-
【Hadoop实战】Hadoop指标系统V2分析
Hadoop指标系统V2分析
架构
在Hadoop中基于JMX开发了Metrics2版本的指标系统。
源码包:
org.apache.hadoop.metrics2预备知识JMX。官方学习地址
主要组成部分
- metrics sources:生产和更新指标的地方,提供了一个
getMetris接口,用来获取指标值。 - metrics sinks:汇集指标记录
- metricsSystem:指标系统会定期轮询指标源,将指标记录汇集给指标sink。提供了一个
putMetrics接口,用来接受指标记录。
类图
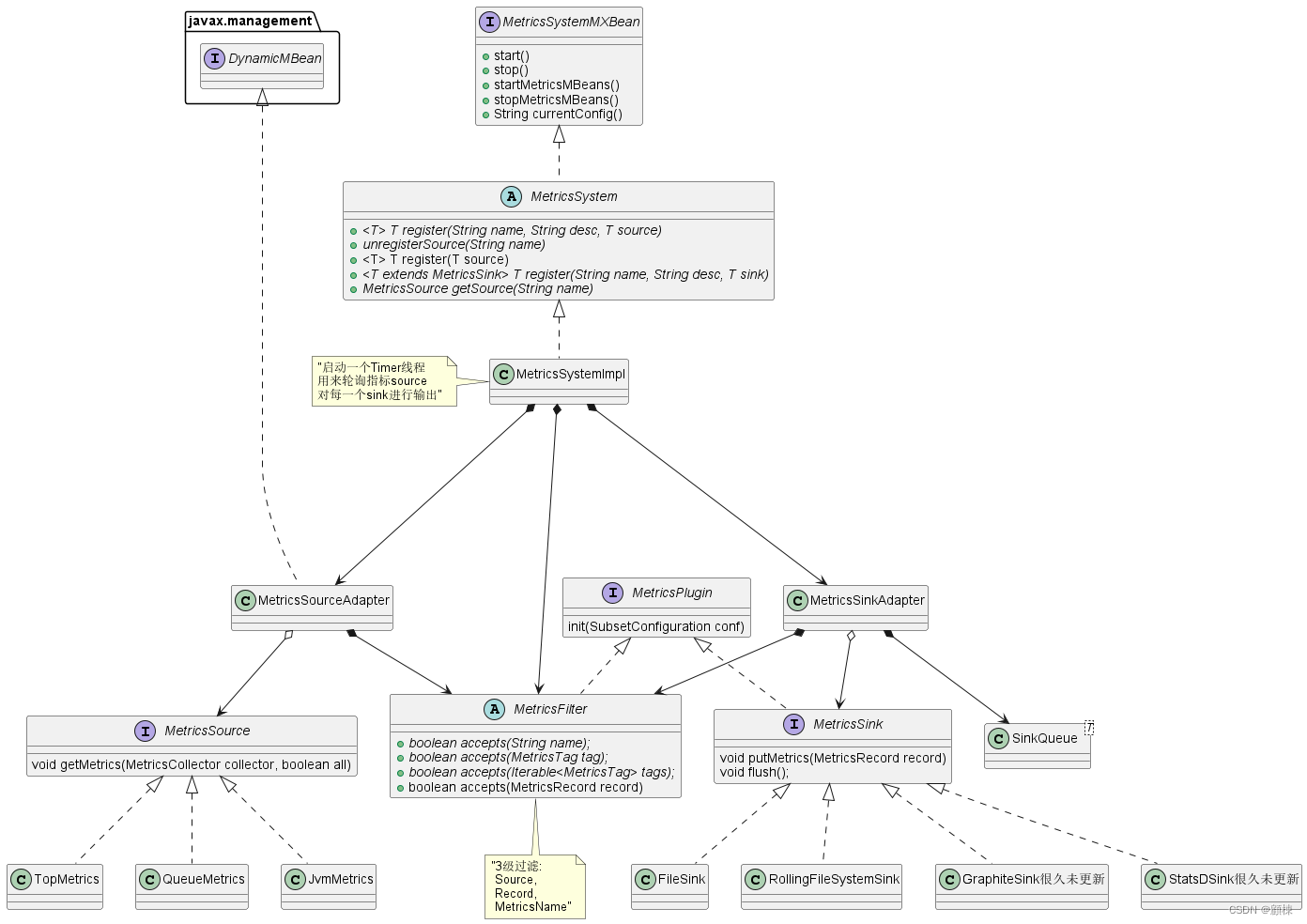
UML代码作图工具
根据图表解释数据流向
指标数据的流向,由MetricsSystemImpl中的定时线程timer驱动,去调用每个MetricsSource适配器的getMetrics方法来采集每个指标源中的指标值,将指标数据写入对应的MetricsSink适配器中的SinkQueue队列中(半阻塞队列(生产者为非阻塞队列,消费者为阻塞队列),
当队列满时,新元素会被丢弃,以便在队列填充事件开始时保留 "有趣 "的元素。)。同时在每个MetricsSink适配器中都有一个sinkThread线程,用来消费SinkQueue队列中的指标数据,构造指标记录存储,存入对应的介质中。指标过滤
支持三个级别的指标过滤,指标源级别,指标记录,指标名称。过滤的成本(内存和CPU)按下方列表顺序增加,
- 全局源名称过滤:在调用
getMetrics时,跳过任何名称匹配的指标源。 - 每个指标槽名称过滤:在调用
putMetrics时,跳过任何名称匹配的指标槽。 - 每个指标源的记录过滤:
getMetrics调用中的MetricsRecordImpl.getRecord()调用将跳过任何名称或标记值匹配的记录。 - 每个指标槽的记录过滤:在
putMetrics调用中跳过任何名称或标签值匹配的记录。 - 每个源的指标名称过滤:
getMetrics调用中的MetricsRecordBuilderImpl.add*()调用将跳过名称匹配的任何度量。 - 每个槽的指标名称过滤:在
putMetrics调用中迭代MetricsRecord时,跳过任何名称匹配的度量。
JMX的应用
MetricsSystemMXBean实现JMX MBean接口,以允许现有的JMX客户端(JConsole、jManage等)在运行时停止和启动指标系统或指标源。将实现JMX MBean接口,以允许现有的JMX客户端(JConsole、jManage等)在运行时停止和启动度量系统。
使用场景:
-
基于
MXBean的MetricsSystemImpl,主要是为了支持CompositeData类型的数据 -
基于
DynamicMBean的MetricsSourceAdapter,主要是为了重写getAttribute(String attribute),getAttributes(String[] attributes)和getMBeanInfo()方法。 -
基于
StandardMBean的org.apache.hadoop.yarn.server.resourcemanager.RMNMInfo。从设计上看,这个简单的实现,没必要使用DynamicMBean那种复杂的实现。
JDK自带的MXBeans在包
java .lang.management中,JVM指标使用到。开启指标系统的组件
2.10.2版本可以开启指标系统的组件角色列表。即为指标命名中的服务名称。
-
WebAppProxyServer
-
SharedCacheManager
-
NodeManager
-
