-
面试二总结
缓存穿透,缓存击穿和缓存雪崩
缓存穿透
-
对空值进行缓存
类似于上面的例子,虽然数据库中没有id=-9527的用户的数据,但是在redis中对他进行缓存(key=-9527,value=null),这样当请求到达redis的时候就会直接返回一个null的值给客户端,避免了大量无法访问的数据直接打在DB上。
-
实时监控
对redis进行实时监控,当发现redis中的命中率下降的时候进行原因的排查,配合运维人员对访问对象和访问数据进行分析查询,从而进行黑名单的设置限制服务。
-
使用布隆过滤器
使用BitMap作为布隆过滤器,将目前所有可以访问到的资源通过简单的映射关系放入到布隆过滤器中(哈希计算),当一个请求来临的时候先进行布隆过滤器的判断,如果有那么才进行放行,否则就直接拦截。
-
接口校验
类似于用户权限的拦截,对于id=-3872这些无效访问就直接拦截,不允许这些请求到达Redis、DB上。
缓存雪崩
产生的原因:redis中大量的key集体过期
比如:当redis中的大量key集体过期,可以理解为redis中的大部分数据都被清空了(失效了),那么这时候如果有大量并发的请求来到,那么redis就无法进行有效的响应(命中率急剧下降),请求就都打到DB上了,到时DB直接崩溃。
解决方式:
-
将失效时间分散开
通过使用自动生成随机数使得key的过期时间是随机的,防止集体过期
-
使用多级架构
使用nginx缓存+redis缓存+其他缓存,不同层使用不同的缓存,可靠性更强
-
设置缓存标记
记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际的key
-
使用锁或者队列的方式
如果查不到就加上排它锁,其他请求只能进行等待
缓存击穿
产生的原因:redis中的某个热点key过期,但是此时有大量的用户访问该过期key。
比如:类似于“某明星出轨事件”上了热搜,这时候大量的“粉丝”都在访问该热点事件,但是可能由于某种原因,redis的这个热点key过期了,那么这时候大量高并发对于该key的请求就得不到redis的响应,那么就会将请求直接打在DB服务器上,导致整个DB瘫痪。
解决方式:
-
提前对热点数据进行设置
类似于新闻、某博等软件都需要对热点数据进行预先设置在redis中
-
监控数据,适时调整
监控哪些数据是热门数据,实时的调整key的过期时长
-
使用锁机制
只有一个请求可以获取到互斥锁,然后到DB中将数据查询并返回到Redis,之后所有请求就可以从Redis中得到响应
bean的生命周期:
简单的来说,一个Bean的生命周期分为四个阶段:
1、 实例化(Instantiation)
2、 属性设置(populate)
3、 初始化(Initialization)
4、 销毁(Destruction)

数据库采用行级锁索引(使用排他锁):

