-
Redis在分布式场景下的应用
分布式缓存
缓存的基本作用是在高并发场景下对应服务的保护缓冲
– 基于Redis集群解决单机Redis存在的问题
单机的Redis存在四大问题:
- redis由于高强度性能采用内存 但是意味着丢失的风险
- 单结点redis并发能力有限
- 分布式服务中数据过多 依赖内存的redis 明显单机不能满足
- 如果发生故障 需要能继续服务
很明显上述效果需要集群才能实现
解决方案

1.Redis持久化
Redis有两种持久化方案:
- RDB持久化
- AOF持久化
1.1.RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录。
1.1.1.执行时机
RDB持久化在四种情况下会执行:
- 执行save命令
- 执行bgsave命令
- Redis停机时
- 触发RDB条件时
1)save命令
执行save的命令,可以立即执行一次RDB:
redis是单线程,所以这里会耗时较久

save命令会导致主进程执行RDB,这个过程中其它所有命令都会被阻塞。只有在数据迁移时可能用到。
2)bgsave命令
下面的命令可以异步执行RDB(background save):

这个命令执行后会开启独立进程完成RDB,主进程可以持续处理用户请求,不受影响。(异步执行持久化)
3)停机时
Redis停机时会执行一次save命令,实现RDB持久化。
比如先启动redis

然后停机

发现redis 输出log 数据保存到磁盘, 以及保存到磁盘上(一般是运行目录无论windos还是linux)
再次启动
之前保存的数据被读取 实现redis的持久化

日志输出数据从磁盘读取4)触发RDB条件
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB save 900 1 save 300 10 save 60 10000- 1
- 2
- 3
- 4
RDB的其它配置也可以在redis.conf文件(windos系统是redis.windos.conf)中设置:

redis
默认持久化策略# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱 rdbcompression yes # RDB文件名称 dbfilename dump.rdb # 文件保存的路径目录 dir ./- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里为了测试把触发持久化事件改短一点

5秒内发生修改就持久化
重启后 设置一个数据
日志输出

后台备份成功
设置备份时间的间隔应该考虑业务中数据量的大小和耗时1.1.2.RDB原理
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。

所以如果在分布式业务中,有一台服务器是专门用于做缓存,那么的为了redis的备份机制正常运行,应该预留一些内存给子进程fork
1.1.3.小结
RDB方式bgsave的基本流程
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
RDB会在什么时候执行
- 默认是服务停止时
- 可以通通过配置环境修改频率
RDB的缺点
- RDB执行间隔时间长(如果修改配置备份时间变短,会大致大量资源消耗,耗时压力更大),两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
1.2.AOF持久化
1.2.1.AOF原理
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,因为记录的不是完整的数据,而是数据的操作命令 可以看做是命令日志文件。

当redis 宕机 ,redis重启后 读取aof文件,执行指令来恢复数据1.2.2.AOF配置
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no appendonly yes # AOF文件的名称 appendfilename "appendonly.aof"- 1
- 2
- 3
- 4
选择执行AOF前先将rdb 策略进行注释

开启aof策略

重启redis

log rdb 没有读取 说明确实禁止了
然后写几个存储

此时aof 文件出现当前目录

打开查看 确实记录的是命令

关闭服务且从重启

关闭时候同步到本地日志

读取数据 成功 并没丢失

AOF的命令记录的频率也可以通过redis.conf文件来配:
# 表示每执行一次写命令,立即记录到AOF文件 redis是单线程业务 这样的同步需求 对性能消耗较大 appendfsync always # 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案 appendfsync everysec # 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘 appendfsync no- 1
- 2
- 3
- 4
- 5
- 6
三种策略对比:

1.2.3.AOF文件重写
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

如图,AOF原本有三个命令,但是
set num 123 和 set num 666都是对num的操作,第二次会覆盖第一次的值,因此第一个命令记录下来没有意义。所以重写命令后,AOF文件内容就是:
mset name jack num 666在最后一次写入操作后执行

Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写 auto-aof-rewrite-percentage 100 # AOF文件体积最小多大以上才触发重写 auto-aof-rewrite-min-size 64mb- 1
- 2
- 3
- 4
1.3.RDB与AOF对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。