ApplicationHistoryServer
-
JobHistoryServer
-
MRAppMaster
-
SecondaryNameNode
-
DataNode
-
JournalNode
-
Router
-
NameNode
-
ResourceManager
指标系统启动的入口:
DefaultMetricsSystem.initialize("服务名称"),如DefaultMetricsSystem.initialize("ResourceManager");指标项说明
指标分类列表:
- JvmMetrics
- rpc
- RetryCache/NameNodeRetryCache
- FairCallQueue
- rpcdetailed
- namenode
- FSNamesystem
- JournalNode
- datanode
- FsVolume
- RouterRPCMetrics
- StateStoreMetrics
- ClusterMetrics
- QueueMetrics
- NodeManagerMetrics
- ContainerMetrics
- UgiMetrics
- MetricsSystem
- StartupProgress
使用HTTP(JMXJsonServlet)获取指标
接口
接口类
org.apache.hadoop.jmxJMXJsonServlet接口地址:
- `http://节点域名:webapp服务的port/jmx``
- ``http://节点域名:webapp服务的port/jmx?get=Hadoop:service=ResourceManager,name=RMNMInfo`
调用方式GET
查询的逻辑
- 创建MBean服务器。
- 查询MBean服务器中注册的所有Mbean(指标信息)。
- 根据条件过滤指标源Bean下的所有attribute信息,不传入条件默认查询全部指标源beans。
- 组织成json返回值。
数据的来源,以及更新的原理
对应发现的三类JMX MBeans。
RMNMInfo,去获取所有节点汇报的健康信息,在调用MBean的成员方法时,才回去查询最新的节点数据。MetricsSourceAdapter,这类的动态MBeans在实现的时候,重写了获取属性的方法,都会去调用updateJmxCache()方法,继而调用updateAttrCache和updateInfoCache方法,将最新的指标信息构造成Bean的Attribute更新进JMX缓存中,从而返回最新的指标属性值。MetricsSystemImpl,其中的指标需要在开启指标系统且拥有sink的情况下数据才会进行更新,主要的原因其更新指标的方法sampleMetrics(),依赖于调度线程调度的onTimerEvent()和即时发布指标方法publishMetricsNow()。这两个方法均要求sinks.size() > 0才会指标采样更新。
- metrics sources:生产和更新指标的地方,提供了一个
-
相关阅读:
【MAX7800实现KWS20 demo演示】
172基于matlab的MPPT智能算法
数据治理-数据仓库和商务智能
安装Zookeeper和Kafka集群
Containerd容器运行时的Kubernetes(K8s)环境搭建
Redis 学习笔记2
【LeetCode】最长有效括号 [H](动态规划)
nlp中如何数据增强
【Leetcode】1027. Longest Arithmetic Subsequence
.NET使用CsvHelper快速读取和写入CSV文件
- 原文地址:https://blog.csdn.net/weixin_43820556/article/details/134329339