-
浅谈分布式系统
分布式系统
只有一台服务器负责所有的工作称为单机架构,但是一台主机的硬件资源是有上限的,当同一时刻主机收到的请求很多,就可能导致主机的某个硬件资源不够用了,无论是哪个方面不够用都可能会导致服务器处理请求的时间变长甚至会出错。
那么遇到这种情况应该怎么处理呢?
- 对应用软件进行优化,也就是对代码进行优化
- 引入更多的硬件资源,但是由于一台主机能够扩展的硬件资源是有限的,因此这并不能应对更复杂的问题
- 引入多台主机,一旦引入了多台主机就可以称为是分布式系统
引入分布式系统是万不得已的选择,因为多台机器就会导致复杂程度会大大提高,出现bug的概率也会更高。
应用数据分离架构
将应用服务器和存储服务器分开。像应用服务器里面会包含更多的业务逻辑,所以就会消耗更多的CPU和内存,因此对于应用服务器就可以选用CPU和内存更强的主机。想存储服务器就需要更大的硬盘空间,更快的数据访问速度,因此可以选用更大硬盘的主机。

应用服务集群架构
应用服务器可能会比较吃CPU和内存如果把CPU或者内存吃没了,此时应用服务器就顶不住了。
此时引入更多的应用服务器,就可以有效解决上述问题
用户的请求先到负载均衡器,再由负载均衡器分发给应用服务器,就可以让单个应用服务器承担总请求数的一部分,尽量避免承担压力过大。这里和多线程的方式如出一辙,只不过多线程是局限于单个服务器中的。
负载均衡器就好像小组里的领导,负责管理并将任务分配给组里的每个成员。常见的分配算法例如轮询算法,当然需要根据不同的场景应用不同的分配算法

那么又有问题了,这样子看起来负载均衡器不就承担了所有请求嘛。实际上负载均衡器对于请求量的承担能力要远超过应用服务器的,因
为负载均衡器并不需要处理请求的业务逻辑,它只是负责分配工作。如果负载均衡器确实是顶不住了,那只需要引入更多的负载均衡器即
可
读写分离 / 主从分离架构
现在的架构里,无论扩展多少台服务器,这些请求最终都会从数据库读写数据,到一定程度之后,数据的压力称为系统承载能力的瓶颈
点。我们可以像扩展应用服务器一样扩展数据库服务器么
答案是否定的,因为数据库服务有其特殊性:如果将数据分散到各台服务器之后,数据的一致性将无法得到保障
那么可以这样处理保留一个主要的数据库作为写入数据库,其他的数据库作为从属数据库。从库的所有数据全部来自主库的数据,经过同步后,从库可以维护着与主库一致的数据。然后为了分担数据库的压力,我们可以将写数据请求全部交给主库处理,但读请求分散到各个从库中

引入缓存–冷热分离架构
对于数据库而言,它天然的响应速度都是较慢的,因为都是要去访问硬盘。
因此为了解决这个问题,就引入了缓存的概念,缓存服务器只存放一小部分的热点数据
一般而言缓存的存储就好像二八原则,因为缓存要想快就只能变小,因此不能存储太多的数据
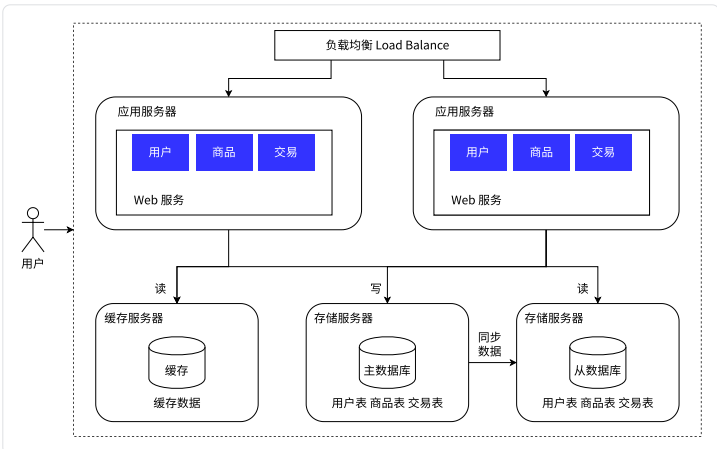
Redis主要的出现场景就是缓存
数据库分库分表存储集群
引入分布式系统,不光要能够处理更大的请求量(并发量),也需要去应对更大的数据量
随着业务的数据量增大,大量的数据存储在同⼀个库中已经显得有些力不从心了,所以可以按照业务将数据分别存储。也就是可以引入多个数据库服务器,每个数据库服务器存储一个或者一部分数据库

每个存储集群中对应一个或者一部分的数据,例如一个存储集群里负责存储商品评论的数据,一个负责存储用户信息等
具体的分库分表还是得要结合实际的使用场景展开分析
微服务架构
上述的应用服务器,一个服务器程序里面做了很多的业务,这就可能导致一个服务器会变得越来越复杂
为了更方便的维护,就可以把一个复杂的服务器拆分成更多的功能更单一但是更小的服务器—微服务器
使用微服务可以更方便于功能的复用,同时可以给不同的服务进行不同的部署

引入微服务就需要付出一些代价
- 整个系统的性能会下降,拆分更多的服务意味着多个功能之间要更依赖网络通信。通常情况下网络的速度比硬盘还要慢。
- 系统复杂程度提高,可用性会受到影响。这就需要更丰富的监控中心等手段来保证系统的可用性
小结
- 单机架构(应用程序 + 数据库服务器)
- 数据库和应用分离(应用程序和数据库服务器分别在不同主机上部署)
- 引入负载均衡器(应用服务器 — 集群)(有负载均衡器分发任务给集群中的应用服务器)
- 引入数据库主从结构(读写分离)(主写从读)(主修改过的数据需要同步给从)
- 引入缓存(冷热数据分离)(Redis在分布式系统中通常就扮演着缓存)
- 数据库分库分表
- 引入微服务架构(从业务上拆分应用服务器)
所谓的分布式系统本质上就是想办法引入更多的硬件资源
-
相关阅读:
ORBslam3中想把ros的代码放在主工程里编译出现内存错误
近期面试问题答得不好的知识
回收站数据恢复,就用这4招,轻松恢复数据!
006_Nacos注册中心【Windows和Linux安装Nacos】
HashMap在JDK1.7和JDK1.8中有哪些不同?HashMap的底层实现
数据隐私重塑:Web3时代的隐私保护创新
第1章_搭建开发环境
微信小程序canvas画布不清晰解决方法
px4的gazebo仿真相机模型报错解决办法,返回值256
MySQL系列:binlog日志详解(参数、操作、GTID、优化、故障演练)
- 原文地址:https://blog.csdn.net/CHJBL/article/details/134085717