-
使用 Python进行量化交易:前向验证分析
运行环境:Google Colab
1. 利用 yfinance 下载数据
import yfinance as yf ticker = 'AAPL' df = yf.download(ticker) df- 1
- 2
- 3
- 4
- 5
- 下载苹果的股票数据
df = df.loc['2018-01-01':].copy() df- 1
- 2
- 3
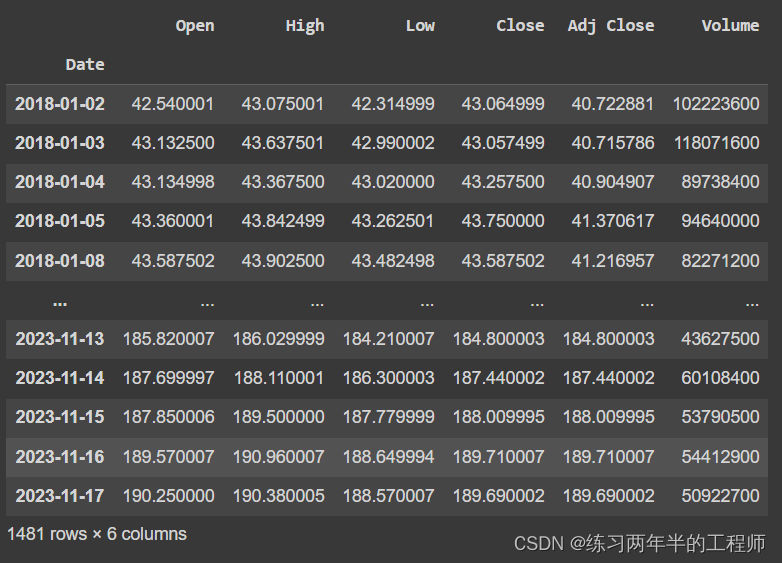
df['change_tomorrow'] = df['Adj Close'].pct_change(-1) df.change_tomorrow = df.change_tomorrow * -1 df.change_tomorrow = df.change_tomorrow * 100 df- 1
- 2
- 3
- 4
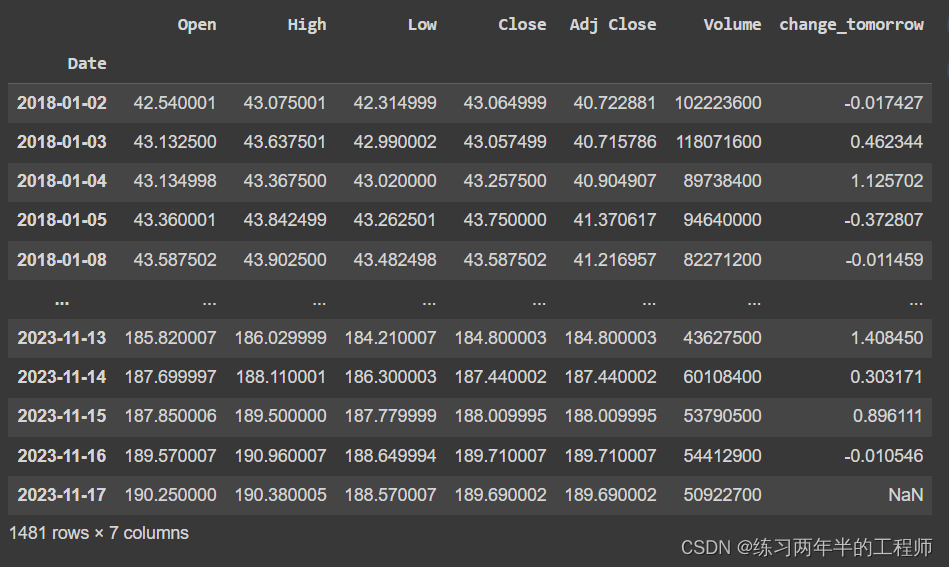
df = df.dropna().copy() df- 1
- 2
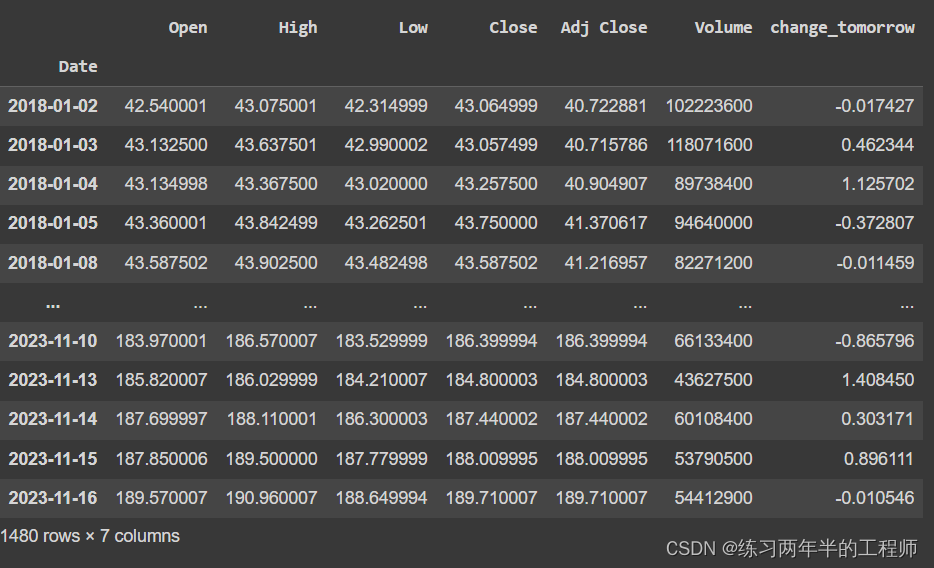
2. 变量准备
y = df.change_tomorrow X = df[['Open','High','Low','Close','Volume']]- 1
- 2
3. 时间序列数据的交叉验证
from sklearn.model_selection import TimeSeriesSplit ts = TimeSeriesSplit(test_size=200)- 1
- 2
- 3
- 使用了
Scikit-learn库中的TimeSeriesSplit方法来创建时间序列交叉验证的实例。 test_size=200表示将数据集分成多个交叉验证折叠(folds),并且每个折叠的测试集大小为 200 个样本。
4. 随机森林回归模型来进行时间序列交叉验证
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error model_dt = RandomForestRegressor(max_depth=15, random_state=42) error_mse_list = [] for index_train, index_test in ts.split(df): X_train, y_train = X.iloc[index_train], y.iloc[index_train] X_test, y_test = X.iloc[index_test], y.iloc[index_test] model_dt.fit(X_train, y_train) y_pred = model_dt.predict(X_test) error_mse = mean_squared_error(y_test, y_pred) error_mse_list.append(error_mse)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 使用之前创建的时间序列交叉验证实例
ts在数据集df上进行拆分,index_train,index_test是每次交叉验证的训练集和测试集的索引。 - 使用随机森林模型
model_dt对训练集进行拟合。 - 使用训练好的模型对测试集的特征进行预测,得到预测结果
y_pred。 - 使用均方误差(MSE)方法,计算了真实值
y_test和预测值y_pred之间的均方误差。
error_mse_list- 1
[9.29226288135296,
