-
音乐推荐与管理系统Python+Django网页界面+协同过滤推荐算法
一、介绍
音乐推荐与管理系统。本系统采用Python作为主要开发语言,前端使用HTML、CSS、BootStrap等技术搭建界面平台,后端使用Django框架处理请求,并基于Ajax等技术实现前端与后端的数据通信。在音乐个性推荐功能模块中采用通过Python编写协同过滤推荐算法模块,实现对当前登录用户的个性化推荐。
主要功能有:- 系统分为普通用户和管理员两个角色
- 普通用户可以登录、注册、查看音乐列表、查看音乐详情、播放音乐、收藏、发布评论、查看编辑个人信息、查看浏览量排行、查看编辑个人收集信息、音乐推荐等
- 管理员在后台管理系统中可以管理音乐和用户等所有信息
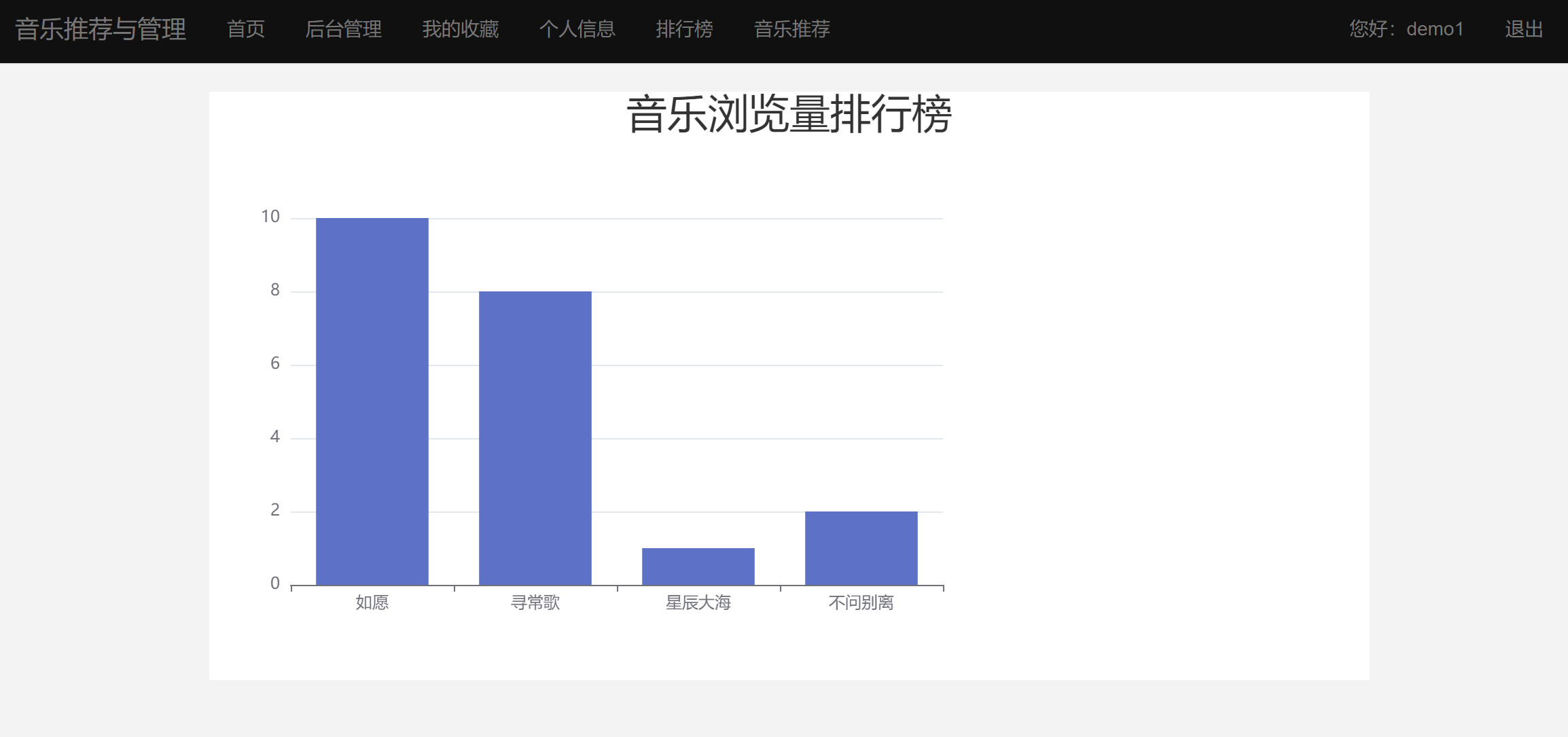
二、系统效果图片



三、演示视频 and 代码
视频+代码:https://www.yuque.com/ziwu/yygu3z/noq0cs1vn3dhbykv
四、协同过滤算法介绍
协同过滤算法是一种推荐系统算法,核心思想是根据用户历史行为数据之间的相似度来进行推荐。协同过滤算法主要分为两大类:基于用户的协同过滤和基于物品的协同过滤。
基于用户的协同过滤算法的步骤如下:- 计算用户之间的相似度。
- 找到目标用户的相似用户(邻居)。
- 结合邻居用户的评分,预测目标用户对未评分物品的评分。
- 推荐预测评分高的物品给目标用户。
在这个算法中,用户相似度的计算是关键,常见的相似度计算方法有皮尔逊相关系数(Pearson Correlation Coefficient)、余弦相似度(Cosine Similarity)和欧氏距离(Euclidean Distance)等。
下面是一个简单的基于用户的协同推荐算法功能模块的Python实现,使用了NumPy库来处理数据:import numpy as np # 用户-物品评分矩阵 # 假设有5个用户和4个物品,矩阵中的数字代表用户对物品的评分,0表示未评分 ratings = np.array([ [5, 3, 0, 1], [4, 0, 0, 1], [1, 1, 0, 5], [1, 0, 0, 4], [0, 1, 5, 4], ]) # 计算用户之间的相似度,这里使用余弦相似度 def cosine_similarity(ratings): # 确保不会除以0 epsilon = 1e-9 # 计算用户评分的模长 magnitude = np.sqrt(np.einsum('ij, ij -> i', ratings, ratings)) + epsilon # 使用外积计算余弦相似度 similarity = ratings @ ratings.T / np.outer(magnitude, magnitude) return similarity # 基于用户的协同过滤推荐 def user_based_recommendation(user_index, ratings, similarity, k=3): """ :param user_index: 需要推荐的用户索引 :param ratings: 用户-物品评分矩阵 :param similarity: 用户相似度矩阵 :param k: 邻居数量 :return: 推荐评分列表 """ # 