-
Python学习之pandas模块duplicated函数的常见用法
pandas库中的
duplicate()函数常用于查找和处理数据中的重复项。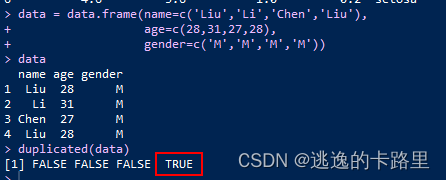
以下是
duplicate()函数的常见用法:-
查找重复项:使用
duplicate()函数可以查找数据中的重复项。例如,df.duplicated()可以返回一个布尔数组,指示每一行是否是重复项。 -
删除重复项:可以使用
drop_duplicates()函数删除数据中的重复项。例如,df.drop_duplicates()会返回一个去除重复行的新数据集。 -
指定列进行重复项的查找和删除:
duplicate()和drop_duplicates()函数还可以通过指定列名来查找和删除重复项。例如,df.duplicated(['col1', 'col2'])会查找指定列(col1和col2)中的重复项。 -
保留重复项的第一个或最后一个:
drop_duplicates()函数也可以选择保留重复项的第一个或最后一个。可以使用keep参数来指定保留的方式,默认为'first'(保留第一个重复项),可以设置为'last'(保留最后一个重复项)。 -
标记重复项:可以使用
duplicated()函数标记数据中的重复项。通过设置keep=False,df.duplicated()会返回一个布尔数组,所有重复项都会被标记为True。 -
统计重复项:
duplicated()函数还可以使用sum()函数来统计重复项的数量。例如,df.duplicated().sum()会返回数据中重复项的总数。 -
检查重复项并替换:
replace()函数可以将数据集中的某个值替换为另一个值。可以利用duplicated()函数检查数据中的重复项,并用replace()函数将其替换成其他值。例如,df.replace({'duplicate_value': 'new_value'})可以将数据集中所有的’duplicate_value’替换为’new_value’。 -
指定不同的重复项:
drop_duplicates()函数还可以通过指定不同的列或者在subset参数中指定多个列来查找和删除不同的重复项。例如,df.drop_duplicates(subset=['col1', 'col2'])将删除其中一组’col1’和’col2’列完全相同的行。 -
设定阈值:
drop_duplicates()函数支持设定阈值参数keep。当keep=True且阈值超过2时,会保留出现次数大于等于阈值的重复项。例如,df.drop_duplicates(subset='col1',keep=False,threshold=3)将删除’col1’列中出现了3次及以下的重复项。 -
根据指定列对重复项进行排序:
drop_duplicates()函数还支持根据指定列的值对重复项进行排序。可以使用subset参数指定列名,并使用keep参数来保留第一个或最后一个重复项。例如,df.drop_duplicates(subset=['col1'], keep='first').sort_values(by=['col1'])将根据’col1’列的值对重复项进行排序,并保留第一个出现的重复项。 -
删除重复项并保留最后一个:如果要删除重复项,但保留最后一个重复项,可以使用
keep='last'参数。例如,df.drop_duplicates(keep='last')将删除数据中的重复项,并仅保留每个重复组中的最后一个。 -
检查重复索引:除了检查重复行,还可以使用
duplicated()函数检查是否存在重复索引。例如,df.index.duplicated()会返回一个布尔数组,指示每个索引是否是重复的。 -
检查重复值:使用
duplicated()函数和unique()函数可以检查数据中的重复值。例如,df['col1'].duplicated()会返回一个布尔数组,指示’col1’列中的每个值是否重复。如果要获取重复的唯一值,可以使用df['col1'].duplicated().unique()。
这些是关于
duplicate()函数的更多常见用法,可以根据具体需求选择合适的方式来处理数据中的重复项。下面是一个具体的示例代码,解释了上述列举函数的用法:
import pandas as pd # 创建一个包含重复项的数据集 data = { 'col1': ['A', 'B', 'A', 'C', 'D', 'E', 'F', 'G', 'A'], 'col2': ['W', 'X', 'Y', 'Z', 'W', 'X', 'Y', 'Z', 'R'], 'col3': [1, 2, 3, 4, 1, 2, 3, 4, 5] } df = pd.DataFrame(data) # 查找重复项 duplicates = df.duplicated() print(duplicates) # 删除重复项 df_dropped = df.drop_duplicates() print(df_dropped) # 指定列进行重复项的查找和删除 duplicates_col1_col2 = df.duplicated(['col1', 'col2']) print(duplicates_col1_col2) df_dropped_col1_col2 = df.drop_duplicates(['col1', 'col2']) print(df_dropped_col1_col2) # 保留重复项的第一个或最后一个 df_dropped_keep_last = df.drop_duplicates(keep='last') print(df_dropped_keep_last) # 统计重复项 duplicates_sum = duplicates.sum() print(duplicates_sum) # 标记重复项 duplicates_boolean = df.duplicated(keep=False) print(duplicates_boolean) # 检查重复项并替换 df_replaced = df.replace({'A': 'Z'}) print(df_replaced) # 指定不同的重复项 df_dropped_diff = df.drop_duplicates(subset=['col1'], keep=False) print(df_dropped_diff) # 设定阈值 df_dropped_threshold = df.drop_duplicates(subset='col1', keep=False, threshold=3) print(df_dropped_threshold) # 根据指定列对重复项进行排序 df_drop_sort = df.drop_duplicates(subset=['col1'], keep='first').sort_values(by=['col1']) print(df_drop_sort) # 检查重复索引 index_duplicates = df.index.duplicated() print(index_duplicates) # 检查重复值 col1_duplicates = df['col1'].duplicated() print(col1_duplicates) col1_duplicates_unique = col1_duplicates.unique() print(col1_duplicates_unique)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
上述代码中,首先创建了一个包含重复项的数据集,然后依次应用了列举的
duplicate()函数的各种用法,例如查找重复项、删除重复项、指定列进行重复项的查找和删除、保留重复项的第一个或最后一个等等。在代码执行过程中,可以检查函数的输出结果以了解它们的功能。参考文献:python-pandas-index-duplicated
这里也借鉴了几张搜集到的简单示例图,供大家参考:





-
-
相关阅读:
11、Service访问Pod、Service IP原理、DNS访问Service、外部访问service
ms17-010(永恒之蓝)漏洞复现
如何在Docker部署Draw.io绘图工具并远程访问
Linux知识点 -- 网络基础 -- 数据链路层
redis学习归纳
放到WEB-INF中的文件,不能直接通过浏览器地址栏访问了
.NET CORE 授权
数仓建模理论
访问外网的安全保障——反向沙箱
Tarjan 求有向图的强连通分量
- 原文地址:https://blog.csdn.net/u014740628/article/details/134047456