6.621204525309144,
5.117431788350876,
5.570462756189788,
2.627530106136459]5. 在每个交易周期根据模型的预测值执行买入或卖出操作
from backtesting import Backtest, Strategy class Regression(Strategy): limit_buy = 1 limit_sell = -5 n_train = 600 coef_retrain = 200 def init(self): self.model = RandomForestRegressor(max_depth=15, random_state=42) self.already_bought = False X_train = self.data.df.iloc[:self.n_train, :-1] y_train = self.data.df.iloc[:self.n_train, -1] self.model.fit(X=X_train, y=y_train) def next(self): explanatory_today = self.data.df.iloc[[-1], :-1] forecast_tomorrow = self.model.predict(explanatory_today)[0] if forecast_tomorrow > self.limit_buy and self.already_bought == False: self.buy() self.already_bought = True elif forecast_tomorrow < self.limit_sell and self.already_bought == True: self.sell() self.already_bought = False else: pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
limit_buy = 1和limit_sell = -5:买入和卖出的阈值。n_train = 600和coef_retrain = 200:用于模型训练的数据量和重新训练的频率。def next(self):: 这是每个交易周期调用的方法,用于执行具体的交易操作。
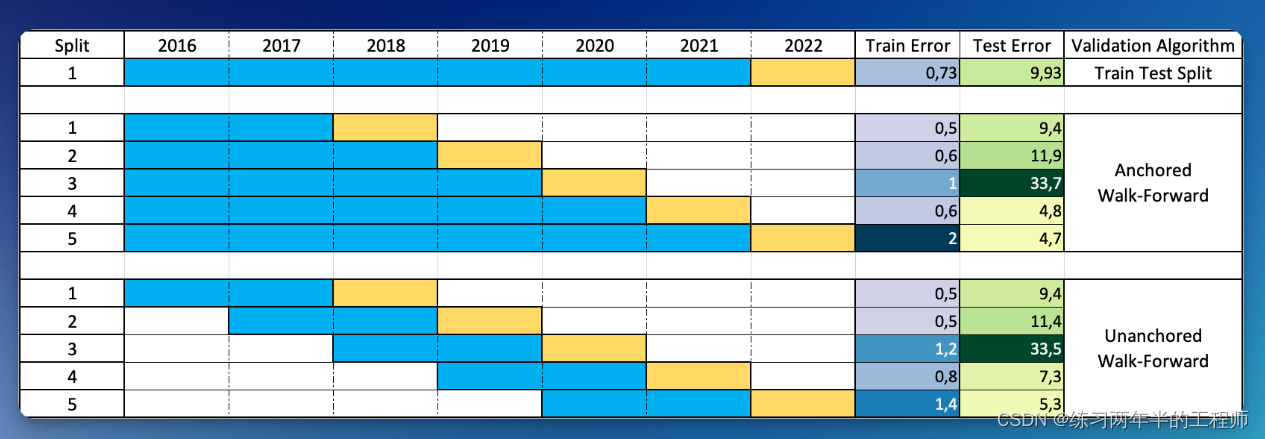
在前向优化中,回测数据被分成多个样本内和样本外段。策略在每个样本内段(蓝色)上进行优化,然后最优参数被应用到紧随其后的样本外段(黄色)。这种样本内优化和样本外测试的循环将随着整个数据集的进行而重复,形成一系列样本外回测。Anchored Walk-Forward “锚定型”:样本内时间窗口始终从历史数据序列的开始开始,并逐步增加。
Unanchored Walk-Forward “非锚定型”:样本内时间窗口始终具有相同的持续时间,并且每个时间窗口都在前一个时间窗口之后开始。
6. 每经过一定时间后重新训练模型,以适应新的市场情况
class WalkForwardAnchored(Regression): def next(self): # we don't take any action and move on to the following day if len(self.data) < self.n_train: return # we retrain the model each 200 days if len(self.data) % self.coef_retrain == 0: X_train = self.data.df.iloc[:, :-1] y_train = self.data.df.iloc[:, -1] self.model.fit(X_train, y_train) super().next() else: super().next()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
