-
HuggingFace的transfomers库
pipeline
- from transformers import pipeline
- classifier = pipeline("sentiment-analysis")#自动下载模型和tokenizer
- classifier("We are very happy to show you the 🤗 Transformers library.")#[{'label': 'POSITIVE', 'score': 0.9998}]
- #输入多句
- results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
- for result in results:
- print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
- #可以指定模型
- import torch
- from transformers import pipeline
- from datasets import load_dataset, Audio
- speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
- dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
- dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
- result = speech_recognizer(dataset[:4]["audio"])
- print([d["text"] for d in result])
- #指定device
- transcriber = pipeline(model="openai/whisper-large-v2", device=0)
- #自动分配device
- #pip install --upgrade accelerate
- transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")
- #batch推理
- transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
- audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
- texts = transcriber(audio_filenames)
- #其他参数示例
- # pip install accelerate
- import torch
- from transformers import pipeline
- pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
- output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
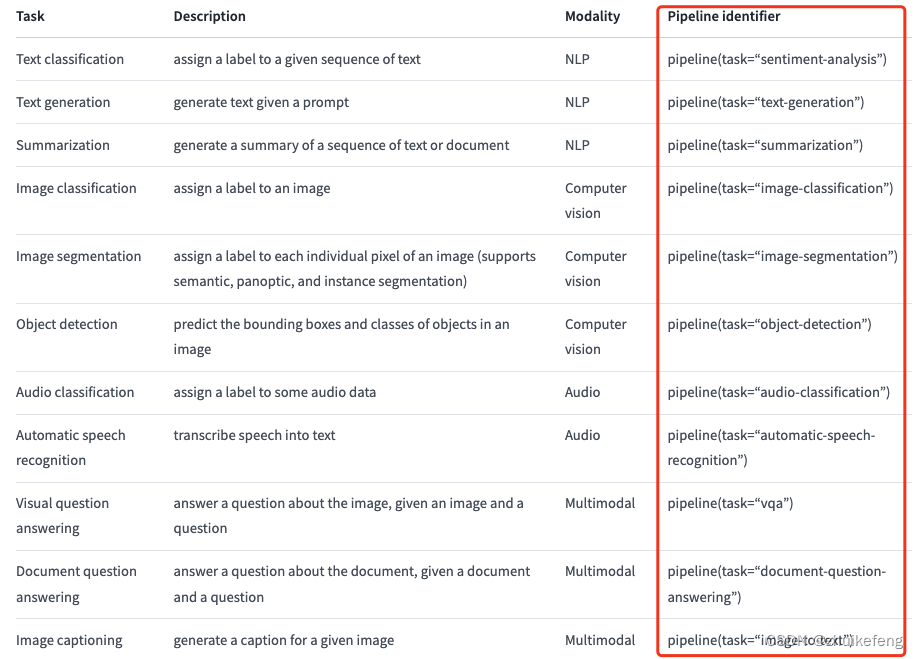
下面是更多类型,完整列表
AutoClass
AutoTokenizer
- from transformers import AutoTokenizer
- model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
- print(encoding)
- #指定返回pytorch tensor
- pt_batch = tokenizer(
- ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
- padding=True,
- truncation=True,
- max_length=512,
- return_tensors="pt",#如果是tf_tensor则写tf
- )
AutoModel
- from transformers import AutoModelForSequenceClassification
- model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
- pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
- pt_outputs = pt_model(**pt_batch)
- #输出只有概率,后处理要自己做
- from torch import nn
- pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
- print(pt_predictions)
- #保存模型
- pt_save_directory = "./pt_save_pretrained"
- tokenizer.save_pretrained(pt_save_directory)
- pt_model.save_pretrained(pt_save_directory)
- pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
- #torch加载tf保存的模型
- from transformers import AutoModel
- tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
- pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
AutoConfig
- from transformers import AutoConfig
- # Download configuration from huggingface.co and cache.
- config = AutoConfig.from_pretrained("bert-base-uncased")
- # Download configuration from huggingface.co (user-uploaded) and cache.
- config = AutoConfig.from_pretrained("dbmdz/bert-base-german-cased")
- # If configuration file is in a directory (e.g., was saved using *save_pretrained('./test/saved_model/')*).
- config = AutoConfig.from_pretrained("./test/bert_saved_model/")
- # Load a specific configuration file.
- config = AutoConfig.from_pretrained("./test/bert_saved_model/my_configuration.json")
- # Change some config attributes when loading a pretrained config.
