-
7天入门python系列之爬取热门小说项目实战,互联网的东西怎么算白嫖呢
第七天 Python项目实操
编者打算开一个python 初学主题的系列文章,用于指导想要学习python的同学。关于文章有任何疑问都可以私信作者。对于初学者想在7天内入门Python,这是一个紧凑的学习计划。但并不是不可完成的。
学到第7天说明你已经对python有了一个基本的认识,下面通过完成一个小项目来巩固之前几天所学的知识。
接下来我们上干货, 编者是一个网文读者,常常因为小说需要订阅或者有时候网路不好,看不到小说,因此选择将小说下载下来,保证能过随时随地的阅读。看看这个小项目的效果

接下来你需要熟悉几个词语,网页开发,flask 框架,request 、BeautifulSoup库,
源代码我放在**源代码地址**-
网页开发:
- 定义: 网页开发是指创建和维护网页的过程。它涵盖了从设计、编写前端代码(HTML、CSS、JavaScript)到后端开发(服务器端代码、数据库交互)以及整个网站的部署和维护等一系列工作。网页开发旨在创造用户友好的、功能完善的网站和Web应用。
-
Flask 框架:
- 定义: Flask 是一个基于 Python 的轻量级 Web 框架,用于构建 Web 应用程序。它提供了一些核心工具,如路由、视图函数、模板引擎等,使得开发者能够以简洁而灵活的方式构建 Web 应用。Flask 是一个微框架,它提供了一些基础的功能,但让开发者有更大的自由度选择其他库来满足特定需求。
-
requests 库:
- 定义:
requests是一个用于发送 HTTP 请求的 Python 第三方库。它提供了简单而强大的 API,用于处理各种类型的请求和响应,如 GET、POST 等。requests库使得在 Python 中进行网络请求变得更加方便,可以用于从 Web 服务器获取数据、与 API 交互等场景。
- 定义:
-
BeautifulSoup 库:
- 定义:
BeautifulSoup是一个 Python 库,用于从 HTML 或 XML 文档中提取数据。它提供了一种方便的方式来搜索文档树、遍历文档树中的元素,以及修改文档树。在网页开发中,BeautifulSoup主要用于解析 HTML 页面,从中提取结构化的信息,例如抓取特定标签的内容、提取链接、或者进行数据挖掘。
- 定义:
在网页开发中,通常会使用 Flask 框架来构建 Web 应用的后端,同时使用
requests库来进行与其他服务器的通信,获取数据。而在处理获取到的 HTML 页面时,可以借助BeautifulSoup库进行解析和信息提取。这三者的结合使得开发者能够更轻松地构建和处理 Web 应用。
代码我放在gitee 仓库:https://gitee.com/constantine-G/getbook项目搭建
然后开始我们的项目搭建:
使用pycharm 编辑器, 创建项目

新建好的干净项目
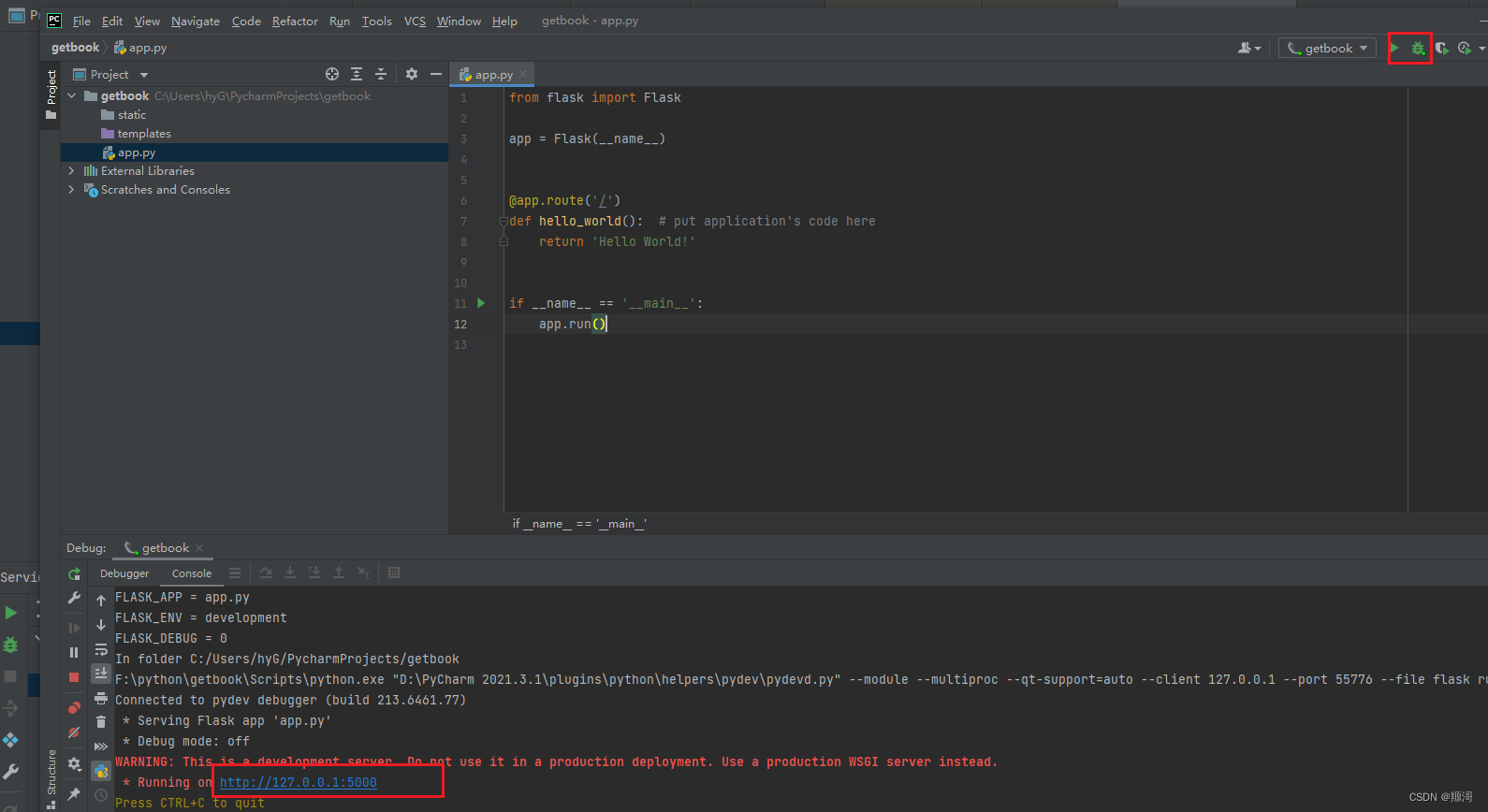
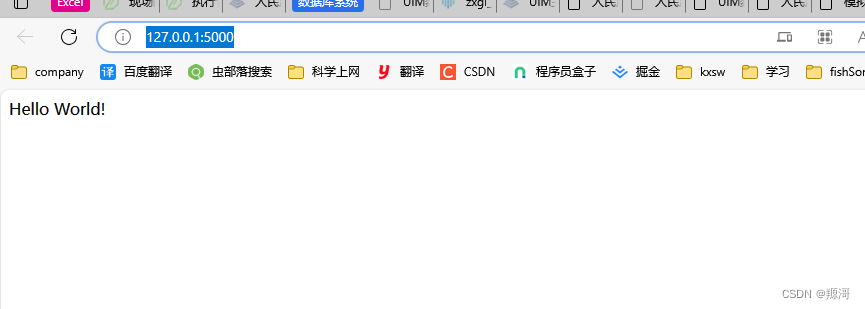
 > 此时你可以启动这个项目,会返回一句话
> 此时你可以启动这个项目,会返回一句话
创建交互页面
创建这样两个文件

网络下载这个文件,如果找不到,直接到我的仓库下载
index.html 内容
DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>hello,my world!title> head> <body> <div id="app"> <input id="bookName">输入书籍、作者名称input> <button id="swap">确认button> <ul id="data-list">ul> <input id="bdbookName">本地书籍input> <button id="search">搜索button> <ul id="bd-list">ul> div> {# <script src="/static/js/common/vue/vue.js">script>#} {# <script type="text/javascript" src="/static/js/common/require/require.min.js">script>#} <script src="/static/js/common/jquery.js">script> <script src="/static/js/index.js">script> body> html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
iondex,js 内容
