin() // 包裹webpack的配置 module.exports = smp.wrap({ ...其他代码 });- 1
- 2
- 3
- 4
- 5
- 6
- 7
npm run build以后会有分析报告

六、传输加载优化
6.1启用压缩Gzip
6.2启用keep Alive
- 这个技术可以对tcp链接进行复用,当我们和一台tcp服务器进行连接以后,接下来所有的请求都不需要重复地建立这个链接了.这样对请求量比较高的网站而言,就可以大大地节约我们在网络加载时的开销.
- 它也是http的一部分,多数情况下是有益无害的,所以从http1.1开始,keep Alive是默认给我们开启的.

nginx的一些配置: keepalive_timeout,意思是超时时间,当客户端和服务端进行了tcp链接的建立之后,我们服务端会尽量给它保持住这个TCP链接,但是如果不用tcp链接的话,超时就会关掉.
0代表不启用keepalive_timeoutkeepalive_timeout
keepalive_requests: 从我们客户端和服务端建立TCP连接之后会开始计数,这个数值就是一共可以发送多少个请求,达到这个数值以后就会关掉tcp链接,重新连接.为什么要设置时间跟上限?
所有东西都是需要开销的,如果你的用户非常多,那么你的这个服务器上就要为这些用户保持住这个tcp链接.开销就大了
6.3http资源缓存
主要是为了提高用户再次访问网站的速度
- 方案:
Cache-Control/Expires
Last-Modified + If-Modified-Since
Etag + If-None-Match
更多详细介绍可以看:mdn链接

平时开发的时候会频繁更改想要看最新的效果,所以会勾选上禁用缓存
但是现在看看去除禁用缓存后的效果

nginx的配置
- 第一个条件是去匹配html,把html单拎出来做一个场景是因为主流的框架都是以单页面为主,单页面的特点就是只有一个html作为入口,我们所有的资源都是通过这个html文件进行后续的加载.
如果说有一天要进行资源的更新,那我们肯定是希望用户能够及时拿到这个更新,但是缓存带来的一个问题是如果缓存没有过期,那用户他始终就是拿的旧文件.所以这个html是不希望它被缓存的,而且html文件也不大.所以我们需要对html禁用缓存.
Cache-Control是http1.1的标准,有两个参数,no-cache指告诉客户端不需要缓存,每次需要文件就去服务端重新获取.must-revalidate是指获取玩要重新验证.
后面pragma跟expires是为了兼容非主流浏览器 - 第二个条件是匹配js跟css,设置7天缓存时间,但是实际上上面对webpack文件做了hash处理,如果文件有变化,那么也会更新
- 第三个条件是对图片等一系列的缓存,这些一般比较少更改,时间实际还能改的再长一点

html
表示了不要使用缓存就真的不用缓存了吗?
不是,它会先跟服务器问一下需不需要跟服务器拿?如果没有变动,它的状态会变成304,然后就可以继续拿缓存.
如何知道资源有没有发生变化呢?
Etag是文件资源的唯一标识,是服务端生成的,它会告诉服务端标识是什么?在第一次请求的时候就会带过来

当再次请求的时候就会问服务端,Etag还匹不匹配?如果不匹配了,那就要拿最新的资源,如果匹配就会返回304

js/静态资源
这个是截止2日期,在这个时间内,只要不是强制要求向服务器拿资源,那都是拿缓存
6.4Service workers
优点:
- 加速重复访问 :加快第二次访问的时间
- 离线支持 : 没有网的情况下也能从缓存里拿数据
注意:
- 延长了首屏时间,但页面总加载时间减少
- 兼容性
- 只能在localhost或者https下使用
Service Worker概念和应用介绍
科普 | Service Worker 入门指南
6.5http/2的提升
- 二进制传输
- 请求响应多路复用
- Server push
如何查看是什么协议?

6.6 SSR的好处
- 加速首屏加载
- 更好的SEO(搜索引擎优化)

在客户端渲染的时候我们需要把页面请求过来,然后看页面上关联的js,再把js加载进行解析,然后才能让用户看到我们页面真正要去显示的内容.那这个过程势必会延迟首屏时间.
如果用服务端渲染的话,这个时间可以大大被提前,因为从服务端传给客户端时已经是渲染之后的HTML了.就不需要经过上面一长串的步骤.另外由于从服务端传给客户端时现成的html,搜索引擎可以很好地进行索引.七、前沿优化解决方案
7.1资源优先级
- preload: 提前加载较晚出现, 但对当前页面非常重要的资源
- prefetch: 提前加载后继路由需要的资源, 优先级低
7.2预渲染的作用
- 大型单页应用的性能瓶颈: js下载 + 解析 + 执行
- SSR的主要问题: 牺牲TTFB来补救First Paint ;实现复杂
- Pre-rendering 打包时提前渲染页面,没有服务端参与
7.3windowing的作用
- 加载大列表、大表单的每一行严重影响性能
- Lazy loading仍然会让DOM变得过大
- windowing只渲染可见的行,渲染和滚动的性能都会提升
-
相关阅读:
在组件中显示tuku的照片
华为云云耀云服务器L实例评测|安装Java8环境 & 配置环境变量 & spring项目部署 &【!】存在问题未解决
npmjs官网(查询依赖包)
Hbase的shell命令(详细)
【Linux】管道
IDEA自动注解设置(中文版)
Vmware中安装win7虚拟机以及相关简单知识
在浏览器地址栏键入URL按下回车之后会经历什么?
artifactory配置docker本地存储库
手撕 视觉slam14讲 ch7 / pose_estimation_3d2d.cpp (1)
- 原文地址:https://blog.csdn.net/weixin_47886687/article/details/132996613
