-
大数据技术学习笔记(三)—— Hadoop 的运行模式
Hadoop运行模式包括:
1 本地模式
官方 wordcount (统计单词的个数)示例:
- 创建在
hadoop-3.1.3文件下面创建一个wcinput文件夹
[huwei@hadoop101 hadoop-3.1.3]$ mkdir wcinput- 1
- 在
wcinput文件下创建一个word.txt文件并编辑内容
[huwei@hadoop101 hadoop-3.1.3]$ cd wcinput [huwei@hadoop101 wcinput]$ vim word.txt- 1
- 2
在文件中输入如下内容
hadoop yarn hadoop mapreduce huwei huwei- 1
- 2
- 3
- 4
保存退出
:wq- 执行程序
[huwei@hadoop101 wcinput]$ cd /opt/module/hadoop-3.1.3 [huwei@hadoop101 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput- 1
- 2
输出文件夹
wcoutput不需要提前创建- 查看结果
[huwei@hadoop101 hadoop-3.1.3]$ ll [huwei@hadoop101 hadoop-3.1.3]$ cd wcoutput/- 1
- 2

[huwei@hadoop101 wcoutput]$ cat part-r-00000- 1

2 伪分布式模式
可参考笔者之前写的博客 Centos6下安装伪分布式hadoop
3 完全分布式模式
3.1 准备3台客户机
由笔者上一篇博客 大数据技术学习笔记(二)—— Hadoop运行环境的搭建 可知,我们已由模版机hadoop100 克隆了 hadoop101,并在hadoop101成功安装配置了 jdk 和 hadoop。
现在,我们再由模版机 hadoop100 创建克隆 hadoop102、hadoop103,我们对这两台新克隆的机器同样进行 修改IP地址、修改主机名 操作。(仍可参考上一篇博客中对 hadoop101 的修改)
3.2 同步分发内容
我们已经在hadoop101成功安装配置了 jdk 和 hadoop,为避免再次在 hadoop102、hadoop103安装配置 jdk 和 hadoop带来的麻烦,我们可以通过将 hadoop101 安装配置的 jdk 和 hadoop同步分发给hadoop102、hadoop103的方式,简化操作步骤。
3.2.1 分发命令
scp
scp(secure copy)安全拷贝,scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)。
基本语法
scp -r $pdir/$fname $user@hadoop$host:$pdir/$fname 命令 递归 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称- 1
- 2
rsync
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。基本语法
rsync -av $pdir/$fname $user@hadoop$host:$pdir/$fname 命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称- 1
- 2
选项参数说明
- -a 归档拷贝
- -v 显示复制过程
- 编写集群分发脚本
xsync
说明:在
/home/huwei/bin这个目录下存放的脚本,huwei用户可以在系统任何地方直接执行。在
/home/huwei/bin目录下创建xsync文件[huwei@hadoop101 ~]$ cd /home/huwei [huwei@hadoop101 ~]$ mkdir bin [huwei@hadoop101 ~]$ cd bin [huwei@hadoop101 bin]$ vim xsync- 1
- 2
- 3
- 4
在该文件中编写如下代码
fi #!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop101 hadoop102 hadoop103 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
修改脚本
xsync具有执行权限[huwei@hadoop101 bin]$ chmod +x xsync- 1
将脚本复制到
/bin中,以便全局调用[huwei@hadoop101 bin]$ sudo cp xsync /bin/- 1
测试脚本(将
/home/huwei/bin分发给其他机器)[huwei@hadoop101 ~] xsync /home/huwei/bin- 1
3.2.2 执行分发操作
将 hadoop101 安装配置的 jdk 和 hadoop 同步分发给 hadoop102
[huwei@hadoop101 ~]$ scp -r /opt/module/* huwei@hadoop102:/opt/module/- 1

