-
GFS分布式文件系统
GFS分布式文件系统:
gfd glusterFS 开源的分布式的文件系统
存储服务器 客户端 以及网络(NFS/samba)网关
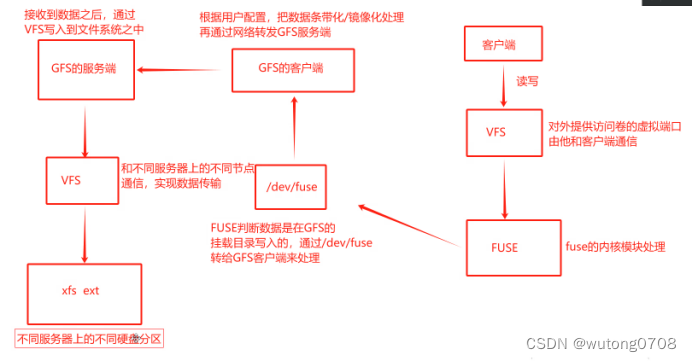
传统的老的分布式系统源服务器,原服务器保存了存储节点的目录树信息,一旦源服务器故障,所有的存储节点全部失。
现在GFS取消了源服务器机制,数据横向扩展能力更强,可靠性更强,存储效率更高,
GFS的特点:
- 扩展性和高性能,都很出色
- 高可用,可以自动对文件进行复制,还可以实现多次复制,确保数据总是可以访问,哪怕硬件坏了也可以正常访问
- 全局同一的命名空间,所有节点都在一个分支管理之下,客户端访问分支节点即可
- 弹性卷,类似LVM,不同硬盘上的不同分区组成一个逻辑上的硬盘
不同服务器上的不同硬盘分区,组成一个卷,可以动态的扩容
- 基于标准协议,GFS存储服务支持,NFS HTTP 以及自身的GFS协议。应用程序可以直接使用数据,不需要做任何修改
GFS的组件和术语:
- 存储机制,BRICK(存储块,)存储服务器提供的用于物理存储的专用分区,GFS当中的基本存储单元,也是对外提供的存储目录
格式:服务器和目录的绝对路径组成的
Server:dir
20.0.0.51:/opt/gfs
Node1:/opt/gfs
- volume逻辑卷 一个逻辑卷就是一组brick的集合,类似于lvm,我们管理GFS,就是管理这些卷
- FUSE:GFS的内核模块,允许用户创建自己的文件系统
- VFS:内核空间对用户提供的访问磁盘的接口,虚拟端口
- 服务端在每个存储节点上都要运行 glustred(后台管理进程)
GFS的工作流程:
GFS的卷有哪些类型:
分布式卷:也就是GFS的默认卷类型
条带卷:(已经没了)
复制卷:(镜像化)
分布式复制卷
分布式卷的特点:文件数据通过HASH算法分布到设置的所有brick server上,GFS的默认卷。属于raid0,没有容错机制,没有冗余功能,在分布式模式下,没有对文件进行分块,直接存储在某个server的节点上,存取的效率,也没有提高,直接使用本地文件系统进行存储

复制卷:类似于raid1 文件会同步在多个brick server上,读性能上升,写性能稍差,具备冗余功能,坏一个节点不影响数据,磁盘利用率50%
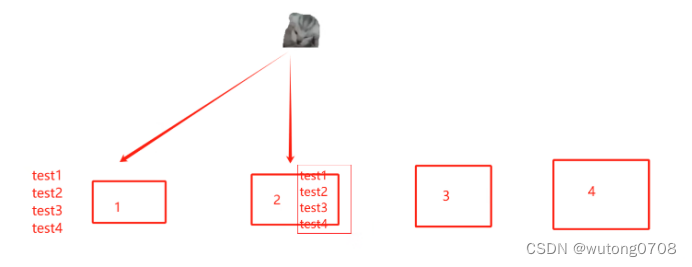
分布式复制卷:两两复制,文件会在组内同步,不同的组之间数据未必同步

