-
【Linux】第十七站:进程创建与进程终止
一、进程创建
1.fork函数
在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#includepid_t fork(void); - 1
- 2
返回值:子进程中返回0,父进程返回子进程id,出错返回-1
进程调用fork,当控制转移到内核中的fork代码后,内核做如下几步
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork返回,开始调度器调度

当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程了
如下所示,可以简单的验证一下结果
#include#include int main() { printf("pid: %d,before\n",getpid()); fork(); printf("pid: %d, after\n",getpid()); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行结果为:

这其实就是因为如下图所示,父进程创建了子进程以后,他们的虚拟地址经过页表映射后,指向同样的代码和数据。

2.写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。具体见下图:
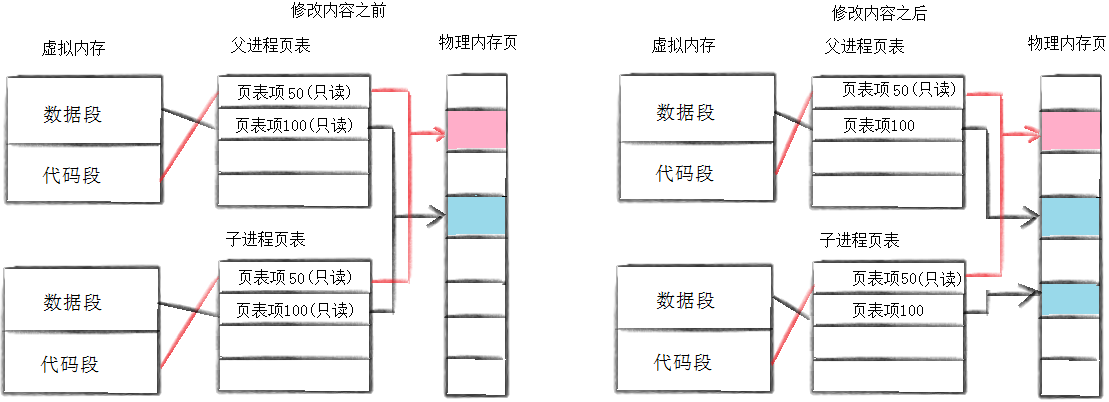
它会将代码和数据设置为只读的,当页表进行写的时候,直接进行写时拷贝即可
3.批量化创建多个进程
我们使用如下,代码
#include#include #include #define N 5 void runChild() { int cnt = 10; while(cnt) { printf("i am a child,pid:%d,ppid:%d\n",getpid(),getppid()); sleep(1); cnt--; } } int main() { int i = 0; for(i = 0; i < N; i++) { pid_t id = fork(); if(id == 0) { runChild(); exit(0); } } sleep(1000); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
在这段代码中,我们可以瞬间批量化创建五个进程。当子进程运行完它需要做的部分的时候,直接退出进程。
接下来我们可以对这些进程进行监控
while :; do ps ajx | head -1 && ps ajx | grep -v grep | grep -v nvim | grep test;echo "-------------------------------";sleep 1 ; done- 1
如下所示

这是一开的状况,后面所有的子进程都会进入僵尸状态

我们也同时可以注意到
如果有多个进程,那么哪一个进程先执行完全是由调度器所决定的

所以我们的父子进程被创建出来以后,谁先运行我们完全不可知
二、进程终止
我们知道,在我们以前写代码的时候,最后总是会return 0,那么为什么这个main函数总是会返回0,如果返回1呢,2呢?其他值呢?可以吗?这个东西是给谁了?为什么要返回这个值?
1.进程退出场景
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
对于一个代码运行完毕,结果正确,我们不会关心它是为什么跑正确的
但是当一个代码运行完毕,结果不正确,我们就会关心为什么不正确?
#includeint main() { printf("模拟一个逻辑的实现\n"); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
在这个代码中,这个0代表的就是进程的退出码,表征进程的运行结果是否正确,如果是0代表的就是正确

当我们运行完这个进程以后,我们可以用下面的指令来查看是否正确
echo $?- 1
那么在进程中,谁会关心我运行的情况呢?
一般而言是我们的父进程会关心的。所以我们上面的bash就是我们程序的父进程,是可以拿到对应的退出码的
而我们的关心主要关心的就是不正确的情况,因为成功只有一种情况,而失败可以有无数种情况
所以可以用return的不同的返回值数字,表征不同的出错原因—退出码
所以我们的main函数的返回值可以是其他的任意值


所以main函数的返回值,本质表示:进程运行完成时是否是正确的结果,如果不是,可以用不同的数字,表示不同的出错原因!
不过对于上面这个打印退出码的这个指令,我们需要注意

我们只有第一次打印是我们前面的退出码,当我们多打印几次就都变成了0
所以说,
$?保存的是最近一次进程退出的时候的退出码当我们后面的几次,其实打印的是echo这个指令的退出码了。
像我们之前的那些程序,其实不怎么关注退出码,因为并没有涉及到多进程等等,但是未来我们是看不到这些错误信息。所以我们就需要用退出码来标识。
不过对于退出码,它现在的这些只是单纯的数字,我们人并无法直接的知道它的意思,所以我们就有一个函数吗,可以将退出码转化为字符串