找出用户已评分的物品索引 rated_items = np.where(ratings[user_index] > 0)[0] # 未评分的物品 unrated_items = np.where(ratings[user_index] == 0)[0] # 用于存储预测评分 pred_ratings = np.zeros(ratings.shape[1]) # 对于未评分的物品进行评分预测 for item in unrated_items: # 计算用户对物品item的评分预测 neighbors = np.argsort(similarity[user_index])[::-1][1:k+1] # 最相似的k个用户 # 计算邻居的相似度和它们对物品item的评分 numerator = similarity[user_index][neighbors].dot(ratings[neighbors, item]) denominator = np.sum(np.abs(similarity[user_index][neighbors])) pred_ratings[item] = numerator / denominator if denominator != 0 else 0 # 返回已评分的保持原样,未评分的用预测值替代 final_ratings = ratings[user_index].copy() final_ratings[unrated_items] = pred_ratings[unrated_items] return final_ratings # 计算用户相似度矩阵 user_similarity = cosine_similarity(ratings) # 为第一个用户进行推荐 recommendations = user_based_recommendation(0, ratings, user_similarity) print("推荐评分:", recommendations)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
在这个例子中,ratings矩阵代表了5个用户对4个物品的评分情况,未评分的部分用0表示。我们使用余弦相似度来计算用户之间的相似度,并且定义了user_based_recommendation函数来根据用户的相似度和已有的评分来预测目标用户对未评分物品的评分,并返回一个包含所有物品评分的列表(包括预测的评分和原来的评分)。这个列表可以用来对物品进行排序,最后推荐评分最高的物品给用户。
-
相关阅读:
STP学习的第一篇
DTC(diagnostic trouble code)
dreamweaver作业静态HTML网页设计 大学美食菜谱网页制作教程(web前端网页制作课作业)
Springboot基于web的游泳馆信息管理系统 毕业设计-附源码281444
C++之设计模式
业务中如何拓展微前端架构
[字符串和内存函数]strcpy和strncpy的区别
鲲鹏代码迁移工具介绍
C++常用23种设计模式总结(三)------装饰模式
系统架构设计师-第12章-信息系绍酣忽如何里论与实践-软考-学习笔记
- 原文地址:https://blog.csdn.net/meridian002/article/details/134217257