实验部分
环境:
四台服务器
Node1 20.0.0.51
磁盘 /de v/sdb1 /data/sdb1
/de v/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
Node2 20.0.0.52
磁盘 /de v/sdb1 /data/sdb1
/de v/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
Node3 20.0.0.53
磁盘 /de v/sdb1 /data/sdb1
/de v/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
Node4 20.0.0.54
磁盘 /de v/sdb1 /data/sdb1
/de v/sdc1 /data/sdc1
/dev/sdd1 /data/sdd1
客户端:20.0.0.55
写一个创建磁盘分区的脚本四台服务器都要
Vim fdisk.sh

#!/bin/bash
NEWDEV=`ls /dev/sd* | grep -o 'sd[b-z]' | uniq`
for VAR in $NEWDEV
do
echo -e "n\np\n\n\n\nw\n" | fdisk /dev/$VAR &> /dev/null
mkfs.xfs /dev/${VAR}"1" &> /dev/null
mkdir -p /data/${VAR}"1" &> /dev/null
echo "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0" >> /etc/fstab
done
mount -a &> /dev/null
回到虚拟机添加硬盘

四台都要运行脚本,挂载,格式化

四台主机名分别改为node1 node2 node3 node4
hostnamectl set-hostname node1

四台都要映射
vim /etc/hosts
20.0.0.51 node1
20.0.0.52 node2
20.0.0.53 node3
20.0.0.54 node4

四台全部安装
yum -y install centos-release-gluster
先安装官网源

清一下缓存,建立元数据
yum clean all && yum makecache
安装服务(注意,安装这个服务的时候,若安装不起来,在etc/yum.repo.d/中创建一个目录,把所有的东西放进去,除了glusterfs )
yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
查看服务
gluster volume info fenbufuzhi
重启
systemctl start glusterd.service
systemctl enable glusterd.service
systemctl status glusterd.service
全部同时查看版本glusterd -v

添加节点服务器,形成一个存储信任池(一台主机即可)
gluster peer probe node1

全部查看状态
gluster peer status

创建分布式
gluster volume create fenbushi node1:/data/sdb1 node2:/data/sb1 force

gluster volume create 创建新卷,默认就是分布式卷
fenbushi 卷名,唯一不可重复
node1:/data/sdb1 node2:/data/sb1 挂载点
force 强制的意思
分布式卷 brick
fenbushi node1:/data/sdb1 node2:/data/sbb1
复制卷:node2:/data/sdc1 node3:/data/sbc1
replica2
设置复制策略,2是两两复制
要小于等于存储节点,不能比存储节点多,否则失败
创建完后打开
gluster volume start fenbushi

查看分布式的详细信息
gluster volume info fenbushi

开一台客户端

安装客户端组件
yum -y install glusterfs glusterfs-fuse

修改客户端的host
vim /etc/hosts
20.0.0.51 node1
20.0.0.52 node2
20.0.0.53 node3
20.0.0.54 node4

创建分布式目录
mkdir -p /test/fenbushi

挂载
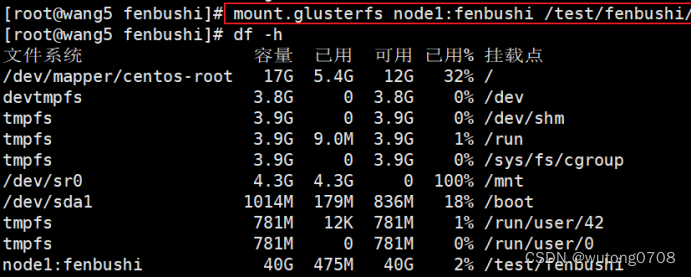
永久挂载
Vim /etc/fstab
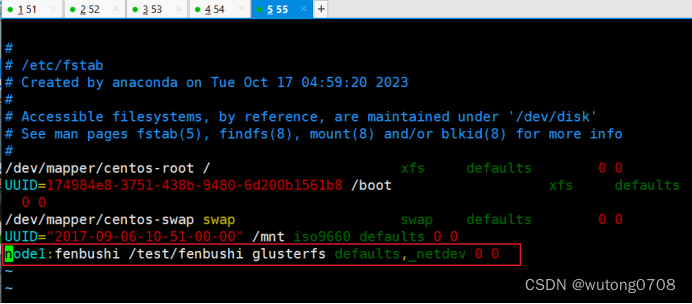