我们可以试着用如下代码,打印出所有的错误码
#include#include #include #include int main() { int i = 0; for(; i < 200; i++) { printf("%d:%s\n",i,strerror(i)); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行结果如下所示

所以就好比下面的例子,因为找不到这个文件,所以它会直接将错误码返回并解析

当指令正确运行的时候,毫无疑问,退出码就是0

所以系统提供的错误码和错误码描述是具有对应的关系的。
我们可不可自己设计一套错误码体系呢?
当然是可以的,也是非常的简单的,直接定义这样一个指针数组就可以了

不过父进程为什么要关心这个退出码呢?
其实父进程也不是很关心的,它也相当于一个跑腿的。
真正关心的应该是用户,用户根据错误的描述,才能决定下一步执行什么操作
所以最终无论结果正确与否,统一会采用退出码来进行判定!!!
我们继续用下面的代码来验证
#include#include #include #include int main() { int ret = 0; char* p = (char*)malloc(4*1000*1000*1000); if(p == NULL) { ret = 1; printf("malloc fail\n"); } else { printf("malloc success\n"); } return ret; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

像我们在之前C语言中也有一个很类似的全局变量,errno

它保存的是最近一次执行的错误码,比如当我们调用库函数的时候,就会发生失败,就会设置这个错误码。
它的用法如下
#include#include #include #include #include int main() { int ret = 0; char* p = (char*)malloc(4*1000*1000*1000); if(p == NULL) { ret = errno; printf("malloc fail,%d:%s\n",errno,strerror(errno)); } else { printf("malloc success\n"); } return ret; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行结果为

以上都是对前两种场景的分析
但是还有第三种情况,代码异常了。那么此时退出码还有意义吗?
代码如果异常了,那么代码很可能就没有跑完
此时进程的退出码无意义,因为我们已经不关心退出码了
那么要不要关心为什么异常了呢?以及发生了什么异常
其实异常就如同下面的样子


这里就是发生了野指针错误
又或者,写出了这样的代码

此时的就会提示浮点数异常

一般而言,进程出现了异常,本质是我们的进程收到了对应的信号!

如上所示,8号信号其实就是我们刚刚发生的浮点数异常,11号信号就是段错误,也就是野指针错误
我们可以用下面的代码来验证一下

当我们使用8号和11号信号的时候,结果如下

这就证明了异常的本质是我们的进程收到了对应的信号!
2.进程退出的方法
正常终止(可以通过 echo $? 查看进程退出码)
- 从main返回
- 调用exit
- _exit
异常退出
ctrl + c,信号终止
(1)exit和return
exit的介绍如下

我们可以简单的使用一下

运行结果为
或者我们可以直接使用return来返回,他们两个在main函数种是完全等价的
那么exit和return有什么区别呢?
我们观察如下代码


所以现在,我们就知道了
exit在任意地方调用,都表示调用的进程直接退出,而return只表示当前函数返回,还会继续向后运行
(2)_exit和exit
_exit是一个系统调用

它也可以直接退出当前进程


那么这两个有什么区别呢?
我们先看这段代码

运行结果为

我们在看看这段代码


我们发现第二次是没有打印出来的,而第一次是打印出来的
所以说
_exit是纯正的系统调用,它会直接终止进程,对缓冲区的数据不做刷新
exit它在终止之前会下做一些清理函数,冲刷缓冲区,是一个库函数
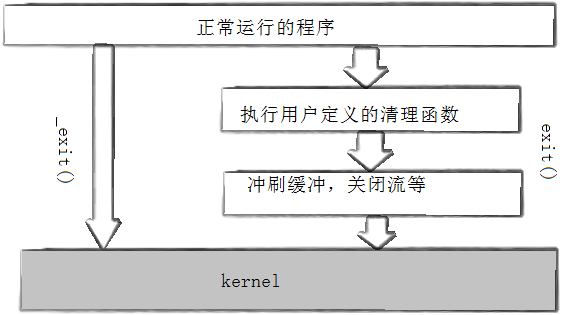
我们可以这样理解,exit 和 _exit是一个调用和被调用的关系
像printf这个函数也是类似的
这个函数一定是先把数据写入缓冲区,合适的时候,在进行刷新。
那么这个缓冲区绝对不在哪里?
根据我们上面的现象,这个缓冲区一定不在内核中
因为如果在操作系统内部,那么执行_exit这个系统调用的时候,它一定会刷新缓冲区。因为操作系统不做任何浪费时间和空间的事情。

-
相关阅读:
vue slot插槽的使用
typescript核心
linux中使用redshift进行防蓝光
Go结构体深度探索:从基础到应用
Linux下查看根目录各文件内存大小
java基于ssm+vue+elementui的宠物医院挂号管理系统
【智能优化算法 】基于适应度相关优化器求解单目标优化问题附matlab代码
07 数据库查询(1) | OushuDB 数据库使用入门
当语文课本上的古诗词遇上拓世AI,文生图绘就东方美学画卷
python3.8,torch1.10.2+cu113、torch-geometric 安装
- 原文地址:https://blog.csdn.net/jhdhdhehej/article/details/134461181