const person = document.getElementById('bookName'); const bdbookName = document.getElementById('bdbookName'); $(document).ready(function () { $("#swap").click(function () { $.ajax({ type: "POST", url: "/searchBook", dataType: "json", data: {"bookName": person.value}, success: function (res) { displayData(res); // addListener(); }, error: function (xhr, status, error) { alert(error); } }); }); $("#search").click(function () { $.ajax({ type: "POST", url: "/searchBd", dataType: "json", data: {"bookName": bdbookName.value}, success: function (res) { dbdisplayData(res); // addListener(); }, error: function (xhr, status, error) { alert(error); } }); }); // }); function addListener(){ // 获取列表项元素 const listItems = document.querySelectorAll('#data-list li'); // 为每个列表项添加点击事件 listItems.forEach(item => { item.addEventListener('click', () => { downLoadBook(item) }); }); } function addListener(){ // 获取列表项元素 const listItems = document.querySelectorAll('#bd-list li'); // 为每个列表项添加点击事件 listItems.forEach(item => { item.addEventListener('click', () => { downLoadBook(item) }); }); } function downLoadBook(event) { $.ajax({ type: "POST", url: "/downLoadBook", dataType: "json", data: {"book": data}, success: function (res) { alert(res); }, error: function (xhr, status, error) { alert(error); } }); } function dbdisplayData(data) { var dataList = $("#bd-list"); dataList.empty(); data.forEach(function (item) { // Edit // var url = "/downLoadBook" + item.link; var url = "/downLoadBook" + item.bookLink; dataList.append("- "
+ item.bookName + "+url+"\"> 下载 "+"地址: "+item.path+""); // dataList.append("- " + item.bookName + "
"); }); } function displayData(data) { var dataList = $("#data-list"); dataList.empty(); data.forEach(function (item) { // Edit var url = "/downLoadBook" + item.link; dataList.append("- "
+ item.name + "+url+"\">下载"+""); }); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
在app.py 文件中添加一个方法
@app.route('/') def hello_world(): # put application's code here return render_template("index.html")- 1
- 2
- 3
- 4
此时再次重启项目,并访问 http://127.0.0.1:5000/
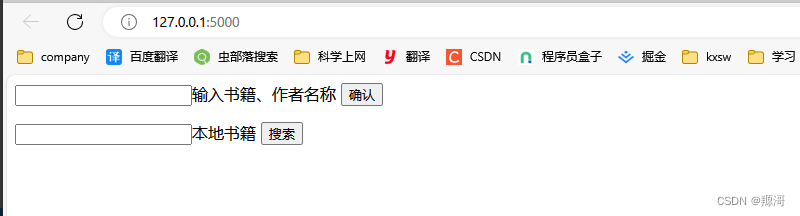
