-
MySQL的执行器是怎么工作的
作为优化器后的真正执行语句的层,执行器有三种方式和存储引擎(一般是innoDB)交互
- 主键索引查询
查询的条件用到了主键,这个是全表唯一的,优化器会选择const类型来查询,然后while循环去根据主键索引的B+树结构一条一条的查询是否符合条件,符合就发给客户端,不符合就跳过该条记录。(是一条一条的发送回server层的,只不过server要等到全部查询结束才会返还用户)。第一次查询会调用read_first_record来查询,后续while循环调用read_record继续查询 - 全表扫描
没有任何索引能用,那么优化器会选ALL类型的查询,同理,read_first_record,然后while调用read_record一条一条查询是否符合条件,符合就发回server层,反之跳过继续查询 - 索引下推
能够减少回表次数,提升查询效率,因为其将server层负责的事情下推到存储引擎层来处理了(尽管仍然没法完全发挥联合索引的功效),下面这个定位到age>20后:1、正常来讲要在二级索引B+树定位到age>20的第一条记录后,根据主键id去回表,将完整一行记录返回server层,然后在server层判断reward是否>100000,成立则发回客户端,否则跳过记录让存储引擎继续查;2、但是现在有索引下推了,在定位到第一条记录后,直接让存储引擎判断reward>100000不,成立的话回表然后发送数据给server层,否则直接跳过。优化器会采取Using index condition类型,代表使用了索引下推。
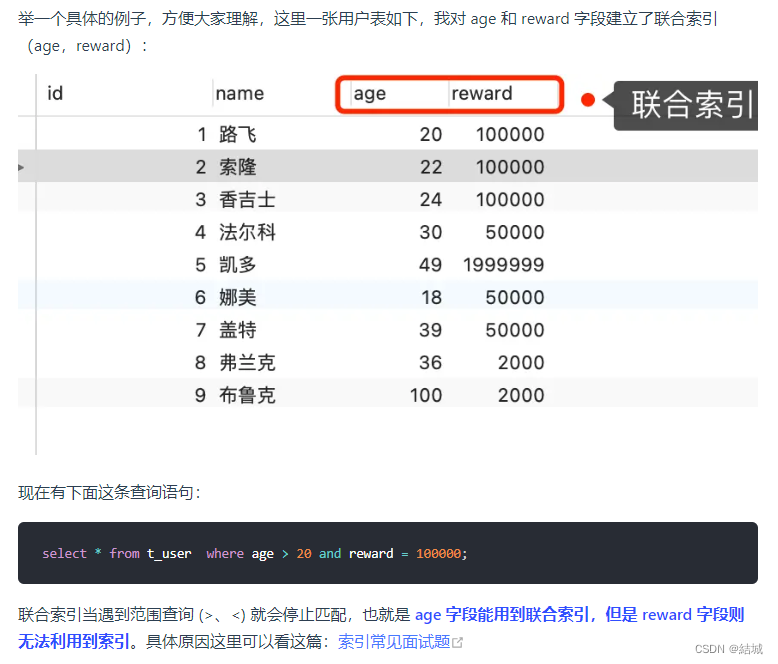
- 主键索引查询
-
相关阅读:
内核动态打印
搭建STM32F407的Freertos系统(基于STM32CubeMX)
uniapp实现拍照涂鸦
js设计模式:适配器模式
[Linux]关于在国产操作系统上安装Oracle数据库
一同走进Linux的“基操”世界
大模型 Decoder 的生成策略
【JavaScript高级】手写apply()、call()、bind()
uniapp打包安卓后在安卓屏上实现开机自启动
Pytorch预训练模型和修改——记录
- 原文地址:https://blog.csdn.net/pige666/article/details/134445391