if len(self.data) < self.n_train:: 这部分代码检查数据集长度是否小于预先设定的训练数据量n_train。如果是,表示数据还不足以进行模型训练,于是不执行任何操作,直接跳转到下一个交易日。if len(self.data) % self.coef_retrain == 0:: 这部分代码检查当前数据长度是否达到了重新训练模型的时间节点(每经过coef_retrain天就重新训练一次模型)。- 从当前数据集中重新获取特征集
X_train和目标集y_train。 - 使用这些数据重新训练模型
self.model。
from backtesting import Backtest bt = Backtest(df, WalkForwardAnchored, cash=10000, commission=.002, exclusive_orders=True)- 1
- 2
stats_skopt, heatmap, optimize_result = bt.optimize( limit_buy = range(0, 6), limit_sell = range(-6, 0), maximize='Return [%]', max_tries=500, random_state=42, return_heatmap=True, return_optimization=True, method='skopt' ) dff = heatmap.reset_index() dff = dff.sort_values('Return [%]', ascending=False) dff- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
index limit_buy limit_sell Return [%] 0 0 -6 128.2607345315552 2 0 -4 128.2607345315552 1 0 -5 128.2607345315552 3 0 -3 118.6897769815064 6 1 -5 72.99951079330444 7 1 -4 72.99951079330444 8 1 -3 65.70472863082887 16 3 -4 0.0 23 5 -5 0.0 22 4 -1 0.0 21 4 -2 0.0 20 4 -3 0.0 19 4 -5 0.0 18 3 -2 0.0 17 3 -3 0.0 12 2 -4 0.0 15 3 -5 0.0 14 2 -1 0.0 13 2 -3 0.0 11 2 -5 0.0 10 2 -6 0.0 24 5 -4 0.0 4 0 -2 -15.848805708007804 9 1 -1 -37.85255523803709 5 0 -1 -48.291288581848114 7. 使用最近的