可以看到已经多了一些内容。这是用于一个简单交互的页面。主要是输入想要下载的书籍,发起查询,然后在下载完成时的效果:

网站后端查询小说
新增一个文件叫book.py
并新增以下内容 :主要是点击查询的功能实现
def searchBooklist(bookName): try: # 发送GET请求 = "http://www.biqu5200.net" response = requests.get(url== "http://www.biqu5200.net" + "/modules/article/search.php?searchkey=" + bookName, headers=header) response.encoding = 'utf-8' # 检查请求是否成功 res = [] bookList = [] if response.status_code == 200: # 如果请求成功,获取响应数据 soup = BeautifulSoup(response.content, "html.parser") even_items = soup.find_all("tr") # 遍历并打印匹配的元素内容 for item in even_items: booklink = item.find("a") if booklink != None and booklink["href"] != None and booklink.text != None: book = { "name": booklink.text, "link": booklink["href"] } bookO = { "name": booklink.text, "link": url+booklink["href"] } res.append(book) # book = select(booklink.text) if book == None: bookList.append(bookO) # insert(bookList) return res else: # 如果请求失败,打印错误信息 print("请求失败,状态码:", response.status_code) return res except requests.exceptions.RequestException as e: # 处理请求异常 print("请求异常:", e) return res- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
这个方法是返回一个书籍的列表

接下来实现下载功能
def downLoadBook(bookLink): # 发送GET请求 # response = requests.get(url=book["link"], headers=header) # 请求数据 response = getRequsetContent(url+"/"+bookLink) if response != None: # 如果请求成功,获取响应数据 soup = BeautifulSoup(response, "html.parser") even_items = soup.find_all("dd") bookName = soup.find(id='info').find('h1').text start = time.time() min = len(even_items) / (60/second) hour = min / 60 print("预估时间:" + str(min) +"分钟" + "= "+str(hour)+"小时") # 遍历并打印匹配的元素内容 # open(bookName+".txt", mode="r") # 读文件 # open("demo1/1.txt", mode="w") # 写文件 file = open(bookName + ".txt", mode="w",encoding='utf-8') file = open(bookName + ".txt", mode="a",encoding='utf-8') # 追加 ret_message = {"code": 0, "status": "successful", "msg": "成功,耗时:" + str(min)} failed = [] # book = select(bookName) try: chapterList = [] for item in even_items: booklink = item.find("a") chapter = { "bookid": book["id"], "chapterLink": url+ booklink["href"], "chapterName": booklink.text } chapterList.append(chapter) # insertChapter(chapterList) leastchaper = '' for item in even_items: booklink = item.find("a") contemxUrl =booklink["href"] chaper = booklink.text leastchaper = chaper chaperurl = url + contemxUrl # 休息1秒 time.sleep(second) content = getRequsetContent(chaperurl) contentList = [] if content != None: soup = BeautifulSoup(content, "html.parser") chapername = soup.find(class_="bookname").find("h1").text contentList.append(chapername + '\n') pList = soup.find(id="content").find_all("p") contentList = [] for p in pList: constr = p.text if constr.find("请记住本书首发域名:。顶点小说手机版阅读网址:") != -1: print("有广告:" + constr) contentList.append(p.text + '\n') else: failed.append(chaper) file.writelines(contentList) # update(chaper,url+ booklink["href"]) print("完成:"+chaper) upBook = Book(book['id'],1,os.path.abspath(os.path.dirname(file.__str__())).replace('\\','/'),leastchaper,';'.join(failed)) # updateBook(upBook) print("failed:" + ''.join(failed)) size =file.seek(0, os.SEEK_END) end = time.time() print("size:" + ''.join(size)) print("time:" + end - start) file.close() return ret_message except Exception as e: # 处理请求异常 file.close() print("异常:", e) return ret_message else: # 如果请求失败,打印错误信息 print("请求失败,状态码:", response.status_code) # 公用方法 def getRequsetContent(url): try: # 发送GET请求 response = requests.get(url=url, headers=header) response.encoding = 'utf-8' # 检查请求是否成功 if response.status_code == 200: # 如果请求成功,获取响应数据 return response.content else: # 如果请求失败,打印错误信息 print("请求失败,状态码:", response.status_code) return None except requests.exceptions.RequestException as e: # 处理请求异常 print("请求异常:", e) return None- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
到此我们的功能就基本完成了。实现了查询数据,并选择自己想要的书籍下载,有任何疑问请联系我
-
-
相关阅读:
如何CMAKE那些在GIT上的项目并运行起来
【音视频 | opus】opus编码的Ogg封装文件详解
python+pytest接口自动化(13)-token关联登录
TCP/IP网络协议详解
【函数式接口使用✈️✈️】配合策略模式实现文件处理的案例
day15--使用postman, newman和jenkins进行接口自动化测试
21天学习挑战赛--第二天打卡(setSystemUiVisibility、导航栏、状态栏)
PTA古风排版
使用Unity和纯ECS框架重新打造简单RTS游戏:从零开始的详细C#编程教程
制作ubuntu18.04 cuda10.2+ROS1的 docker镜像
- 原文地址:https://blog.csdn.net/qq_43406318/article/details/134422105
