-
【自然语言处理】理解词向量、CBOW与Skip-Gram模型
由于计算机不能直接对各种字符进行运算,为此需要将词的表示进行一些转换。因此,在自然语言处理中,通常需要对输入的语料进行一些预处理:

其中,如何对词汇进行表示是很关键的问题,糟糕的表示方法容易导致所谓的 “Garbage in, garbage out”。一、词向量基础知识
对词汇的表示,常见的有
One-hot represention和Distributed Representation两种形式。1.1 One-hot表示
One-hot represention 将词汇用二进制向量表示,这个向量表示的词汇,仅仅在词汇表中的索引位置处为1,其他地方都为0。例子如下图所示:

这样的方式表示词汇虽然简单,但是也有如下缺点:- 单词的上下文丢失了。
- 没有考虑频率信息。
- 词汇量大的情况下,向量维度高且稀疏,占用内存。
1.2 Distributed表示
Distributed Representation 也可以理解为Word Embedding,具体形式为:

注意到,使用Word Embedding得到的向量维度远小于词汇表的个数。如果将上面的向量在空间中表示,可以得到:

上图告诉我们,通过词向量之间的距离可以度量他们之间的关系,意思相近的词在空间中的距离比较近。出现这种现象的原因是最后得到的词向量在训练过程中学习到了词的上下文。那么,Distributed Representation 要如何得到?
- 使用神经网络语言模型可以得到;
- 使用word2vec。
二、word2vec基础知识
word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。在正式讲解 word2vec 前,还需要对一些基本概念有所了解。
2.1 CBOW和Skip-gram
CBOW模型(Continuous Bag-of-Words Model)和Skip-gram模型(Continuous Skip-gram Model)。如下图所示:

由图可见,两个模型都包含三层:输入层、投影层和输出层。区别在于:- CBOW模型: 在已知上下文 w t − 2 , w t − 1 , w t + 1 w t + 2 w_{t-2}, w_{t-1}, w_{t+1} w_{t+2} wt−2,wt−1,wt+1wt+2的前提下预测当前词 w t w_t wt
- Skip-gram模型: 在已知当前词 w t w_t wt的前提下预测上下文 w t − 2 , w t − 1 , w t + 1 w t + 2 w_{t-2}, w_{t-1}, w_{t+1} w_{t+2} wt−2,wt−1,wt+1wt+2
三、基于Hierarchical Softmax的 CBOW 模型和 Skip-gram 模型
3.1 CBOW 模型
CBOW 模型是 在已知上下文 w t − 2 , w t − 1 , w t + 1 w t + 2 w_{t-2}, w_{t-1}, w_{t+1} w_{t+2} wt−2,wt−1,wt+1wt+2的前提下预测当前词 w t w_t wt 。后面我们用 c o n t e x t ( w ) context(w) context(w)来表示词 w w w的上下文中的词,通常,我们取词 w w w前后 2 2 2c个单词来组成 c o n t e x t ( w ) context(w) context(w)。下图给出了CBOW模型的网络结构:

它包括三层:输入层、投影层、输出层。
- 输入层:包含
c
o
n
t
e
x
t
(
w
)
context(w)
context(w)中的
2
c
2c
2c个词向量
v
(
c
o
n
t
e
x
t
(
w
)
1
)
,
v
(
c
o
n
t
e
x
t
(
w
)
2
)
,
…
,
v
(
c
o
n
t
e
x
t
(
w
)
2
c
)
∈
R
m
\mathbf v(context(w)_1),\mathbf v(context(w)_2),\ldots,\mathbf v(context(w)_{2c}) \in \mathbf R^m
v(context(w)1),v(context(w)2),…,v(context(w)2c)∈Rm
,每个词向量的长度是 m m m。 - 投影层:将输入层的 2 c 2c 2c个词向量累加求和,即 x w = ∑ i = 1 2 c v ( c o n t e x t ( w ) i ) \mathbf x_w = \sum_{i=1}^{2c}\mathbf v(context(w)_i) xw=∑i=12cv(context(w)i)。
- 输出层:输出层是用哈夫曼算法以各词在语料中出现的次数作为权值生成的一颗二叉树,其叶子结点是语料库中的所有词,叶子个数 N = ∣ D ∣ N=|D| N=∣D∣,分别对应词典D中的词。
神经网络语言模型(NNLM)中大部分计算集中在隐藏层和输出层之间的矩阵向量运算,以及输出层上的softmax归一化运算,CBOW模型对此进行了改进。与传统的神经网络语言模型相比:
- NNLM是简单的将输入的向量进行拼接,而CBOW模型将上下文的词累加求和作为输入;
- NNLM是线性结构,而CBOW是树形结构
- NNLM具有隐藏层,而CBOW没有隐藏层
3.2 Skip-gram 模型
Skip-gram 模型的结构也是三层,下面以样本 ( w , c o n t e x t ( w ) (w,context(w) (w,context(w)为例说明。如下图所示:
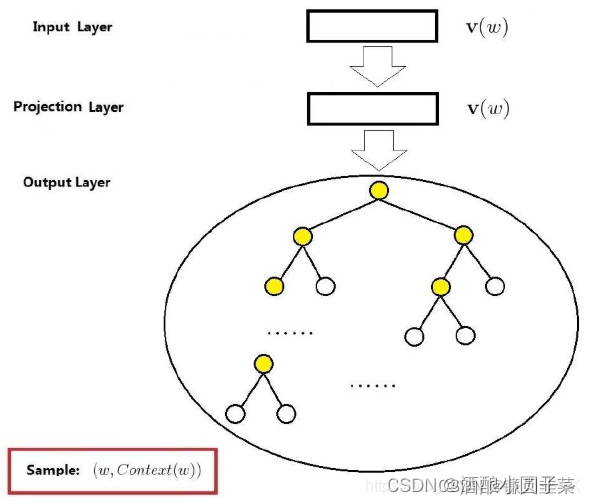
它也包括三层:输入层、投影层、输出层。- 输入层:只包含当前样本中心词 w w w词向量 v ( w ) ∈ R m \mathbf v(w) \in \mathbf R^m v(w)∈Rm,每个词向量的长度是 m m m。
- 投影层:恒等投影,即和输入层一样,保留是为了与CBOW对比。
- 输出层:与CBOW类似
对于Skip-gram模型,已知的是当前词 w w w,需要对其上下文 c o n t e x t ( w ) context(w) context(w)中的词进行预测,所以:

类似于CBOW,所以:

其中:

所以我们的优化目标是:

采用随机梯度上升法将这个函数最大化。参考资料
-
相关阅读:
Python实现SSA智能麻雀搜索算法优化XGBoost回归模型(XGBRegressor算法)项目实战
【opencv-c++】cv::createShapeContextDistanceExtractor形状上下文距离匹配算法
单点登录认识
Ant Design入门、Ant Design Pro入门
单链表的模拟实现
文心一言api接入如何在你的项目里使用文心一言
记录一次腾讯测试开发工程师自动化接口测试实践经验
图像处理与计算机视觉--第五章-图像分割-霍夫变换
【你问我答】Unity实现类似DNF地下城勇士的2D人物移动跳跃
Terraform 系列-使用 for-each 对本地 json 进行迭代
- 原文地址:https://blog.csdn.net/u012856866/article/details/134016921