n_train天数据作为训练集,从而保持模型更敏感地反映最近的市场情况class WalkForwardUnanchored(Regression): def next(self): # we don't take any action and move on to the following day if len(self.data) < self.n_train: return # we retrain the model each 200 days if len(self.data) % self.coef_retrain == 0: X_train = self.data.df.iloc[-self.n_train:, :-1] y_train = self.data.df.iloc[-self.n_train:, -1] self.model.fit(X_train, y_train) super().next() else: super().next()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
bt_unanchored = Backtest(df, WalkForwardUnanchored, cash=10000, commission=.002, exclusive_orders=True) stats_skopt, heatmap, optimize_result = bt_unanchored.optimize( limit_buy = range(0, 6), limit_sell = range(-6, 0), maximize='Return [%]', max_tries=500, random_state=42, return_heatmap=True, return_optimization=True, method='skopt' ) dff = heatmap.reset_index() dff = dff.sort_values('Return [%]', ascending=False) dff- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
index limit_buy limit_sell Return [%] 0 0 -6 128.2607345315552 1 0 -4 128.2607345315552 2 0 -3 118.6897769815064 5 1 -5 72.99951079330444 6 1 -4 72.99951079330444 7 1 -3 65.70472863082887 15 3 -4 0.0 22 5 -5 0.0 21 4 -1 0.0 20 4 -2 0.0 19 4 -3 0.0 18 4 -5 0.0 17 3 -2 0.0 16 3 -3 0.0 12 2 -3 0.0 14 3 -5 0.0 13 2 -1 0.0 11 2 -4 0.0 10 2 -5 0.0 9 2 -6 0.0 23 5 -4 0.0 3 0 -2 -16.90633944244384 8 1 -1 -34.242432039184564 4 0 -1 -46.87595996093751 -
相关阅读:
Jmeter如何进行接口测试-实操
C#:初识结构体、数组、冒泡排序。
东数西算开启算力网络大时代,“九阶评估模型”能带来什么?
SH-SSS丨《ISSD: 基于迭代式语音分离的说话人日志系统》论文线上分享
10 分钟教会你如何看懂 MySQL 执行计划
vue快速学习02、基础用法
知网网站地址更换
袋鼠云思枢:数驹DTengine,助力企业构建高效的流批一体数据湖计算平台
Python 编程基础 | 第五章-类 | 5.8、运算符重载
Shell 解释器,帮你解析一条Shell语句到底是什么意思
- 原文地址:https://blog.csdn.net/weixin_57266891/article/details/134477891
