-
【CPP】加速
1-C and CPP with ARM
Intel vs ARM
- With the help of C/C++ compilers, C and C++ are platform independent
- But we need to know some background information on different CPUs
- Intel achieved a dominant position the personal computer market. But recently
ARM
- ARM(previously an acronym for Advanced RISC Machine and originally Avon RISC Machine) is a family of reduced instruction set computing (RISC) architectures for computer processor
- ARM is the most widely used instruction set architecture (ISA) and the ISA produced in the largest quantity
功耗低
很多核,并行计算
Raspberry Pi 4

How to develop programs with ARM Development broads
Almost the same with an X86 PC with Linux OS
- gcc/g++
- Makefile
- cmake
2- Speedup Your Program
Principle for Programming
Simple is Beautiful
Short, Simple, EfficientSome Tips on Optimization
- Choose an appropriate algorithm
- Clear and simple code for the compiler to optimize
- Optimize code for memory
- Do not copy large memory
- No printf() / cout in loops
- Table lookup (sin(), cos(), …)
- SIMD, OpenMP
An example: libfacedetection
- Face detection and facial landmark detection in 1600 lines of source code
facedetectcnn.h:
400 lines
CNN APIsfacedetectcnn.cpp:
900 lines
CNN function definitionsfacedetectcnn-model.cpp:
300 lines
Face detection modelfacedetectcnn-int8data.cpp:
CNN model parameters in static variables
不依赖任何库
SIMD: Single Instruction, Multiple Data

一个指令可以处理多个数据
SIMD in OpenCV
- “Universal intrinsics” is a types and functions set intended to simplify vectorization of code on different platforms
- OpenCV Universal Intrinsics
- 使用openCV中的universal intrinsics 为算法提速
参考文章:
使用openCV中的universal intrinsics 为算法提速1
使用openCV中的universal intrinsics 为算法提速2
使用openCV中的universal intrinsics 为算法提速3
openMP

把计算分给多个核进行计算
- Where should
#pramabe? The 1st loop or the 2nd

拆开需要时间成本的
一般来说放在外面
注意:如果每个线程写同一个数据,会有数据冲突,这里是没有保护的,要先检查循环体里面是不是相互依赖,如果是的话则不行,需要先破除依赖,再进行并行计算3-An Example with SIMD and OpenMP
ARM Cloud Server
-
HUAWEI ARM Cloud Server
-
Kunpeng 920 (2 Cores of many)
-
RAM: 3GB
-
openEuler Linux
-
Functions for dot product
matoperation.hpp
#pragma once float dotproduct(const float *p1, const float * p2, size_t n); float dotproduct_unloop(const float *p1, const float * p2, size_t n); float dotproduct_avx2(const float *p1, const float * p2, size_t n); float dotproduct_avx2_omp(const float *p1, const float * p2, size_t n); float dotproduct_neon(const float *p1, const float * p2, size_t n); float dotproduct_neon_omp(const float *p1, const float * p2, size_t n);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
matoperation.cpp
#include#include "matoperation.hpp" #ifdef WITH_AVX2 #include #endif #ifdef WITH_NEON #include #endif #ifdef _OPENMP #include #endif float dotproduct(const float *p1, const float * p2, size_t n) { float sum = 0.0f; for (size_t i = 0; i < n ; i++) sum += (p1[i] * p2[i]); return sum; } float dotproduct_unloop(const float *p1, const float * p2, size_t n) { if(n % 8 != 0) { std::cerr << "The size n must be a multiple of 8." <<std::endl; return 0.0f; } float sum = 0.0f; for (size_t i = 0; i < n; i+=8) { sum += (p1[i] * p2[i]); sum += (p1[i+1] * p2[i+1]); sum += (p1[i+2] * p2[i+2]); sum += (p1[i+3] * p2[i+3]); sum += (p1[i+4] * p2[i+4]); sum += (p1[i+5] * p2[i+5]); sum += (p1[i+6] * p2[i+6]); sum += (p1[i+7] * p2[i+7]); } return sum; } float dotproduct_avx2(const float *p1, const float * p2, size_t n) { #ifdef WITH_AVX2 if(n % 8 != 0) { std::cerr << "The size n must be a multiple of 8." <<std::endl; return 0.0f; } float sum[8] = {0}; __m256 a, b; __m256 c = _mm256_setzero_ps(); for (size_t i = 0; i < n; i+=8) { a = _mm256_loadu_ps(p1 + i); b = _mm256_loadu_ps(p2 + i); c = _mm256_add_ps(c, _mm256_mul_ps(a, b)); } _mm256_storeu_ps(sum, c); return (sum[0]+sum[1]+sum[2]+sum[3]+sum[4]+sum[5]+sum[6]+sum[7]); #else std::cerr << "AVX2 is not supported" << std::endl; return 0.0; #endif } float dotproduct_avx2_omp(const float *p1, const float * p2, size_t n) { #ifdef WITH_AVX2 if(n % 8 != 0) { std::cerr << "The size n must be a multiple of 8." <<std::endl; return 0.0f; } float sum[8] = {0}; __m256 a, b; __m256 c = _mm256_setzero_ps(); #pragma omp parallel for for (size_t i = 0; i < n; i+=8) { a = _mm256_loadu_ps(p1 + i); b = _mm256_loadu_ps(p2 + i); c = _mm256_add_ps(c, _mm256_mul_ps(a, b)); } _mm256_storeu_ps(sum, c); return (sum[0]+sum[1]+sum[2]+sum[3]+sum[4]+sum[5]+sum[6]+sum[7]); #else std::cerr << "AVX2 is not supported" << std::endl; return 0.0; #endif } float dotproduct_neon(const float *p1, const float * p2, size_t n) { #ifdef WITH_NEON if(n % 4 != 0) { std::cerr << "The size n must be a multiple of 4." <<std::endl; return 0.0f; } float sum[4] = {0}; float32x4_t a, b; float32x4_t c = vdupq_n_f32(0); for (size_t i = 0; i < n; i+=4) { a = vld1q_f32(p1 + i); b = vld1q_f32(p2 + i); c = vaddq_f32(c, vmulq_f32(a, b)); } vst1q_f32(sum, c); return (sum[0]+sum[1]+sum[2]+sum[3]); #else std::cerr << "NEON is not supported" << std::endl; return 0.0; #endif } float dotproduct_neon_omp(const float *p1, const float * p2, size_t n) { #ifdef WITH_NEON if(n % 4 != 0) { std::cerr << "The size n must be a multiple of 4." <<std::endl; return 0.0f; } float sum[4] = {0}; float32x4_t a, b; float32x4_t c = vdupq_n_f32(0); #pragma omp parallel for for (size_t i = 0; i < n; i+=4) { a = vld1q_f32(p1 + i); b = vld1q_f32(p2 + i); c = vaddq_f32(c, vmulq_f32(a, b)); } vst1q_f32(sum, c); return (sum[0]+sum[1]+sum[2]+sum[3]); #else std::cerr << "NEON is not supported" << std::endl; return 0.0; #endif } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
cpp里定义了一些宏,是在CMakeList定义的
CMakeList.txt
cmake_minimum_required(VERSION 3.12) add_definitions(-DWITH_NEON) #add_definitions(-DWITH_AVX2) set(CMAKE_CXX_STANDARD 11) project(dotp) ADD_EXECUTABLE(dotp main.cpp matoperation.cpp) find_package(OpenMP) if(OpenMP_CXX_FOUND) message("OpenMP found.") target_link_libraries(dotp PUBLIC OpenMP::OpenMP_CXX) endif()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
main.cpp
#include#include #include #include "matoperation.hpp" using namespace std; #define TIME_START start=std::chrono::steady_clock::now(); #define TIME_END(NAME) end=std::chrono::steady_clock::now(); \ duration=std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count();\ cout<<(NAME)<<": result="<<result \ <<", duration = "<<duration<<"ms"<<endl; int main(int argc, char ** argv) { size_t nSize = 200000000; float * p1 = new float[nSize](); //the memory is not aligned float * p2 = new float[nSize](); //the memory is not aligned // // 256bits aligned, C++17 standard // float * p1 = static_cast - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
mkdir build cd build cmake .. make- 1
- 2
- 3
- 4
normal: result=9.1, duration = 706ms unloop: result=9.1, duration = 697ms SIMD: result=9.1, duration = 348ms SIMD+OpenMP: result=9.1, duration = 347ms- 1
- 2
- 3
- 4
多线程写同一个数据,造成数据冲突了
4-Avoid Memory Copy
What’s an image

