-
深度学习模型笔记
一.当运行模型时发现GPU内存不够
方法一:在测试时,加上with torch.no_grad():
如下,再评估集上进行测试,在遍历评估集前加上with torch.no_grad():

方法二:torch.cuda.empty_cache()
torch.cuda.empty_cache() 是 PyTorch 中的一个函数,用于清空当前 CUDA(Compute Unified Device Architecture,计算统一设备架构)设备上的未使用的缓存。
当你在使用 PyTorch 进行深度学习模型的训练或推理时,数据和模型通常会被加载到 GPU 中。这些数据和模型存储在 GPU 的内存中。然而,当 GPU 内存中的某些部分没有被使用时,它们仍然会被占用,这就是所谓的缓存。
torch.cuda.empty_cache() 函数的作用是清空这些未使用的缓存,从而释放出一些 GPU 内存,使其可以被重新利用。这对于在资源有限的情况下管理 GPU 内存非常有用。
这个函数通常在以下情况下使用:
当你的模型或数据不再需要被存储在 GPU 内存中时。例如,如果你已经完成了一次批量训练或推理,并且接下来要开始一个新的批次,那么你可以在开始新的批次之前调用这个函数来清空未使用的缓存。 当你的 GPU 内存使用率过高,需要释放一些内存以避免内存溢出时。- 1
- 2
请注意,这个函数只能清空未使用的缓存,而不能直接减少你正在使用的 GPU 内存。也就是说,如果你的模型或数据仍然在 GPU 内存中,那么这些内存不会被释放。因此,你应该在确定不再需要 GPU 内存中的数据或模型后,再调用这个函数。
二.加载和保存模型参数
2.1 正常保存和加载模型参数
保存模型参数
model = MLP() # 此处省略训练过程,在训练之后,保存模型参数 # 保存字典格式的模型参数,模型参数名 torch.save(model.state_dict(), 'best.pth')- 1
- 2
- 3
- 4
加载模型参数
model = MLP() # 加载模型参数 model.load_state_dict(torch.load('best.pth')) # 进入评估模式 model.eval()- 1
- 2
- 3
- 4
- 5
2.2 保存参数的同时保存准确率和epoch等
保存参数
state_dict = dict(epoch=epoch + 1, model=model.state_dict(), acc=val_acces) torch.save(state_dict, 'model_dict.pth')- 1
- 2
加载参数
ckpt_path = '/opt/software/computer_vision/codes/My_codes/paper_codes/DLB-main/dlb/imagenet_dog/r_e_s_n_e_t_3_2TP3_0.5/resnet32/ckpt/resnet_78.31.pth' ckpt = torch.load(ckpt_path) # 得到最优准确率的epoch epoch = ckpt['epoch'] # 准确率 val_acc = ckpt['acc'] # 模型参数 model.load_state_dict(ckpt['model'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.3 当训练时使用了nn.DataParallel时,正确的加载方法
model = Model() model_para_dict_temp = torch.load('xxx.pth') model_para_dict = {} for key_i in model_para_dict_temp.keys(): model_para_dict[key_i[7:]] = model_para_dict_temp[key_i] # 删除掉前7个字符'module.' del model_para_dict_temp model.load_state_dict(model_para_dict)- 1
- 2
- 3
- 4
- 5
- 6
- 7
nn.DataParallel是一种用于多GPU计算的封装模块。它可以将模型和数据分布到多个GPU上进行并行计算,以加速训练过程。在PyTorch中,nn.DataParallel可以接受一个已存在的模型作为输入,并将模型和数据分布到多个GPU上进行并行计算。这种并行计算可以显著减少训练时间,并提高模型的收敛速度。在使用nn.DataParallel时,需要将模型和数据传递给封装后的nn.DataParallel对象,并在训练过程中使用封装后的模型进行前向传播和反向传播。- 1
直接使用第一种加载方式会报错
RuntimeError: Error(s) in loading state_dict for Sequential: 该错误通常与使用了nn.DataParallel进行训练有关 是指模型中的参数key中字符串与torch.load获取的key中字符串不匹配 因此,我们只需要修改torch.load获取的dict,令其匹配。 例如: 我torch.save时,参数key中字符串前自动添加了'module.' 因此,在torch.load后,需要去掉'module.'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
pytorch加载时出现“RuntimeError: Error(s) in loading state_dict for Sequential:”时的解决方案
https://www.cnblogs.com/s-tyou/p/16514693.htmlkaggle CIFAR-10图像分类笔记
对数据集的处理