mysql事务隔离级别
未提交读(Read uncommitted)是最低的隔离级别。通过名字我们就可以知道,在这种事务隔离级别下,一个事务可以读到另外一个事务未提交的数据。这种隔离级别下会存在幻读、不可重复读和脏读的问题。
提交读(Read committed)也可以翻译成读已提交,通过名字也可以分析出,在一个事务修改数据过程中,如果事务还没提交,其他事务不能读该数据。所以,这种隔离级别是可以避免脏读的发生的。
可重复读(Repeatable reads),由于提交读隔离级别会产生不可重复读的读现象。所以,比提交读更高一个级别的隔离级别就可以解决不可重复读的问题。这种隔离级别就叫可重复读。但是这种隔离级别没办法彻底解决幻读。
可串行化(Serializable)是最高的隔离级别,前面提到的所有的隔离级别都无法解决的幻读,在可序列化的隔离级别中可以解决。
什么是脏读、幻读、不可重复读?
什么是脏读?
脏读又称无效数据的读出,是指在数据库访问中,事务T1将某一值修改,然后事务T2读取该值,此后T1因为某种原因撤销对该值的修改,这就导致了T2所读取到的数据是无效的。
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交(commit)到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
什么是不可重复读?
不可重复读,是指在数据库访问中,一个事务范围内两个相同的查询却返回了不同数据。这是由于查询时系统中其他事务修改的提交而引起的。比如事务T1读取某一数据,事务T2读取并修改了该数据,T1为了对读取值进行检验而再次读取该数据,便得到了不同的结果。
一种更易理解的说法是:在一个事务内,多次读同一个数据。在这个事务还没有结束时,另一个事务也访问该同一数据。那么,在第一个事务的两次读数据之间。由于第二个事务的修改,那么第一个事务读到的数据可能不一样,这样就发生了在一个事务内两次读到的数据是不一样的,因此称为不可重复读,即原始读取不可重复。
什么是幻读?
幻读是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样.一般解决幻读的方法是增加范围锁RangeS,锁定检锁范围为只读,这样就避免了幻读。
幻读是不可重复读的一种特殊场景:当事务没有获取范围锁的情况下执行SELECT … WHERE操作可能会发生幻读。
一句话总结脏读、不可重复读、幻读
脏读:读到了其他事务还没有提交的数据。
不可重复读:对某数据进行读取过程中,有其他事务对数据进行了修改(UPDATE、DELETE),导致第二次读取的结果不同。
幻读:事务在做范围查询过程中,有另外一个事务对范围内新增或删除了记录(INSERT、DELETE),导致范围查询的结果条数不一致。Excutors可以产生哪些线程池
1、newCachedThreadPool:用来创建一个可缓存线程池,该线程池没有长度限制,对于新的任务,如果有空闲的线程,则使用空闲的线程执行,如果没有,则新建一个线程来执行任务。如果线程池长度超过处理需要,可灵活回收空闲线程2、newFixedThreadPool :用来创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。定长线程池的大小通常根据系统资源进行设置:Runtime.getRuntime().availableProcessors()3、newScheduledThreadPool:用来创建一个定长线程池,并且支持定时和周期性的执行任务4、newSingleThreadExecutor:用来创建一个单线程化的线程池,它只用唯一的工作线程来执行任务,一次只支持一个,所有任务按照指定的顺序执行OAuth2.0授权码认证流程
1、客户端请求第三方授权
2、用户(资源拥有者)同意给客户端授权
3、客户端获取到授权码,请求认证服务器申请 令牌
4、认证服务器向客户端响应令牌
5、客户端请求资源服务器的资源,资源服务校验令牌合法性,完成授权
6、资源服务器返回受保护资源
NIO和BIO的比较
1.BIO以流的方式处理数据,而NIO以块的方式处理数据,块I/O的效率比流I/O高很多。
2.BIO是阻塞的,NIO是非阻塞的
3. BIO基于字节流和字符流进行操作,而NIO是基于Channel(通道)和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中
4. Selector(选择器)用于监听多个通道的事件,(比如连接请求,数据到达等)因此使用单个线程就可以监听多个客户端通道。
设计一个QPS7.5W的文件上传系统
根据线上日志排查定位问题
Java线上问题排查思路处理流程及定位工具_线上问题处理流程-CSDN博客
深入解析MySQL中不同时间类型的应用与区别(mysql时间的类型)
一、DateTime、TimeStamp、Date、Time和Year区分说明