注意,两台主机首次通信时需要确认,键入
yes,后续通信则不需要为 拓展 scp 的用法,我们尝试在 hadoop103上向 hadoop101上主动拉取 jdk
[huwei@hadoop103 ~]$ scp -r huwei@hadoop101:/opt/module/jdk1.8.0_212 /opt/module/- 1
在 hadoop102 上将 hadoop101 的 hadoop 发送给 hadoop103(该操作
rsync不支持)[huwei@hadoop102 ~]$ scp -r huwei@hadoop101:/opt/module/hadoop-3.1.3 huwei@hadoop103:/opt/module/- 1
此时,hadoop102、hadoop103 上都有了 jdk 和 hadoop,下面需要将 jdk 和 hadoop 的环境变量也分发过去。
此时注意要使用 scp 将环境变量分发给 hadoop102、hadoop103时,hadoop102、hadoop103必须要 root 用户登录,因为只有 root 用户才有在
/etc/profile.d文件夹下写的权限[huwei@hadoop101 ~]$ cd /etc/profile.d [huwei@hadoop101 profile.d]$ scp -r ./my_env.sh root@hadoop102:/etc/profile.d/ [huwei@hadoop101 profile.d]$ scp -r ./my_env.sh root@hadoop103:/etc/profile.d/- 1
- 2
- 3
使得 hadoop102、hadoop103下的环境变量生效
[huwei@hadoop102 ~]$ source /etc/profile [huwei@hadoop103 ~]$ source /etc/profile- 1
- 2
然后可分别在 hadoop102、hadoop103下进行测试,
java -version、hadoop version3.3 集群配置
3.3.1 集群部署规划
注意:
NameNode和SecondaryNameNode不要安装在同一台服务器ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。

3.3.2 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。当Hadoop集群启动后,先加载默认配置,然后再加载自定义配置文件,自定义的配置信息会覆盖默认配置。
hadoop 的默认配置文件
core-default.xmlhdfs-default.xmlmapread-default.xmlyarn-default.xml
hadoop提供可自定义的配置文件
core-site.xmlhdfs-site.xmlmapread-site.xmlyarn-site.xml
常用的端口号说明

3.3.3 修改配置文件
- 核心配置文件
[huwei@hadoop101 ~]$ cd $HADOOP_HOME/etc/hadoop [huwei@hadoop101 hadoop]$ vim core-site.xml- 1
- 2
文件内容如下
"1.0" encoding="UTF-8"?> type="text/xsl" href="configuration.xsl"?><!-- 指定NameNode的地址 --> fs.defaultFS</name> hdfs://hadoop101:9820</value> </property> <!-- 指定hadoop数据的存储目录 --> hadoop.tmp.dir</name> /opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为huwei --> hadoop.http.staticuser.user</name> huwei</value> </property> <!-- 配置该huwei(superUser)允许通过代理访问的主机节点 --> hadoop.proxyuser.huwei.hosts</name> *</value> </property> <!-- 配置该huwei(superUser)允许通过代理用户所属组 --> hadoop.proxyuser.huwei.groups</name> *</value> </property> <!-- 配置该huwei(superUser)允许通过代理的用户--> hadoop.proxyuser.huwei.groups</name> *</value> </property> </configuration> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- HDFS配置文件
[huwei@hadoop101 hadoop]$ vim hdfs-site.xml- 1
文件内容如下
"1.0" encoding="UTF-8"?> type="text/xsl" href="configuration.xsl"?><!-- nn web端访问地址--> dfs.namenode.http-address</name> hadoop101:9870</value> </property> <!-- 2nn web端访问地址--> dfs.namenode.secondary.http-address</name> hadoop103:9868</value> </property> </configuration> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- YARN配置文件
[huwei@hadoop101 hadoop]$ vim yarn-site.xml- 1
文件内容如下
"1.0" encoding="UTF-8"?> type="text/xsl" href="configuration.xsl"?><!-- 指定MR走shuffle --> yarn.nodemanager.aux-services</name> mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> yarn.resourcemanager.hostname</name> hadoop102</value> </property> <!-- 环境变量的继承 --> yarn.nodemanager.env-whitelist</name> JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- yarn容器允许分配的最大最小内存 --> yarn.scheduler.minimum-allocation-mb</name> 512</value> </property> yarn.scheduler.maximum-allocation-mb</name> 4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> yarn.nodemanager.resource.memory-mb</name> 4096</value> </property> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> yarn.nodemanager.pmem-check-enabled</name> false</value> </property> yarn.nodemanager.vmem-check-enabled</name> false</value> </property> </configuration> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- MapReduce配置文件
[huwei@hadoop101 hadoop]$ vim mapred-site.xml- 1
文件内容如下
"1.0" encoding="UTF-8"?> type="text/xsl" href="configuration.xsl"?><!-- 指定MapReduce程序运行在Yarn上 --> mapreduce.framework.name</name> yarn</value> </property> </configuration> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.3.4 分发配置信息
[huwei@hadoop101 ~]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/- 1
3.3.5 集群所有进程查看脚本
(1)在/home/huwei/bin 下创建 xcall.sh
[huwei@hadoop101 bin]$ vim xcall.sh- 1
(2)在脚本中编写如下内容
#! /bin/bash for i in hadoop101 hadoop102 hadoop103 do echo --------- $i ---------- ssh $i "$*" done- 1
- 2
- 3
- 4
- 5
- 6
- 7
(3)修改脚本执行权限
[huwei@hadoop101 bin]$ chmod u+x xcall.sh- 1
(4)执行脚本
[huwei@hadoop101 bin]$ xcall.sh jps- 1
3.4 SSH无密登录配置
3.4.1 配置ssh
ssh 基本语法
ssh 另一台主机的主机名/ip地址- 1
例如,我们在 hadoop101 上登录 hadoop102,可以看到我们必须输入hadoop102的登录密码