train: 训练集- 1
train_valid: 训练集中的验证集,每个epoch结束后使用它进行验证。- 1
test: 模型所有轮训练结束后,使用它来进行测试。- 1
valid: 验证集,评估在未见过的数据上的数据集。- 1
损失函数
loss = nn.CrossEntropyLoss(reduction='none') reduction的字面意思是“减少”或“缩减”,指的是对损失进行某种操作以减小或简化损失的计算。 当reduction='none'时,表示不进行任何归约操作,即每个样本的损失都单独计算并返回。 当reduction='sum'时,表示对所有样本的损失进行求和操作,得到一个标量值,表示所有样本损失的总和。 当reduction='elementwise_mean'时,表示对所有样本的损失进行平均操作,得到一个标量值,表示所有样本损失的平均值。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
lr_period, lr_decay = 4, 0.9 的含义
lr_period = 4: lr_period表示学习率更新的周期。设置为4可能意味着在每4个epoch后更新学习率。 lr_decay = 0.9: lr_decay表示学习率的衰减率。这里设置为0.9,意味着每次更新学习率时,学习率会乘以0.9,从而逐渐降低学习率。- 1
- 2
- 3
图像分类的通用训练函数(训练并保存最优训练结果参数)
该函数的输入为: train(网络,训练集的dataloader,评估集的dataloader,训练轮数,学习率,权重衰减,设备,更新学习率的周期,学习率衰减)- 1
- 2
输出为训练结果的图和损失和准确率的值。- 1
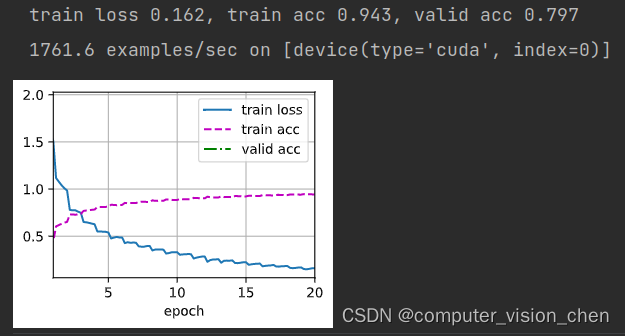
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,lr_decay): trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9,weight_decay=wd) scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay) num_batches, timer = len(train_iter), d2l.Timer() legend = ['train loss', 'train acc'] if valid_iter is not None: legend.append('valid acc') animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=legend) net = nn.DataParallel(net, device_ids=devices).to(devices[0]) # 设定一个参数 统计最优的训练准确率 best_train_acc = 0 for epoch in range(num_epochs): net.train() metric = d2l.Accumulator(3) for i, (features, labels) in enumerate(train_iter): timer.start() l, acc = d2l.train_batch_ch13(net, features, labels,loss, trainer, devices) metric.add(l, acc, labels.shape[0]) timer.stop() if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1: animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[2],None)) if valid_iter is not None: valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter) animator.add(epoch + 1, (None, None, valid_acc)) scheduler.step() train_acc = metric[1] / metric[2] measures = (f'train loss {metric[0] / metric[2]:.3f}, 'f'train acc {train_acc:.3f}') if train_acc>best_train_acc: best_train_acc = train_acc # 更新模型最优准确率的参数 torch.save(net.state_dict(),'weights/best_train_acc_params') if valid_iter is not None: measures += f', valid acc {valid_acc:.3f}' print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}' f' examples/sec on {str(devices)}') print(f'best_train_acc={best_train_acc}')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
图像分类模型训练代码
训练并统计训练的时间
'''先训练20轮看看有没有问题''' devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4 # lr_period表示学习率的更新周期,设置为4表示,每四个epoch后更新学习率, lr_decay表示权重衰减,每次更新学习率,学习率都会乘0.9 lr_period, lr_decay, net = 4, 0.9, get_net() # 开始计时 start_time = time.time() # 开始训练 train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,lr_decay) # 结束计时 end_time = time.time() run_time = end_time - start_time # 将输出的秒数保留两位小数 if int(run_time)<60: print(f'{round(run_time,2)}s') else: print(f'{round(run_time/60,2)}minutes')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

-
相关阅读:
Kernel:性能分析实例(一)
letterbox实现
如何简单理解大数据
冰冰学习笔记:基础IO
k8s的“前端”——ingress
鸿蒙系统环境搭建、源码编译与烧写之经典
如果使用pprof来进行性能的观测和优化
JS实时获取录音数据并播放
基于session实现发送短信和验证码登录注册功能
数仓主题域和数据域、雪花模型,星型模型和星座模型
- 原文地址:https://blog.csdn.net/qq_42864343/article/details/134033897