彩色:有三个这样的矩阵
ccv::Mat class

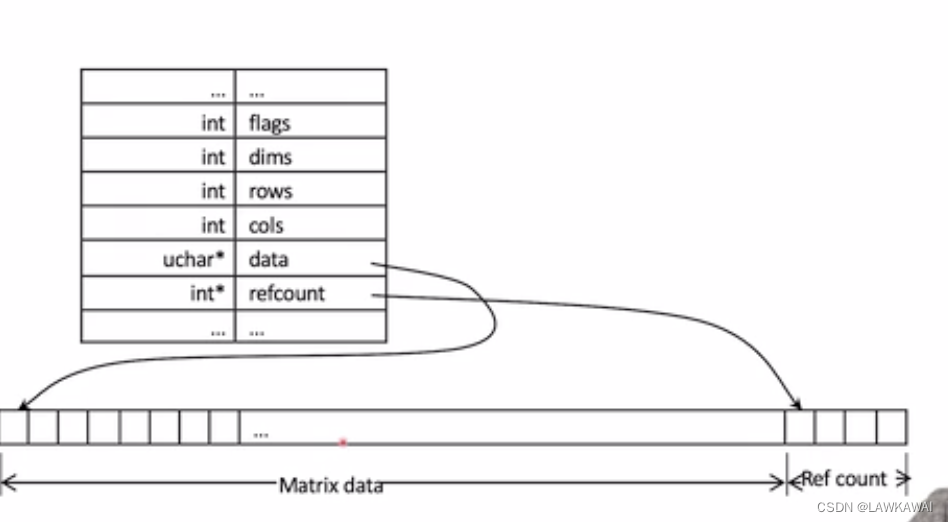
Ref count 用来记录还剩多少个指针没有被释放,如果为0,说明所有指针都被释放了
step in. cv::Mat
- How many bytes for a row of Matrix 4(row) x 3(col)?
- Can be 3, ,4, 8, and any other values >= 3
- Memory alignment for SIMD
ROI: Region of Interest

扣一个小矩阵,可以直接指向小矩阵的起始位置
-
相关阅读:
第四次作业
1024程序员节背后的秘密:1024程序员节的前世今生
hexo搭建一个自己的博客
电脑重装系统打印机脱机状态怎么恢复正常
【QT小记】QT中信号和槽的基本使用
Python二级题:MOOC学校名单|关键词提取和查找
Py之tiktoken:tiktoken的简介、安装、使用方法之详细攻略
java图片压缩库调研
[项目管理-29]:SMART项目计划制定与PDCA闭环监控,珠联璧合,双剑合一。
力扣labuladong——一刷day34
- 原文地址:https://blog.csdn.net/weixin_38362786/article/details/134022038