输入
exit登出我们在操作的过程中,少不了各台机器之间的通信,如果总是输入密码会很麻烦,所以我们要进行免密配置
3.4.2 无密钥配置
- 免密登录原理

- 生成公钥和私钥
[huwei@hadoop101 ~]$ ssh-keygen -t rsa- 1
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)

查看生成的私钥、公钥的存放位置
[huwei@hadoop101 ~]$ cd /home/huwei/.ssh/ [huwei@hadoop101 .ssh]$ ll- 1
- 2

.ssh文件夹下(~/.ssh)的文件功能解释

- 将公钥拷贝到要免密登录的目标机器上(授权)
[huwei@hadoop101 .ssh]$ ssh-copy-id hadoop101 [huwei@hadoop101 .ssh]$ ssh-copy-id hadoop102 [huwei@hadoop101 .ssh]$ ssh-copy-id hadoop103- 1
- 2
- 3
以上步骤 2、3 的工作,也要在 hadoop102、hadoop103 走一遍。
此时,三台主机两两之间即可实现免密登录。
3.5 单点启动集群
3.5.1 启动 HDFS 集群
- 格式化

如果集群是第一次启动,才需要在hadoop101 节点 格式化 NameNode(注意格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的
data和logs目录,然后再进行格式化。)[huwei@hadoop101 hadoop-3.1.3]$ hdfs namenode -format- 1

- 启动 namenode
hadoop101 启动 namenode
hdfs --daemon start namenode- 1
使用
jps命令查看当前进程
Web 端查看 HDFS 的 NameNode- 浏览器中输入:
http://hadoop101:9870 - 查看HDFS上存储的数据信息

- 启动 datanode
hadoop101 hadoop102 hadoop103 分别启动 datanode
[huwei@hadoop101 ~]$ hdfs --daemon start datanode [huwei@hadoop102 ~]$ hdfs --daemon start datanode [huwei@hadoop103 ~]$ hdfs --daemon start datanode- 1
- 2
- 3



