-
网络爬虫——urllib(4)文末好书推荐
前言🍭
❤️❤️❤️网络爬虫专栏更新中,各位大佬觉得写得不错,支持一下,感谢了!❤️❤️❤️
上篇我们讲解了百度详细翻译这个案例,这篇同样也是进行案例讲解。
9.ajax的get请求🍉
Ⅰ、ajax的get请求请求豆瓣电影第一页🍓
我们打开豆瓣电影,随便打开一个排行榜(电影->剧情)

我们F12,打开开发者工具
打开第一个接口,可以看到只有网页,没有数据,我们继续找

找到下面这个,发现了“肖申克的救赎” ,但是这个只有一个数据啊,继续找

我们又找到一个,有20个数据(都是json格式的,因为它给我们返回的就是json数据,前后端分离),我们打开来看看

前面两个是 肖申克的救赎 和 霸王别姬
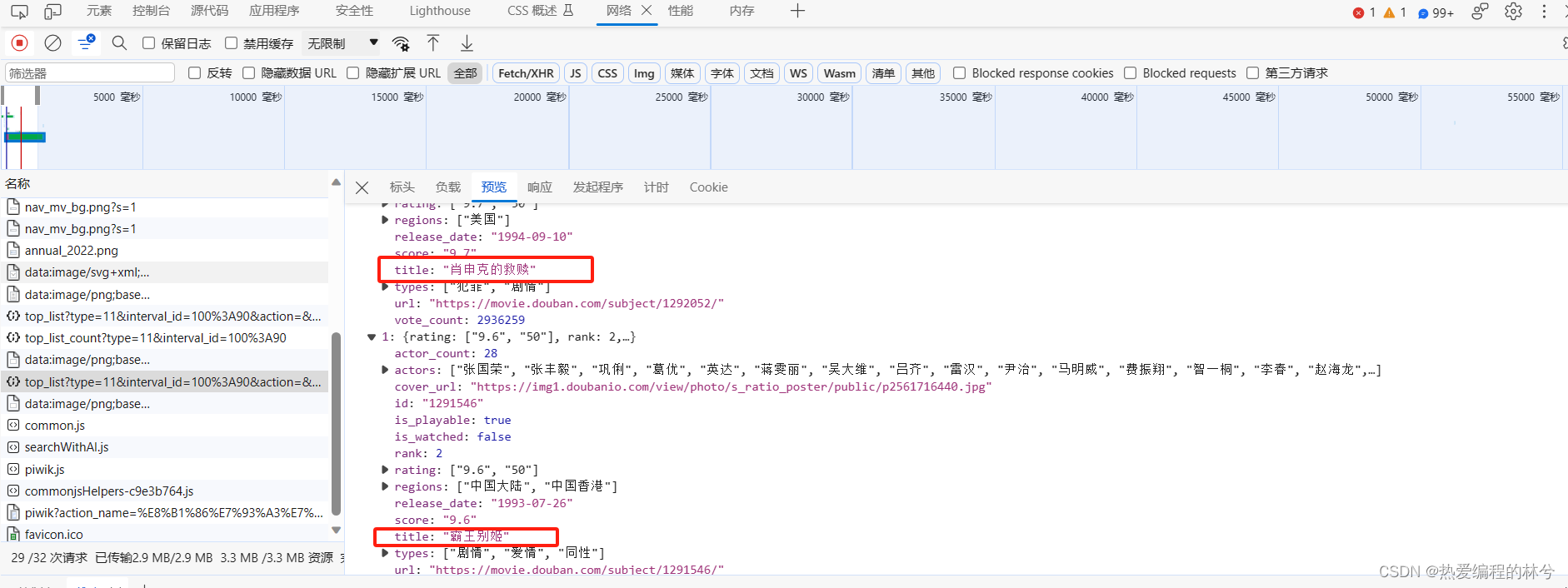
最后一个(第二十个)是 海上钢琴师

果然 第二十部电影是 海上钢琴师

这个接口就是我们想要的数据,好下面我们来写代码:

这是get请求,我们就按get请求来做。
- # get请求
- # 获取豆瓣电影的第一页的数据 并且保存起来
- import urllib.request
- # header中的url
- url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20'
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
- }
- # (1) 请求对象的定制
- request = urllib.request.Request(url=url, headers=headers)
- # (2)获取响应的数据
- response = urllib.request.urlopen(request)
- content = response.read().decode('utf-8')
- print(content)
我们先打印出来,看看有什么问题

好像没问题,我们继续写代码,我们将json数据下载下来:
- # get请求
- # 获取豆瓣电影的第一页的数据 并且保存起来
- import urllib.request
- # header中的url
- url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20'
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
- }
- # (1) 请求对象的定制
- request = urllib.request.Request(url=url, headers=headers)
- # (2)获取响应的数据
- response = urllib.request.urlopen(request)
- content = response.read().decode('utf-8')
- # print(content)
- # (3) 数据下载到本地
- # open方法默认情况下使用的是gbk的编码 如果我们要想保存汉字 那么需要在open方法中指定编码格式为utf-8
- with open('douban1.json', 'w', encoding='utf-8') as fp:
- fp.write(content)
运行代码,然后就下载好了,我们将前20条数据下载好了:

下面我们来下载豆瓣电影的前十页
Ⅱ、ajax的get请求请求豆瓣电影前十页🍓
我们在上面知道了,豆瓣电影中一组数据有20部电影,我们继续往下滑,它还有第21部,22部电影
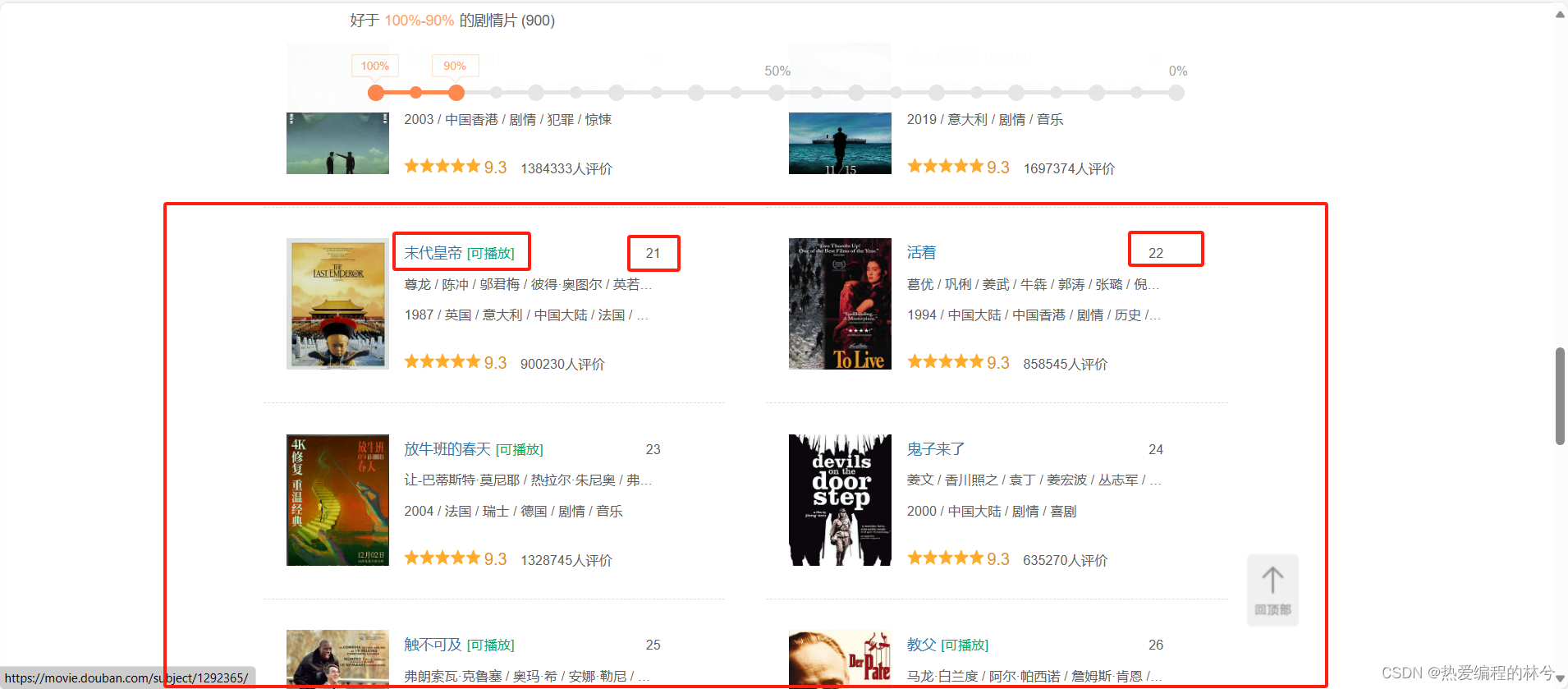
同样的我们去 开发者工具中找到第二组数据:
 同样的我们去找第三组第四组数据:
同样的我们去找第三组第四组数据:- # https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20
- # https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=20&limit=20
- # https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=40&limit=20
- # https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=60&limit=20
然后去观察规律
我们发现只有start的键值对 的值不一样,很明显可以看出start值是(page-1)*20
从这里我们就找到了start和page的关系
下面我们来写代码
- # https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=0&limit=20
- # https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=20&limit=20
- # https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=40&limit=20
- # https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=60&limit=20
- # start (page - 1)*20
- import urllib.parse
- import urllib.request
- def create_request(page):
- base_url = 'https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&'
- data = {
- 'start': (page - 1) * 20,
- 'limit': 20
- }
- data = urllib.parse.urlencode(data)
- url = base_url + data
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
- }
- request = urllib.request.Request(url=url, headers=headers)
- return request
- def get_content(request):
- response = urllib.request.urlopen(request)
- content = response.read().decode('utf-8')
- return content
- # page强制类型转换 否则拼接不上
- def down_load(page, content):
- with open('douban_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
- fp.write(content)
- # 程序的入口
- if __name__ == '__main__':
- start_page = int(input('请输入起始的页码'))
- end_page = int(input('请输入结束的页面'))
- for page in range(start_page, end_page + 1):
- # 每一页都有自己的请求对象的定制
- request = create_request(page)
- # 获取响应的数据
- content = get_content(request)
- # 下载
- down_load(page, content)
运行代码我们就将前十页json数据都下载好了