2、TimeStamp

3、Date

4、Time

5、Year
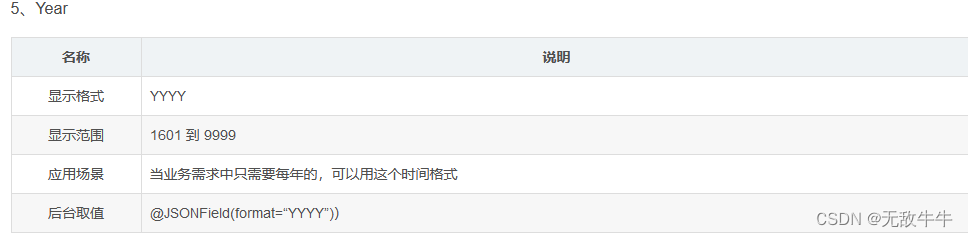
1、精确到毫秒都用TimeStamp
2、如果应用是需要适配不同时区的,有国内和国外的使用,使用TimeStamp就不会出现这种时差的问题,用dateTime就会出现各种各样的问题
红黑树和二叉树特性及区别
二叉树 :索引b+树
树有很多类型,每个节点最多只能有两个子节点的叫二叉树。

红黑树:hashmap
对于那种频繁删除、插入的场景,平衡二叉树的调整过程显然是存在性能问题的,所以为了解决这个问题,进而又引入了红黑树。
红黑树的特点:
具有二叉树所有特点。
每个节点只能是红色或者是黑色。
根节点只能是黑色,且黑色根节点不存储数据。
任何相邻的节点都不能同时为红色。
红色的节点,它的子节点只能是黑色。
从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。红黑树如下图所示:

IO流
线程池参数含义

这 7 个参数分别是:
- corePoolSize:核心线程数。
- maximumPoolSize:最大线程数。
- keepAliveTime:空闲线程存活时间。
- TimeUnit:时间单位。
- BlockingQueue:线程池任务队列。
- ThreadFactory:创建线程的工厂。
- RejectedExecutionHandler:拒绝策略.
参数1:核心线程数:是指线程池中长期存活的线程数。
参数2:最大线程数:线程池允许创建的最大线程数量,当线程池的任务队列满了之后,可以创建的最大线程数。
注意事项
最大线程数 maximumPoolSize 的值不能小于核心线程数 corePoolSize,否则在程序运行时会报 IllegalArgumentException 非法参数异常,如下图所示:

参数3:keepAliveTime
空闲线程存活时间,当线程池中没有任务时,会销毁一些线程,销毁的线程数=maximumPoolSize(最大线程数)-corePoolSize(核心线程数)。
参数4:TimeUnit
时间单位:空闲线程存活时间的描述单位,此参数是配合参数 3 使用的。 参数 3 是一个 long 类型的值,比如参数 3 传递的是 1,那么这个 1 表示的是 1 天?还是 1 小时?还是 1 秒钟?是由参数 4 说了算的。 TimeUnit 有以下 7 个值:
- TimeUnit.DAYS:天
- TimeUnit.HOURS:小时
- TimeUnit.MINUTES:分
- TimeUnit.SECONDS:秒
- TimeUnit.MILLISECONDS:毫秒
- TimeUnit.MICROSECONDS:微妙
- TimeUnit.NANOSECONDS:纳秒
参数5:BlockingQueue
阻塞队列:线程池存放任务的队列,用来存储线程池的所有待执行任务。 它可以设置以下几个值:
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
比较常用的是 LinkedBlockingQueue,线程池的排队策略和 BlockingQueue 息息相关
参数6:ThreadFactory
线程工厂:线程池创建线程时调用的工厂方法,通过此方法可以设置线程的优先级、线程命名规则以及线程类型(用户线程还是守护线程)等。 线程工厂的使用示例如下:

以上程序的执行结果如下:

从上述执行结果可以看出,自定义线程工厂起作用了,线程的名称和线程的优先级都是通过线程工厂设置的。
参数7:RejectedExecutionHandler
拒绝策略:当线程池的任务超出线程池队列可以存储的最大值之后,执行的策略。 默认的拒绝策略有以下 4 种:
- AbortPolicy:拒绝并抛出异常。
- CallerRunsPolicy:使用当前调用的线程来执行此任务。
- DiscardOldestPolicy:抛弃队列头部(最旧)的一个任务,并执行当前任务。
- DiscardPolicy:忽略并抛弃当前任务。
线程池的默认策略是 AbortPolicy 拒绝并抛出异常。
总结
本文介绍了线程池的 7 大参数:
- corePoolSize:核心线程数,线程池正常情况下保持的线程数,大户人家“长工”的数量。
- maximumPoolSize:最大线程数,当线程池繁忙时最多可以拥有的线程数,大户人家“长工”+“短工”的总数量。
- keepAliveTime:空闲线程存活时间,没有活之后“短工”可以生存的最大时间。
- TimeUnit:时间单位,配合参数 3 一起使用,用于描述参数 3 的时间单位。
- BlockingQueue:线程池的任务队列,用于保存线程池待执行任务的容器。
- ThreadFactory:线程工厂,用于创建线程池中线程的工厂方法,通过它可以设置线程的命名规则、优先级和线程类型。
- RejectedExecutionHandler:拒绝策略,当任务量超过线程池可以保存的最大任务数时,执行的策略。
Java依赖版本顺序
重复依赖选择原则
先把重复依赖后 选择原则抛出来 待会一个个进行验证
- 最短路径原则: 两级以上的不同级依赖, 选择路径最短
- 声明优先原则 : 两级以上的同级依赖,先声明的覆盖后声明的
- 同级依赖后加载覆盖先加载原则
事务失效原因
1、@Transactional注解只能在在public修饰的方法下使用。
2、数据库引擎不支持事务(非InnoDB)
3、类内部访问
例:类内部非直接访问带注解标记的方法 B,而是通过类普通方法 A,然后由 A 调用 B。
- @Service
- public class Demo {
- public void A() {
- this.B();
- }
- @Transactional
- public void B() {
- ......
- }
- }
4、事务方法内启动新线程进行异步操作
5、异常类型不匹配
6、传播属性设置问题

@Transactional默认的事务传播机制是:REQUIRED,若指定成了NOT_SUPPORTED、NEVER事务传播机制,则事物不生效
7、捕获异常未抛出
8、Bean没有纳入Spring容器管理
yml文件和properties文件哪个优先级更高
properties > yml
先读 yml文件,再读properties文件,若有相同配置,则加载properties中文件
加载顺序
SpringBoot应用程序在启动时会遵循下面的顺序进行加载配置文件:- 类路径下的配置文件
- 类路径内config子目录的配置文件
- 当前项目根目录下的配置文件
- 当前项目根目录下config子目录的配置文件
示例项目配置文件存放结构如下所示:
- . project-sample
- ├── config
- │ ├── application.yml (4)
- │ └── src/main/resources
- | │ ├── application.yml (1)
- | │ └── config
- | | │ ├── application.yml (2)
- ├── application.yml (3)
启动时加载配置文件顺序:1 > 2 > 3 > 4
src/main/resources下的配置文件在项目编译时,会放在target/classes下。
优先级覆盖
SpringBoot配置文件存在一个特性,优先级较高的配置加载顺序比较靠后,相同名称的配置优先级较高的会覆盖掉优先级较低的内容。了解配置文件的加载顺序,才能得心应手的进行配置覆盖,完全控制在不同环境下使用不同的配置内容,要记住
classes/application.yml优先级最低,project/config/application.yml优先级最高。 -
-
相关阅读:
Spire.Office 7.8.4 for NET --2022-08-17
Windows与Ubuntu之间的文件传输
江波龙入选国家级专精特新“小巨人”企业
Games101-Chapter13-Ray Tracing 1
七月外贸新规,外贸人请查收
6.30 基于自编码器卷积神经网络的室内定位
从零开始搭建React+TypeScript+webpack开发环境-自定义配置化的模拟服务器
“中国网事·感动2022”二季度网络感动人物评选结果揭晓
简历准备及面试技巧,你应该知道的一切
[项目管理-10]:软硬件项目管理 - 项目质量管理(质量)
- 原文地址:https://blog.csdn.net/qq_58772217/article/details/133964770