-
MFC+OSG(Open Secene Graph)场景实现中文HUD(head up display)效果,防止中文乱码
MFC+OSG(Open Secene Graph)场景实现中文HUD(head up display)效果,防止中文乱码
背景:为什么同时使用MFC和OSG
我建立了一个MFC工程,以OSG作为视图显示的基础,通过点击MFC菜单启动某些功能。因此,在工程中包含了OSG库。并且,为了使生成的exe在Windows下能正常处理中文路径,使用**多字节字符集(ANSI)**作为编码方式。因此,程序中并不会使用
L()宏来定义Unicode字符串,也不会使用wchar等宽字符类型,而是所有字符串都用一样的写法,比如:const char* pHUDText="我爱你中国";- 1
如果不考虑OSG,这种写法完全没有问题,运行MFC程序、使用MFC对话框显示和读取中文输入都是正常工作的。
但是,我的工程中还引入了OSG库,这个库仅支持utf-8的字符串显示。所以我必须将要输入OSG显示的中文字符串转换成utf-8编码格式。为了完成这件事,进行了下面几种尝试:-
MSVC项目属性中加入 /execution-charset:utf-8
操作如下图所示:
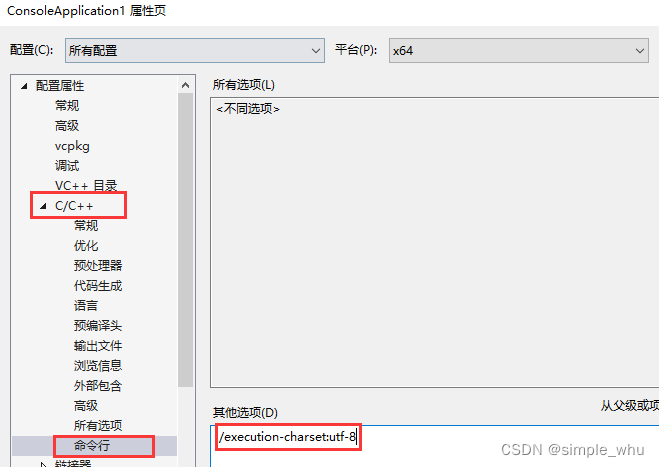
代码中仍使用正常的字符串写法。 -
使用u8字符串
-
使用函数将字符串转到utf-8编码(使用支持C++11的编译器时,完全可以由方法2替代)。定义如下:
#include//WideCharToMultiByte定义在这里 void unicodeToUTF8(const std::wstring &src, std::string& result) { int n = WideCharToMultiByte( CP_UTF8, 0, src.c_str(), -1, 0, 0, 0, 0 ); result.resize(n); ::WideCharToMultiByte( CP_UTF8, 0, src.c_str(), -1, (char*)result.c_str(), result.length(), 0, 0 ); } void gb2312ToUnicode(const std::string& src, std::wstring& result) { int n = MultiByteToWideChar( CP_ACP, 0, src.c_str(), -1, NULL, 0 ); result.resize(n); ::MultiByteToWideChar( CP_ACP, 0, src.c_str(), -1, (LPWSTR)result.c_str(), result.length()); } void gb2312toUTF8(const std::string& src, std::string& result) { std::wstring strWideChar; gb2312ToUnicode(src, strWideChar); unicodeToUTF8(strWideChar, result); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
其中CP_ACP就是指当前代码页。CP_UTF8指的是65001(utf-8)代码页。
gb2312toUTF8的第一个参数是传入的待转换字符串,第二个参数是结果字符串。详解三种使字符串能在OSG中显示的方法
/execution-charset:utf-8 设置程序执行时的编码为utf-8
即程序源码中的字符串编译后在可执行程序或库中的编码方式都由此选项控制。如果一个MSVC项目在命令行加入了这一项,则程序中的所有字符串都会按照utf-8编码存储。
u8字符串字面量
使用u8字符串字面量仅对当前字符串的编码指定为utf-8存储。即,如果程序本身是按系统的ANSI编码正常工作,设置u8字符串字面量
示例:#includeint main() { std::cout << u8"大家好"; } - 1
- 2
- 3
- 4
- 5
- 6
在这段代码中,编译器会将"大家好"三个汉字按照utf-8编码存进生成的.exe程序中。执行程序时,按照Windows系统默认代码页(ANSI,936)从.exe中读取这段字符数据,并输出到命令行。这当然会乱码啦!如图所示:

但是,如果你打开命令行后,将命令行的代码页切换到utf-8,再运行这个程序,则会输出正确的结果。如下图所示:
GB2312toUTF8函数
通过WINAPI将字符串从默认代码页ANSI转到Unicode,再从Unicode转到utf-8。
总结
像我的应用场景,MFC+OSG场景显示,MFC程序中的字符读取都还是按ANSI编码,仅仅将输入OSG的字符串转换为utf-8编码,所以不适合采用第一种策略(将所有字符串都以utf-8编码存储)。第二种方法和第三种方法是等价的,且在编译器支持u8字符串字面量时更推荐第二种方法,简洁又省事。
如果已经在C/C+±命令行中加入了/execution-charset:utf-8,但是在程序中又同时使用了GB2312toUTF8函数将字符串转换,则又会导致乱码。例如:
int main() { std::string str, str1, str2; str1 = "大家好!\n"; str2 = u8"大家好!\n"; gb2312ToUtf8(str1, str); std::cout << str; std::cout << str1; std::cout << str2; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在65001代码页中的运行结果为:

可见,这三种方式只使用其中一种即可,u8和/execution-charset:utf-8不冲突,而gb2312ToUtf8和/execution-charset:utf-8同时使用是不行的。 -
相关阅读:
leetcode:968. 监控二叉树【树状dp,维护每个节点子树的三个状态,非常难想权当学习,类比打家劫舍3】
OSN 1800 II TP机盒华为全新一代光层机盒
springboot基础
Android --- 异步操作
leetcode (力扣) 201. 数字范围按位与 (位运算)
跳表与红黑树
英国最值得参观的十大博物馆介绍
#经典论文 异质山坡的物理模型 2 有效导水率
Ubuntu使用GParted增加swap分区后无法休眠解决办法
jvm dump日志设置
- 原文地址:https://blog.csdn.net/qq_42679415/article/details/133233761