- config = AutoConfig.from_pretrained("bert-base-uncased", output_attentions=True, foo=False)
- config.output_attentions
- config, unused_kwargs = AutoConfig.from_pretrained(
- "bert-base-uncased", output_attentions=True, foo=False, return_unused_kwargs=True
- )
- from transformers import AutoModel
- my_model = AutoModel.from_config(config)
Trainer
- from transformers import AutoModelForSequenceClassification
- from transformers import TrainingArguments
- from transformers import AutoTokenizer
- from datasets import load_dataset
- from transformers import DataCollatorWithPadding
- from transformers import Trainer
- model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
- training_args = TrainingArguments(
- output_dir="path/to/save/folder/",
- learning_rate=2e-5,
- per_device_train_batch_size=8,
- per_device_eval_batch_size=8,
- num_train_epochs=2,
- )
- tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
- dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
- def tokenize_dataset(dataset):
- return tokenizer(dataset["text"])
- dataset = dataset.map(tokenize_dataset, batched=True)
- data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
- trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=dataset["train"],
- eval_dataset=dataset["test"],
- tokenizer=tokenizer,
- data_collator=data_collator,
- ) # doctest: +SKIP
- trainer.train()
安装
- pip install transformers
- pip install 'transformers[torch]'#只安装torch后端
- #源码安装
- pip install git+https://github.com/huggingface/transformers
- #开发者模式
- git clone https://github.com/huggingface/transformers.git
- cd transformers
- pip install -e .
tokenizer
我获取了opt类型的tokenizer,那么enc是什么类型呢?有哪些方法呢?
- from transformers import AutoTokenizer
- enc = AutoTokenizer.from_pretrained('facebook/opt-125m')
可以通过print(enc)看到,enc是GPT2TokenizerFast类型,搜索类型的定义,在python安装包的transformers/models/gpt2/tokenization_gpt2_fast.py
- class GPT2TokenizerFast(PreTrainedTokenizerFast):
- vocab_files_names = VOCAB_FILES_NAMES
- pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
- max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
- model_input_names = ["input_ids", "attention_mask"]
- slow_tokenizer_class = GPT2Tokenizer
- def __init__(
- self,
- vocab_file=None,
- merges_file=None,
- tokenizer_file=None,
- unk_token="<|endoftext|>",
- bos_token="<|endoftext|>",
- eos_token="<|endoftext|>",
- add_prefix_space=False,
- **kwargs,
- ):
- super().__init__(
- vocab_file,
- merges_file,
- tokenizer_file=tokenizer_file,
- unk_token=unk_token,
- bos_token=bos_token,
- eos_token=eos_token,
- add_prefix_space=add_prefix_space,
- **kwargs,
- )
- def _batch_encode_plus(self, *args, **kwargs) -> BatchEncoding:
- def _encode_plus(self, *args, **kwargs) -> BatchEncoding:
- def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
- class PreTrainedTokenizerFast(PreTrainedTokenizerBase):
- vocab_files_names = VOCAB_FILES_NAMES
- slow_tokenizer_class: PreTrainedTokenizer = None
- def __init__(self, *args, **kwargs):
- tokenizer_object = kwargs.pop("tokenizer_object", None)
- slow_tokenizer = kwargs.pop("__slow_tokenizer", None)
- fast_tokenizer_file = kwargs.pop("tokenizer_file", None)
- from_slow = kwargs.pop("from_slow", False)
- added_tokens_decoder = kwargs.pop("added_tokens_decoder", {})
- @property#属性装饰器的作用在于将成员函数变成成员变量,访问的时候不需要/不能加()
- def is_fast(self) -> bool:
- @property
- def can_save_slow_tokenizer(self) -> bool:
- @property
- def vocab_size(self) -> int:
- def get_vocab(self) -> Dict[str, int]:
- @property
- def vocab(self) -> Dict[str, int]:
- @property
- def added_tokens_encoder(self) -> Dict[str, int]:
- @property
- def added_tokens_decoder(self) -> Dict[int, AddedToken]:
- def get_added_vocab(self) -> Dict[str, int]:
- def __len__(self) -> int:
- @property
- def backend_tokenizer(self) -> TokenizerFast:
- @property
- def decoder(self) -> DecoderFast:
- def _convert_encoding(
- self,
- encoding: EncodingFast,
- return_token_type_ids: Optional[bool] = None,
- return_attention_mask: Optional[bool] = None,
- return_overflowing_tokens: bool = False,
- return_special_tokens_mask: bool = False,
- return_offsets_mapping: bool = False,
- return_length: bool = False,
- verbose: bool = True,
- ) -> Tuple[Dict[str, Any], List[EncodingFast]]:
- def convert_tokens_to_ids(self, tokens: Union[str, List[str]]) -> Union[int, List[int]]:
- def _convert_token_to_id_with_added_voc(self, token: str) -> int:
- def _convert_id_to_token(self, index: int) -> Optional[str]:
- def _add_tokens(self, new_tokens: List[Union[str, AddedToken]], special_tokens=False) -> int:
- def num_special_tokens_to_add(self, pair: bool = False) -> int:
- def convert_ids_to_tokens(
- self, ids: Union[int, List[int]], skip_special_tokens: bool = False
- ) -> Union[str, List[str]]:
- def tokenize(self, text: str, pair: Optional[str] = None, add_special_tokens: bool = False, **kwargs) -> List[str]:
- def set_truncation_and_padding(
- self,
- padding_strategy: PaddingStrategy,
- truncation_strategy: TruncationStrategy,
- max_length: int,
- stride: int,
- pad_to_multiple_of: Optional[int],
- ):
- def _batch_encode_plus(
- self,
- batch_text_or_text_pairs: Union[
- List[TextInput], List[TextInputPair], List[PreTokenizedInput], List[PreTokenizedInputPair]
- ],
- add_special_tokens: bool = True,
- padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
- truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
- max_length: Optional[int] = None,
- stride: int = 0,
- is_split_into_words: bool = False,
- pad_to_multiple_of: Optional[int] = None,
- return_tensors: Optional[str] = None,
- return_token_type_ids: Optional[bool] = None,
- return_attention_mask: Optional[bool] = None,
- return_overflowing_tokens: bool = False,
- return_special_tokens_mask: bool = False,
- return_offsets_mapping: bool = False,
- return_length: bool = False,
- verbose: bool = True,
- ) -> BatchEncoding:
- def _encode_plus(
- self,
- text: Union[TextInput, PreTokenizedInput],
- text_pair: Optional[Union[TextInput, PreTokenizedInput]] = None,
- add_special_tokens: bool = True,
- padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
- truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
- max_length: Optional[int] = None,
- stride: int = 0,
- is_split_into_words: bool = False,
- pad_to_multiple_of: Optional[int] = None,
- return_tensors: Optional[bool] = None,
- return_token_type_ids: Optional[bool] = None,
- return_attention_mask: Optional[bool] = None,
- return_overflowing_tokens: bool = False,
- return_special_tokens_mask: bool = False,
- return_offsets_mapping: bool = False,
- return_length: bool = False,
- verbose: bool = True,
- **kwargs,
- ) -> BatchEncoding:
- def convert_tokens_to_string(self, tokens: List[str]) -> str:
- def _decode(
- self,
- token_ids: Union[int, List[int]],
- skip_special_tokens: bool = False,
- clean_up_tokenization_spaces: bool = None,
- **kwargs,
- ) -> str:
- def _save_pretrained(
- self,
- save_directory: Union[str, os.PathLike],
- file_names: Tuple[str],
- legacy_format: Optional[bool] = None,
- filename_prefix: Optional[str] = None,
- ) -> Tuple[str]:
- def train_new_from_iterator(
- self,
- text_iterator,
- vocab_size,
- length=None,
- new_special_tokens=None,
- special_tokens_map=None,
- **kwargs,
- ):
流式输出
- from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
- tok = AutoTokenizer.from_pretrained("gpt2")
- model = AutoModelForCausalLM.from_pretrained("gpt2")
- inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
- streamer = TextStreamer(tok)
- # Despite returning the usual output, the streamer will also print the generated text to stdout.
- _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
- from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
- from threading import Thread
- tok = AutoTokenizer.from_pretrained("gpt2")
- model = AutoModelForCausalLM.from_pretrained("gpt2")
- inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
- streamer = TextIteratorStreamer(tok)
- # Run the generation in a separate thread, so that we can fetch the generated text in a non-blocking way.
- generation_kwargs = dict(inputs, streamer=streamer, max_new_tokens=20)
- thread = Thread(target=model.generate, kwargs=generation_kwargs)
- thread.start()
- generated_text = ""
- for new_text in streamer:
- generated_text += new_text
- print(generated_text)
-
相关阅读:
HTTPS - 揭秘 TLS 1.2 协议完整握手过程--此文为转发文,一定要结合wirshark工具看,很清楚
备战蓝桥杯————k个一组反转单链表
2022年这一批陕西省工程职称评审难度调整了
学习 C++ 编程,怎么才能找到合适的练手项目?
【牛客 - 剑指offer】JZ4 二维数组中的查找 Java实现
SpringMVC第六阶段:数据在域中的保存(02)
【UVM 验证平台打印时间单位控制】
AI时代 编程高手的秘密武器:世界顶级大学推荐的计算机教材
kafka面试题(基础-进阶-高阶)
BUUCTF做题Upload-Labs记录pass-11~pass-20
- 原文地址:https://blog.csdn.net/zhuikefeng/article/details/134282259
