-
flink中配置Rockdb的重要配置项
背景
由于我们在flink中使用了状态比较大,无法完全把状态数据存放到tm的堆内存中,所以我们选择了把状态存放到rockdb上,也就是使用rockdb作为状态后端存储,本文就是简单记录下使用rockdb状态后端存储的几个重要的配置项
使用rockdb状态后端
1.首先看一下rockdb的设计图
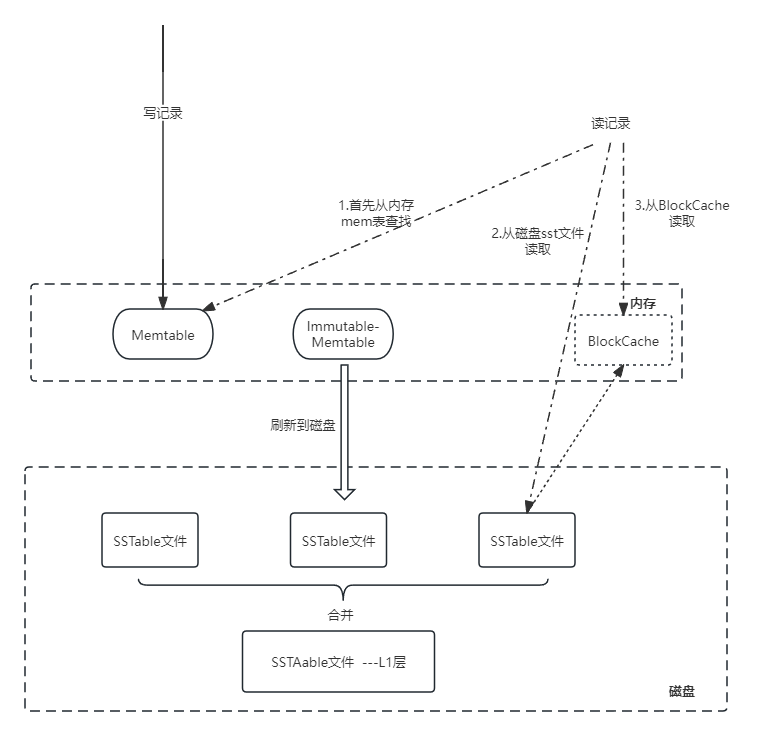
从中需要注意几点:
1.1 每次状态读取操作不一定会经过磁盘,有可能直接从内存中就可以获取到记录了,也有可能要经过好几次IO操作才能读取到记录
1.2 每次写操作都会把记录先顺序写到WAL日志文件中,然后写入memtable内存表,由于写操作是顺序写,虽然比不上直接操作内存,但是性能也不会很差
2.flink全局维度的重要的配置项:
state.backend.rocksdb.memory.managed 默认值true,开启rockdb作为flink状态后端存储
taskmanager.memory.managed.size 默认不配置,显示给rockdb用的堆外内存的总大小
taskmanager.memory.managed.fraction 默认0.4,当参数taskmanager.memory.managed.size没有配置时,给rockdb用的堆外内存的总大小占堆大小的比例3.rockdb内部的重要的配置项
我们知道rockdb中内部的内存占用主要包含:memtable表,索引(包括数据索引和布隆过滤器索引),以及BlockCache,以下两个配置是调整rockdb内部的内存占用比例的
state.backend.rocksdb.memory.write-buffer-ratio,默认值 0.5,即 50% 的给定内存会分配给写缓冲区使用,这里也就是memtable使用的内存
state.backend.rocksdb.memory.high-prio-pool-ratio,默认值 0.1,即 10% 的 block cache 内存会优先分配给索引及过滤器。 我们强烈建议不要将此值设置为零,以防止索引和过滤器被频繁踢出缓存而导致性能问题 -
相关阅读:
【小程序项目开发 -- 京东商城】uni-app 商品分类页面(下)
论文阅读_广义加性模型_GAMs
http https http2 http3
springboot+java+vue大学生求职招聘就业岗位匹配推荐系统
Flask 入门
淘宝天猫开放平台店铺商品发布(新)-淘宝店铺发布API接口流程代码对接说明
Java深拷贝与浅拷贝技术解析及实例演示
Transformer英语-法语机器翻译实例
函数基础
Java-GUI-AWT-组件-TextComponent类
- 原文地址:https://blog.csdn.net/lixia0417mul2/article/details/134471094