此时查看 web 端
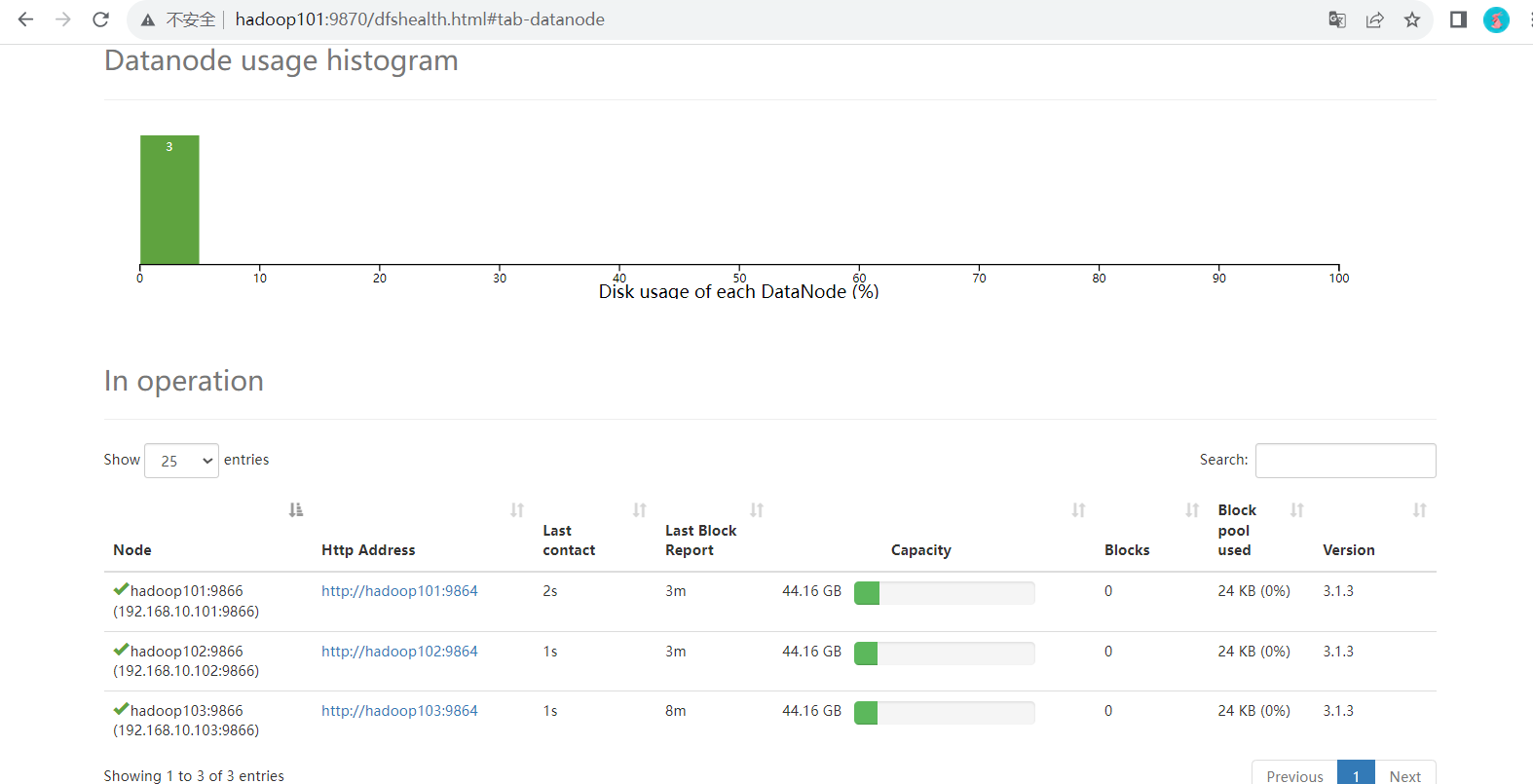
- 启动 secondarynamenode
hadoop103 启动secondarynamenode
[huwei@hadoop103 ~]$ hdfs --daemon start secondarynamenode- 1
jps查看进程
Web端查看 HDFS 的 secondarynamenode(并没有什么东东)
- 浏览器中输入:
http://hadoop103:9868
3.5.2 启动 YARN 集群
- 启动 resourcemanager
hadoop102 启动 resourcemanager
[huwei@hadoop102 ~]$ yarn --daemon start resourcemanager- 1
- 启动 nodemanager
hadoop101、 hadoop102、 hadoop103 分别启动 nodemanager
[huwei@hadoop101 ~]$ yarn --daemon start nodemanager [huwei@hadoop102 ~]$ yarn --daemon start nodemanager [huwei@hadoop103 ~]$ yarn --daemon start nodemanager- 1
- 2
- 3
Web端查看YARN的ResourceManager
- 浏览器中输入:
http://hadoop102:8088 - 查看YARN上运行的Job信息

