-
分类预测 | MATLAB实现SSA-CNN-BiGRU-Attention数据分类预测(SE注意力机制)
分类预测 | MATLAB实现SSA-CNN-BiGRU-Attention数据分类预测(SE注意力机制)
分类效果






基本描述
1.MATLAB实现SSA-CNN-BiGRU-Attention数据分类预测(SE注意力机制),运行环境Matlab2021b及以上;
2.基于麻雀优化算法(SSA)、卷积神经网络(CNN)和双向门控循环单元(BiGRU)、SE注意力机制的数据分类预测程序;
3.多特征输入单输出的二分类及多分类模型。程序内注释详细,直接替换数据就可以用;SSA优化算法优化学习率、正则化系数、隐藏层节点,这3个关键参数。
程序语言为matlab,程序可出分类效果图,混淆矩阵图;
4.data为数据集,输入12个特征,分四类;main为主程序,其余为函数文件,无需运行。
5.适用领域:适用于各种数据分类场景,如滚动轴承故障、变压器油气故障、电力系统输电线路故障区域、绝缘子、配网、电能质量扰动,等领域的识别、诊断和分类。
使用便捷:直接使用EXCEL表格导入数据,无需大幅修改程序。内部有详细注释,易于理解。模型描述
注意力机制模块:
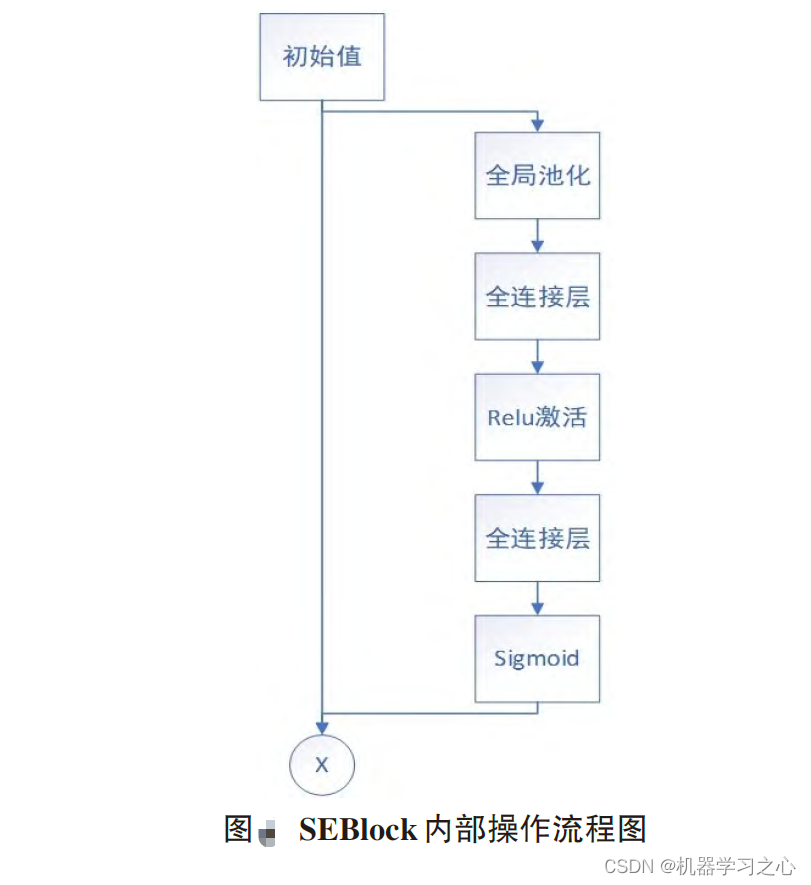
SEBlock(Squeeze-and-Excitation Block)是一种聚焦于通道维度而提出一种新的结构单元,为模型添加了通道注意力机制,该机制通过添加各个特征通道的重要程度的权重,针对不同的任务增强或者抑制对应的通道,以此来提取有用的特征。该模块的内部操作流程如图,总体分为三步:首先是Squeeze 压缩操作,对空间维度的特征进行压缩,保持特征通道数量不变。融合全局信息即全局池化,并将每个二维特征通道转换为实数。实数计算公式如公式所示。该实数由k个通道得到的特征之和除以空间维度的值而得,空间维数为H*W。其次是Excitation激励操作,它由两层全连接层和Sigmoid函数组成。如公式所示,s为激励操作的输出,σ为激活函数sigmoid,W2和W1分别是两个完全连接层的相应参数,δ是激活函数ReLU,对特征先降维再升维。最后是Reweight操作,对之前的输入特征进行逐通道加权,完成原始特征在各通道上的重新分配。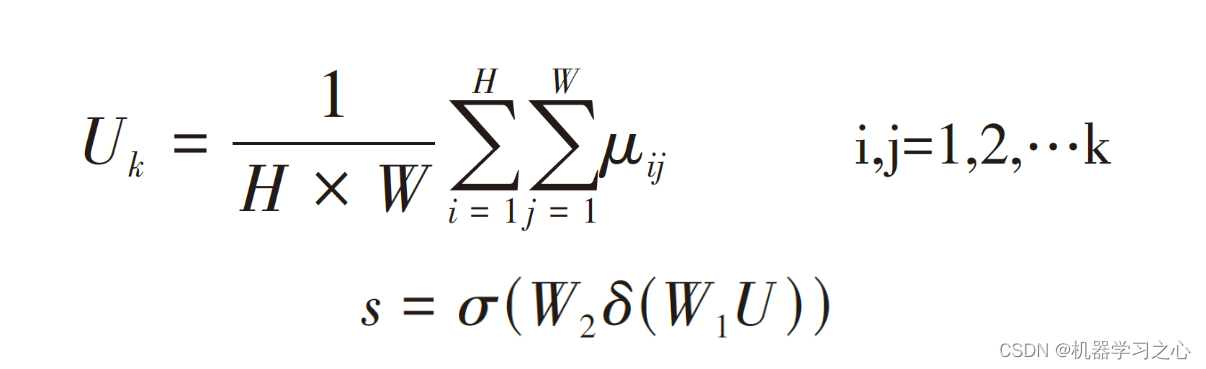
程序设计
- 完整程序和数据获取方式:私信博主回复MATLAB实现SSA-CNN-BiGRU-Attention数据分类预测(SE注意力机制)。
%% 优化算法参数设置 SearchAgents_no = 8; % 数量 Max_iteration = 5; % 最大迭代次数 dim = 3; % 优化参数个数 lb = [1e-3,10 1e-4]; % 参数取值下界(学习率,隐藏层节点,正则化系数) ub = [1e-2, 30,1e-1]; % 参数取值上界(学习率,隐藏层节点,正则化系数) fitness = @(x)fical(x,num_dim,num_class,p_train,t_train,T_train); [Best_score,Best_pos,curve]=SSA(SearchAgents_no,Max_iteration,lb ,ub,dim,fitness) Best_pos(1, 2) = round(Best_pos(1, 2)); best_hd = Best_pos(1, 2); % 最佳隐藏层节点数 best_lr= Best_pos(1, 1);% 最佳初始学习率 best_l2 = Best_pos(1, 3);% 最佳L2正则化系数 %% 建立模型 lgraph = layerGraph(); % 建立空白网络结构 tempLayers = [ sequenceInputLayer([num_dim, 1, 1], "Name", "sequence") % 建立输入层,输入数据结构为[num_dim, 1, 1] sequenceFoldingLayer("Name", "seqfold")]; % 建立序列折叠层 lgraph = addLayers(lgraph, tempLayers); % 将上述网络结构加入空白结构中 tempLayers = [ convolution2dLayer([3, 1], 16, "Name", "conv_1", "Padding", "same") % 建立卷积层,卷积核大小[3, 1],16个特征图 reluLayer("Name", "relu_1") % Relu 激活层 lgraph = addLayers(lgraph, tempLayers); % 将上述网络结构加入空白结构中 tempLayers = [ sequenceUnfoldingLayer("Name", "sequnfold") % 建立序列反折叠层 flattenLayer("Name", "flatten") fullyConnectedLayer(num_class, "Name", "fc") % 全连接层 softmaxLayer("Name", "softmax") % softmax激活层 classificationLayer("Name", "classification")]; % 分类层 lgraph = addLayers(lgraph, tempLayers); % 将上述网络结构加入空白结构中 lgraph = connectLayers(lgraph, "seqfold/out", "conv_1"); % 折叠层输出 连接 卷积层输入 lgraph = connectLayers(lgraph, "seqfold/miniBatchSize", "sequnfold/miniBatchSize"); %% 参数设置 options = trainingOptions('adam', ... % Adam 梯度下降算法 'MaxEpochs', 500,... % 最大训练次数 'InitialLearnRate', best_lr,... % 初始学习率为0.001 'L2Regularization', best_l2,... % L2正则化参数 'LearnRateSchedule', 'piecewise',... % 学习率下降 'LearnRateDropFactor', 0.1,... % 学习率下降因子 0.1 'LearnRateDropPeriod', 400,... % 经过训练后 学习率为 0.001*0.1 'Shuffle', 'every-epoch',... % 每次训练打乱数据集 'ValidationPatience', Inf,... % 关闭验证 'Plots', 'training-progress',... % 画出曲线 'Verbose', false); %% 训练 net = trainNetwork(p_train, t_train, lgraph, options);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129036772?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128690229 -
相关阅读:
机器学习实战-系列教程8:SVM分类实战3非线性SVM(鸢尾花数据集/软间隔/线性SVM/非线性SVM/scikit-learn框架)项目实战、代码解读
实用新型专利的注意事项
论文解读《Adversarial training methods for semi-supervised text classification》
解决2K/4K高分屏下Vmware等虚拟机下Kail Linux界面显示问题
阿里云App备案详细流程_APP备案问题解答
java使用phantomjs生成证书图片
DNS设置(linux)
jsp+ssm+maven大学生就业信息系统
C++ 网络编程 建立简单的TCP通信
秋招突击——算法打卡——6/4——复习{(状态压缩DP)小国王}——新做:{三数之和、最接近的三数之和}
- 原文地址:https://blog.csdn.net/kjm13182345320/article/details/134045281