10.ajax的post请求 🍉
下面我们来爬取一下KFC,查看一下北京这个城市哪个位置有KFC,并且保存数据。

可以看到这里有很多KFC店

我们查看url,同时也可以看到这是POST请求

一样的,我们观察不同页数的url区别
- # 1页
- # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
- # post
- 表单数据
- # cname: 北京
- # pid:
- # pageIndex: 1
- # pageSize: 10
- # 2页
- # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
- # post
- 表单数据
- # cname: 北京
- # pid:
- # pageIndex: 2
- # pageSize: 10
下面我们来写代码,去爬取北京KFC位置信息
- # 1页
- # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
- # post
- # cname: 北京
- # pid:
- # pageIndex: 1
- # pageSize: 10
- # 2页
- # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
- # post
- # cname: 北京
- # pid:
- # pageIndex: 2
- # pageSize: 10
- import urllib.request
- import urllib.parse
- def create_request(page):
- base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
- data = {
- 'cname': '北京',
- 'pid': '',
- 'pageIndex': page,
- 'pageSize': '10'
- }
- data = urllib.parse.urlencode(data).encode('utf-8')
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
- }
- request = urllib.request.Request(url=base_url, headers=headers, data=data)
- return request
- def get_content(request):
- response = urllib.request.urlopen(request)
- content = response.read().decode('utf-8')
- return content
- def down_load(page, content):
- with open('kfc_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
- fp.write(content)
- if __name__ == '__main__':
- start_page = int(input('请输入起始页码'))
- end_page = int(input('请输入结束页码'))
- for page in range(start_page, end_page + 1):
- # 请求对象的定制
- request = create_request(page)
- # 获取网页源码
- content = get_content(request)
- # 下载
- down_load(page, content)
运行代码,我们就爬取好了,数据也能对上

好书推荐:ChatGPT进阶:提示工程入门
爆火全网的原创提示词设计框架BROKE,带你5步掌握向人工智能提问的艺术,从小白变身ChatGPT应用专家,将AI转化为生产工具,重塑你的工作流!

内容简介
本书是一本面向所有人的提示工程工具书,旨在帮助你掌握并有效利用以ChatGPT为代表的AI工具。学习完本书后,你将能够自如地将ChatGPT运用在生活和专业领域中,成为ChatGPT进阶玩家。
本书共分为9章,内容涵盖三个层次:介绍与解读、入门学习、进阶提升。第1~2章深入介绍与剖析了ChatGPT与提示工程,并从多个学科的角度探讨了提示工程学科。第3~5章演示了ChatGPT的实际运用,教你如何使用ChatGPT解决自然语言处理问题,并为你提供了一套可操作、可重复的提示设计框架,让你能够熟练驾驭ChatGPT。第6~9章讲解了来自学术界的提示工程方法,以及如何围绕ChatGPT进行创新;此外,为希望ChatGPT进行应用开发的读者提供了实用的参考资料,并介绍了除ChatGPT之外的其他选择。
本书聚焦ChatGPT的实际应用,可操作,可重复,轻松易读却不失深度。无论你是对ChatGPT及类似工具充满好奇,还是期待将其转化为生产力,本书都值得一读。此外,本书还可作为相关培训机构的教材。
购买链接
京东购买链接:https://item.jd.com/14098844.html
当当购买链接:http://product.dangdang.com/29612772.html
参与方式
关注博主、点赞、收藏、评论区任意评论(评论折叠无效)
即可参与送书活动!
开奖时间:2023-10-28 21:00:00

-
相关阅读:
C#WPF属性触发器实例
QT:文件介绍
web安全学习笔记(11)
.NET Core使用NPOI导出复杂,美观的Excel详解
Flutter SQLite 教程之笔记App 数据存储CRUD操作基于 Flutter Sqflite 插件
不使用canvas怎么实现一个刮刮卡效果?
Docker安装superset
【无标题】
如何做架构设计?
图片操作笔记-滤波-python
- 原文地址:https://blog.csdn.net/m0_63951142/article/details/134013573