jps查看各主机上的进程
关于关闭集群,同上述启动集群的命令,只需将
start修改为stop即可3.6 群起集群
3.6.1 配置workers
当执行群启/群停脚本的时候,首先会解析
etc/hadoop/workers,解析到的内容都是每一台机器的地址,脚本会自动执行在每一台机器上启动 dn、nm。[huwei@hadoop101 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers- 1
在该文件中增加如下内容
hadoop101 hadoop102 hadoop103- 1
- 2
- 3
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[huwei@hadoop101 ~]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/workers- 1
3.6.2 启动集群
- 启动 HDFS
在配置了
NameNode的节点(hadoop101)启动HDFS[huwei@hadoop101 ~]$ start-dfs.sh- 1
- 启动 YARN
在配置了
ResourceManager的节点(hadoop102)启动YARN[huwei@hadoop102 ~]$ start-yarn.sh- 1
注意:
- 关闭集群同上述命令,只需将
start修改为stop即可 - hadoop本身也给我们提供了
start-all.sh可以实现一次性启动HDFS和YARN,但是这个命令也会额外的启动别的进程,这样会比较耗费服务器资源。
3.6.3 测试集群
在HDFS的web 界面打开HDFS的文件系统
在HDFS文件系统中手动创建
wcinput文件夹,并在wcinput文件夹下手动上传hello.txt文件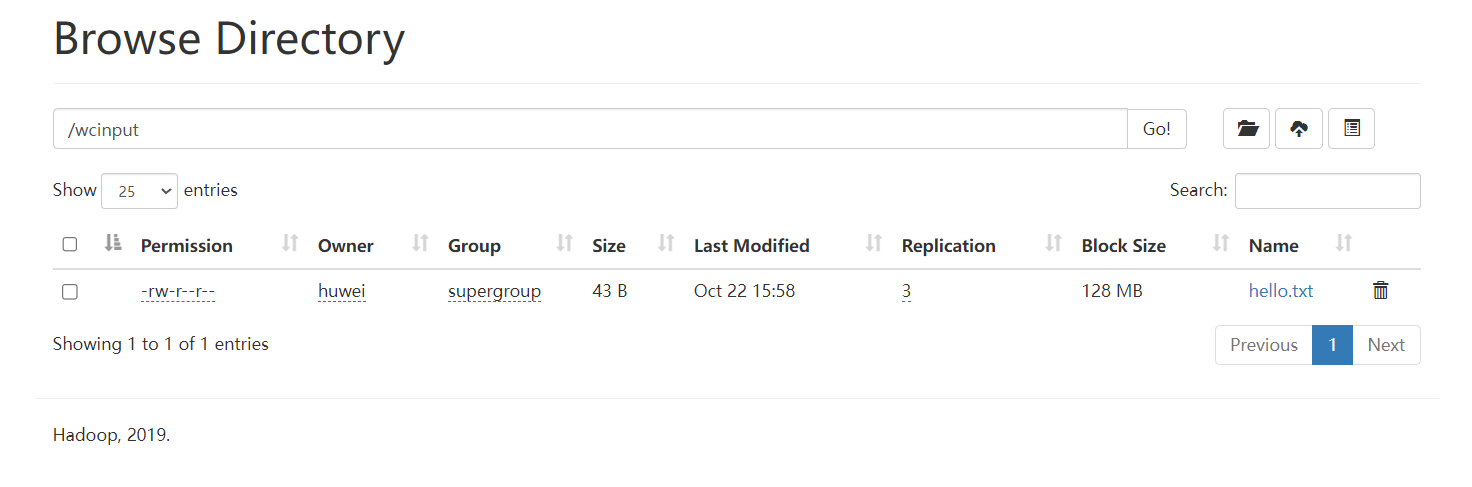
执行 wordcount 程序[huwei@hadoop101 ~]$ cd /opt/module/hadoop-3.1.3 [huwei@hadoop101 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput- 1
- 2
可以看到

