-
目标检测及锚框、IoU
1. 目标检测
物体检测(目标检测)是计算机视觉和数字图像处理的热门方向,意在判断一幅图像上是否存在感兴趣物体,并给出物体分类及位置等(What and Where)。本文主要进行物体检测研究背景、发展脉络、相关算法及评价指标的概述。
我们要识别中所有我们感兴趣的物体,并且找出每个物体的位置。
边缘框
边缘框是图片中物体的真实位置和范围,有两种表示方式,一种是边角坐标表示法,通过物体左上和右下两个角的坐标表示一个矩形框,还有一种是中心表示法,用物体的中心和宽高表示矩形框。
- 一个边缘框可以通过4个数字定义
- (左上x,左上y,右下x,右下y)
- (左上x,左上y,宽,高)

目标检测数据集
- 每行表示一个物体
- 图片文件名、物体类别、边缘框
- COCO数据集
- 80物体,330K图片,1.5M物体
定义两种边缘框之间的转换函数
import torch def box_corner_to_center(boxes): """ 从(左上,右下)转换到(中间,宽度,高度) """ x1,y1,x2,y2 = boxes[:,0],boxes[:,1],boxes[:,2],boxes[:,3] cx = (x1+x2)/2 cy = (y1+y2)/2 w = x2-x1 h = y2-y1 boxes = torch.stack((cx,cy,w,h),dim=1) return boxes def box_center_to_corner(boxes): """从(中间,宽度,高度)转换到(左上,右下)""" cx,cy,w,h = boxes[:,0],boxes[:,1],boxes[:,2],boxes[:,3] x1 = cx - 0.5 * w y1 = cy - 0.5 * h x2 = cx + 0.5 * w y2 = cy + 0.5 * h boxes = torch.stack((x1, y1, x2, y2), dim=1) return boxes- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
边缘框实现
from matplotlib import pyplot as plt # 将边界框在图中画出 def bbox_to_rect(bbox,color): return plt.Rectangle( xy=(bbox[0], bbox[1]), width=bbox[2] - bbox[0], height=bbox[3] - bbox[1], fill=False, edgecolor=color, linewidth=2) dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0] fig = plt.figure(figsize=(5,8),dpi=100) ax1 = fig.add_subplot(1,1,1) image= plt.imread("code/images/catdog.jpg") ax1.imshow(image) ax1.axes.add_patch(bbox_to_rect(dog_bbox, 'blue')) ax1.axes.add_patch(bbox_to_rect(cat_bbox, 'red')); plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2. 锚框
在众多经典的目标检测模型中,均有先验框的说法,有的paper(如Faster RCNN)中称之为anchor(锚点),有的paper(如SSD)称之为prior bounding box(先验框),实际上是一个概念。
锚框的作用:
对于目标检测任务,有这样一种经典解决方案:遍历输入图像上所有可能的像素框,然后选出正确的目标框,并对位置和大小进行调整就可以完成目标检测任务。这些进行预测的像素框就叫锚框。这些锚框通常都是方形的。
同时,为了增加任务成功的几率,通常会在同一位置设置不同宽高比的锚框。锚框的设置形式有很多种。
- 一类目标检测算法是基于锚框
- 提出多个被称为锚框的区域(边缘框)
- 预测每个锚框里是否含有关注的物体
- 如果是,预测从这个锚框到真实边缘的偏移

3. IoU - 交并比
IoU用来计算两个框之间的相似度
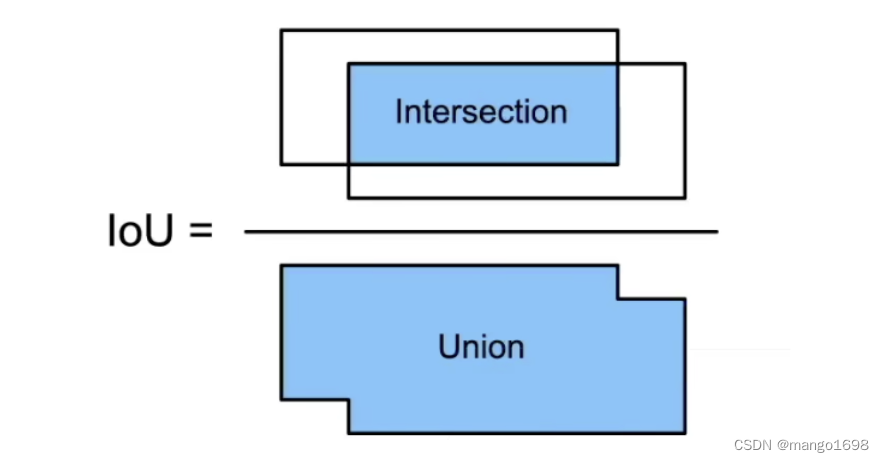
- 0表示无重叠,1表示重合
这是Jacquard指数的一个特殊情况
给定两个集合 A A A和 B B B
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B)=\frac{|A \cap B|}{|A \cup B|} J(A,B)=∣A∪B∣∣A∩B∣
4. 赋予锚框标号
-
每个锚框是一个训练样本
-
将每个锚框,要么标注成背景,要么关联上一个真实边缘框
-
我们可能会生成大量的锚框
- 这个导致大量的负类样本
在蓝色格子里面寻求IoU的最高值,选中,比如:
第一个最大值为 x 23 x_{23} x23,那就用锚框2来预测边缘框3,去除锚框2边缘框3所对应的行列。
继续在剩下的格子里面寻找最大值,如 x 71 x_{71} x71,那就用锚框7来预测边缘框1,去除锚框7边缘框1所对应的行列。

赋予标号的方式有很多种。
5. 使用非极大值抑制(NMS)输出
- 每个锚框预测一个边缘框
- NMS可以合并相似的预测
- 选中的是非背景类的最大预测值
- 去掉所有其它和它IoU值大于 θ \theta θ的预测
- 重复上诉过程直到所有预测要么被选中,要么被去掉
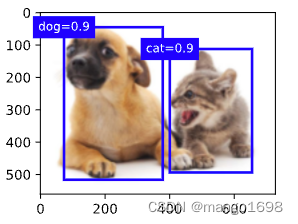
如:

首先选取狗类别的最大预测值,为0.9,然后去除该类别预测值小于0.9且IoU大于 θ \theta θ的值。
然后选取猫类别的最大预测值,为0.9,然后去除该类别预测值小于0.9且IoU大于 θ \theta θ的值。
总结:
- 一类目标检测算法基于锚框来预测
- 首先生成大量锚框,并赋予标号,每个锚框作为一个样本进行训练
- 在预测时,使用NMS来去掉冗余的预测
- 一个边缘框可以通过4个数字定义
-
相关阅读:
LLM - LLaMA-2 获取文本向量并计算 Cos 相似度
使用clip-path将 GIF 绘制成跳动的字母
一文了解Pycharm快捷键
2、React中的JSX使用
《最新出炉》系列初窥篇-Python+Playwright自动化测试-11-playwright操作iframe-上篇
Android 如何添加自定义字体
安科瑞ADL400产品功能及参数说明,适用于5G基站计量使用
React18 新特性
【无标题】markdow 模板
qt 中保存图片,图片的名字,按照时间来保存
- 原文地址:https://blog.csdn.net/weixin_45682053/article/details/134080317