-
深度学习:激活函数曲线总结
深度学习:激活函数曲线总结
在深度学习中有很多时候需要利用激活函数进行非线性处理,在搭建网路的时候也是非常重要的,为了更好的理解不同的激活函数的区别和差异,在这里做一个简单的总结,在pytorch中常用的激活函数的数学表达形式,同时为了更直观的感受,给出不同激活函数的曲线形式,方便查询。
import torch import torch.nn as nn x = torch.linspace(-4, 4, 400) # 在-4和4之间画400个点。- 1
- 2
- 3
1. nn.leakyReLU()
给负值一个斜率,不全为零。
- 数学公式:
LeakyReLU ( x ) = { x , if x ≥ 0 negative_slope × x , otherwise \text{LeakyReLU}(x) =LeakyReLU(x)={x,negative_slope×x, if x≥0 otherwise { x , if x ≥ 0 negative\_slope × x , otherwise
leakyrelu = nn.LeakyReLU(negative_slope=0.01)- 1
negative_slope是一个小于1的值,通常设置为0.01,用于控制在输入小于0时的输出斜率。这意味着在nn.LeakyReLU中,负数输入会乘以negative_slope,而正数输入保持不变。- 对应曲线:

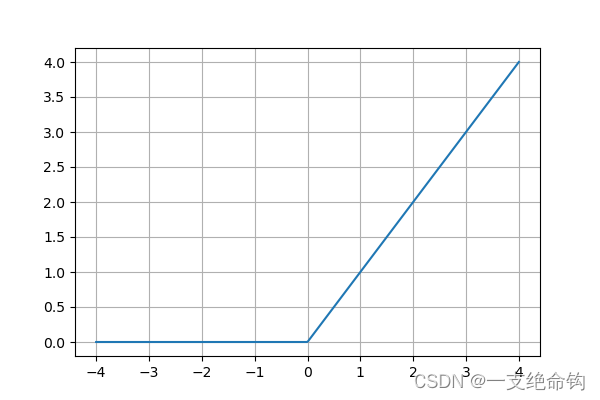
2. nn.Relu()
ReLU是一个常用的激活函数,它将负数值设为0,保持正数值不变。
- 数学公式:
ReLU ( x ) = ( x ) + = max ( 0 , x ) \text{ReLU}(x) = (x)^+ = \max(0, x) ReLU(x)=(x)+=max(0,x)
relu = nn.ReLU()- 1
- 函数曲线:
3. nn.Tanh()
Tanh函数将输入映射到-1和1之间
- 数学公式
Tanh ( x ) = tanh ( x ) = exp ( x ) − exp ( − x ) exp ( x ) + exp ( − x ) \text{Tanh}(x) = \tanh(x) = \frac{\exp(x) - \exp(-x)} {\exp(x) + \exp(-x)} Tanh(x)=tanh(x)=exp(x)+exp(−x)exp(x)−exp(−x)
Tanh = nn.Tanh()- 1
- 函数曲线

4. nn.PReLU()
PReLU是具有可学习参数的激活函数,用于克服ReLU的一些问题
- 数学公式
RReLU ( x ) = { x if x ≥ 0 a x otherwise \text{RReLU}(x) =RReLU(x)={xaxif x≥0 otherwise { x if x ≥ 0 a x otherwise
PReLU = nn.PReLU(num_parameters=1)- 1
- 函数曲线

5. nn.ELU()
所有点上都是连续的和可微的,训练快
- 数学公式:
ELU ( x ) = { x , if x > 0 α ∗ ( exp ( x ) − 1 ) , if x ≤ 0 \text{ELU}(x) =ELU(x)={x,α∗(exp(x)−1), if x>0 if x≤0{ x , if x > 0 α ∗ ( exp ( x ) − 1 ) , if x ≤ 0
ELU = nn.ELU()- 1
- 函数曲线

6. nn.SELU()
- 数学公式:
SELU ( x ) = scale ∗ ( max ( 0 , x ) + min ( 0 , α ∗ ( exp ( x ) − 1 ) ) ) \text{SELU}(x) = \text{scale} * (\max(0,x) + \min(0, \alpha * (\exp(x) - 1))) SELU(x)=scale∗(max(0,x)+min(0,α∗(exp(x)−1)))
SELU = nn.SELU()- 1
- 函数曲线:

7. nn.GELU()
- 数学公式:
GELU ( x ) = x ∗ Φ ( x ) \text{GELU}(x) = x * \Phi(x) GELU(x)=x∗Φ(x)
GELU = nn.GELU()- 1
- 函数曲线:

8. nn.Mish()
- 数学公式:
Mish ( x ) = x ∗ Tanh ( Softplus ( x ) ) \text{Mish}(x) = x * \text{Tanh}(\text{Softplus}(x)) Mish(x)=x∗Tanh(Softplus(x))
Mish = nn.Mish()- 1
- 函数曲线:

9 . nn.Softmax()
- 数学公式:
Softmax ( x i ) = exp ( x i ) ∑ j exp ( x j ) \text{Softmax}(x_{i}) = \frac{\exp(x_i)}{\sum_j \exp(x_j)} Softmax(xi)=∑jexp(xj)exp(xi)
Softmax = nn.Softmax() y = Softmax(x)- 1
- 2
- 函数曲线:

总结
感觉还是看曲线的形状,把大体的形状记住更直观些。
-
相关阅读:
设计模式笔记
第一章 基础算法(三)
Capstone 反汇编引擎
Android 性能优化--内存优化分析总结
JS new操作符具体做了什么?
位置编码(PE)是如何在Transformers中发挥作用的
kubernetes负载均衡部署
Spring boot 集成 xxl-job
数据结构系列学习(六) - 顺序栈(Stack)
Dubbo 服务注册与启动源码解析
- 原文地址:https://blog.csdn.net/qudunan6468/article/details/134061765