3.7 自定义群起集群脚本
进入用户家目录的 bin 目录中,创建群起 Hadoop 集群的脚本,并为其赋予执行权限
[huwei@hadoop101 ~]$ pwd /home/huwei [huwei@hadoop101 ~]$ cd bin [huwei@hadoop101 bin]$ touch hdp_cluster.sh [huwei@hadoop101 bin]$ chmod 744 hdp_cluster.sh- 1
- 2
- 3
- 4
- 5
编写脚本内容
在这里插入代码片- 1
#!/bin/bash #参数校验 if [ $# -lt 1 ] then echo "参数不能为空!!!" exit fi #根据参数的值进行 启停 操作 case $1 in "start") #启动操作 echo "===============start HDFS=================" ssh hadoop101 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh echo "===============start YARN=================" ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh ;; "stop") #停止操作 echo "===============stop HDFS=================" ssh hadoop101 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh echo "===============stop YARN=================" ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh ;; *) echo "ERROR!!!!" ;; esac- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
群起集群
[huwei@hadoop101 ~]$ hdp_cluster.sh start- 1
停止集群
[huwei@hadoop101 ~]$ hdp_cluster.sh stop- 1
3.8 配置历史服务器
历史服务器是针对MR程序执行的历史记录,当集群关闭重启后,Web端查看YARN,找不到程序执行的历史记录了,为了查看程序的历史运行情况,需要配置一下历史服务器。
[huwei@hadoop101 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml- 1
在该文件里面增加如下配置
<!-- 历史服务器端地址(哪台主机都可) -->mapreduce.jobhistory.address</name> hadoop101:10020</value> </property> <!-- 历史服务器web端地址 --> mapreduce.jobhistory.webapp.address</name> hadoop101:19888</value> </property> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
分发配置
[huwei@hadoop101 ~]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml- 1
在hadoop101 启动历史服务器
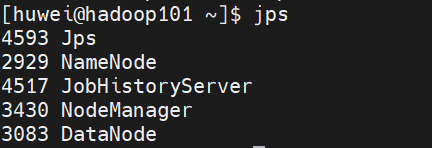
[huwei@hadoop101 ~]$ mapred --daemon start historyserver- 1
查看历史服务器是否启动
web 端查看 JobHistory
- 浏览器中输入:
http://hadoop101:19888/jobhistory
3.9 配置日志的聚集
日志是针对 MR 程序运行是所产生的的日志,配置日志的聚集方便后期分析问题有更好的执行过过程的依据。
应用运行完成以后,将程序运行日志信息上传到HDFS系统上。配置日志聚集可以方便的查看到程序运行详情,方便开发调试。
[huwei@hadoop101 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml- 1
在该文件里面增加如下配置
<!-- 开启日志聚集功能 -->yarn.log-aggregation-enable</name> true</value> </property> <!-- 设置日志聚集服务器地址 --> yarn.log.server.url</name> http://hadoop101:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> yarn.log-aggregation.retain-seconds</name> 604800</value> </property> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意:开启日志聚集功能,需要重新启动
NodeManager、ResourceManager和HistoryServer。分发配置
[huwei@hadoop101 ~]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml- 1
关闭 NodeManager 、ResourceManager和HistoryServer
[huwei@hadoop102 ~]$ stop-yarn.sh [huwei@hadoop101 ~]$ mapred --daemon stop historyserver- 1
- 2
开启 NodeManager 、ResourceManager和HistoryServer
[huwei@hadoop102 ~]$ start-yarn.sh [huwei@hadoop101 ~]$ mapred --daemon start historyserver- 1
- 2
现在去看 HistoryServer

此时仍然看不到日志是怎么回事呢? 其实是因为我们当时执行程序的时候并没有开启日志聚集,现在我们开启了日志聚集功能,那么重新执行程序
删除HDFS上已经存在的输出文件
[huwei@hadoop101 ~]$ hadoop fs -rm -r /wcoutput- 1
执行WordCount程序
[huwei@hadoop101 wcinput]$ cd /opt/module/hadoop-3.1.3 [huwei@hadoop101 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput- 1
- 2
现在去看 HistoryServer ,可以看到日志了。

- 创建在
-
相关阅读:
系统架构基础知识入门——架构初探
Ubuntu20 QT6.0 编译 ODBC 驱动
动态规划:01背包问题+3道子序列问题困难题
ROS2系列知识(4): 理解【服务】的概念
Java SpringMVC开发前的准备工作
基于python的校园社团管理系统的设计与实现
MySQL数据库用户管理
Blackfly S USB3工业相机:缓冲区处理
超详细全面 spring 复习总结笔记
老卫带你学---leetcode刷题(215. 数组中的第K个最大元素)
- 原文地址:https://blog.csdn.net/hu_wei123/article/details/133966241