写入测试

去node节点查看
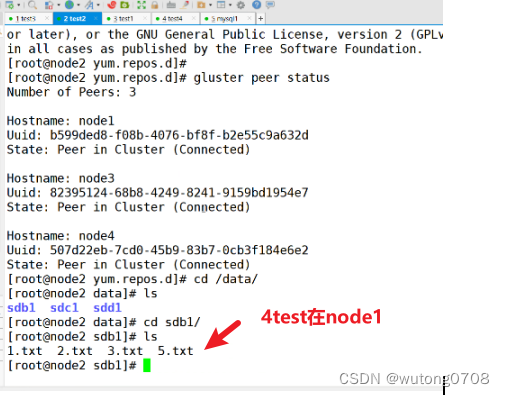
如何创建复制卷
gluster volume create fuzhijuan replica 2 node2:/data/sdc1 node3:/data/sdc1 force

打开复制卷
gluster volume start fuzhijuan

查看信息详细信息
gluster volume info fuzhijuan

客户端


节点服务器查看
创建分布式复制卷
Node1 /data/sdd1
Node2 /data/sdd1
Node3 /data/sdd1
Node4 /data/sdd1
节点服务器
gluster volume create fubufuzhi replica 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force

开启
gluster volume start fenbufuzhi

查看分布式复制详细信息
gluster volume info fenbufuzhi

客户端
mkdir fenbufuzhi
mount.glusterfs node1:fenbufuzhi/ /test/fenbufuzhi/
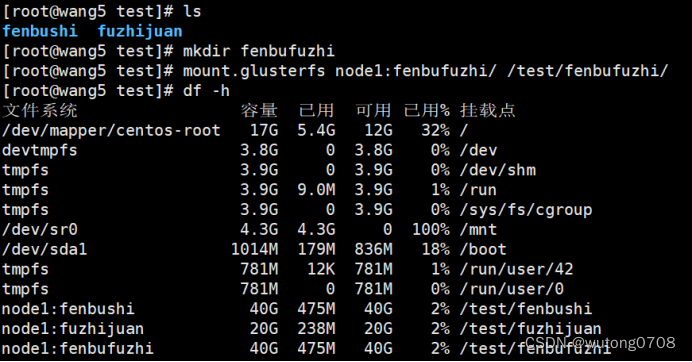

节点服务器查看
结论,四个节点服务器,随机两两复制
总结分布式复制卷:
分布式复制卷是最常用的分布文件存储方式,根据策略,存储文件还是分布式的存储方式,分开存储,但是会进行复制,所以也拥有冗余的功能,但是磁盘的利用率只有50%
查看所有节点的状态
gluster volume status

如何删除一个卷
先停节点服务器,再删除
gluster volume stop fubufuzhi

gluster volume delete fubufuzhi

客户端访问GFS卷,是通过挂载的方式实现。
GFS分布式存储系统:
- 分布式卷
- 分布式复制卷(重点)
- 工作性质,raid区分,磁盘冗余整列,本机的磁盘的冗余
GFS是把多个不同服务器上的不同硬盘组合起来,形成一个卷(基于网络的虚拟磁盘)
如何允许网段访问:

-
相关阅读:
怎么快速制作书单视频?书单视频如何制作?
类和对象(2)
这款开源神器,让聚类算法从此变得简单易用
数据结构-自学-自用
【C语言 |预处理指令】预处理指令详解(包括编译与链接)
JDBC调用存储过程
人穷志不短,穷学生也能玩转树莓派
[python][flask] Flask 入门(以一个博客后台为例)
jvm组成及内存模型
Spring事务的传播行为
- 原文地址:https://blog.csdn.net/wutong0824/article/details/134472772