2.Redis主从
2.1.搭建主从架构
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群(之前的常用集群模式是负载均衡),实现读写分离。
Redis集群和主从复制是两种不同的Redis部署模式,它们各自解决不同的问题和提供不同的功能。以下是它们的主要区别和用途:
-
Redis主从复制(Replication):
-
用途: 主从复制的主要目的是提高数据的可用性和可靠性。在主从复制中,一个Redis主节点(master)会将数据复制给一个或多个从节点(slaves)。
-
数据复制: 主节点负责写操作,从节点复制主节点的数据。这有助于实现数据备份和故障恢复。如果主节点出现故障,可以快速切换到从节点来提供服务,从而降低了系统的单点故障风险。
-
性能: 主从复制通常不旨在提高性能,因为主节点仍然处理所有的写操作,而从节点主要用于读取和故障切换。
Redis集群(Cluster):
- 用途: Redis集群的主要目的是横向扩展Redis以处理大规模的数据和请求。它是一种分布式系统,用于提高性能、负载均衡和高可用性。
7.数据分片: Redis集群将数据分为多个分片,每个分片可以在集群中的不同节点上。这有助于平衡负载和提高性能,因为请求可以同时分布到多个节点上。 - 高可用性: Redis集群也提供了高可用性,因为它可以自动管理节点故障,并在需要时重新分配分片。
为什么不采用负载均衡来搭建Redis集群呢?
负载均衡和Redis集群的目标不同: 负载均衡通常用于分发流量到多个相同的后端服务器,以提高性能和可用性。但Redis集群的目标更广泛,包括数据分片、高可用性、负载均衡等,它们是分布式系统的一部分。
数据一致性和分片: 在负载均衡中,通常不会考虑数据一致性,因为它主要关注请求的分发。然而,Redis集群需要确保数据的一致性和可用性,因此它使用数据分片和复制来实现这一目标。
性能和可用性需求: 如果您需要横向扩展Redis以处理大量请求并提供高可用性,那么Redis集群是更合适的选择。负载均衡通常在单一后端服务或多个相同的后端服务之间分发请求,但它不提供数据的分片和自动故障切换。综上所述,Redis主从复制和Redis集群是针对不同需求的两种不同部署方式。您应根据您的具体需求和目标来选择适当的部署方式。如果需要横向扩展和高可用性,Redis集群可能更适合您。如果只需备份和故障切换,主从复制可能足够。负载均衡通常在应用层用于分发请求到多个Redis节点,但它通常不提供数据分片和高可用性功能。

这里采用docker实现采用
Docker 部署主从redis集群
创建一个目录作为演示集群的文件目录,其中创建三个7001,7002,7003表示redis的三台实列目录,端口和目录名字对应

进行各个子目录创建对应数据卷挂载目录创建一个data目录 和re创建一个redis.config

配置文件的内容就按照自己从默认reidis中按照需求写更改
然后运行docker 进行挂载
挂载数据券和配置文件docker run -d -p 7001:6379 -v /home/hadoop/Redis-cluster/7001/redis-data-7001/:/data -v /home/hadoop/Rediscluster/7001/redis.config:/data/redis.conf --name redis7001 redis redis-server /data/redis.conf- 1
- 2
进入容器
docker exec -it redis7001 redis-cli- 1
根据配置文件的密码登录后创建数据,在进行重启

关闭服务docker stop redis7001- 1

日志和之前一样重启
docker start redis7001- 1
日志输出

读取数据 发现可以做到数据持久化

按照同样步骤在启动俩台redis容器

成功启动三台实列
为了实现主从同步 ,将aof模式关闭,开始RDB配置# 开启RDB # save "" save 3600 1 save 300 100 save 60 10000 # 关闭AOF appendonly no- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
集群配置
在使用Docker搭建Redis集群时,Redis官方提供了一个叫做Redis集群模式的特性。使用集群模式,Redis实例可以在不修改配置文件的情况下组成集群。Redis集群模式是通过Redis的内建集群支持实现的,不需要手动修改配置文件。
在Redis集群中,每个节点都可以是主节点也可以是从节点。节点之间通过Gossip协议进行通信。在Docker中,你可以简单地通过运行多个Redis容器,并在它们之间配置集群。
以下是在Docker中使用集群模式配置Redis集群的步骤:-
创建Redis集群网络:
首先,创建一个Docker网络,以便在Redis容器之间进行通信。你可以使用以下命令创建一个名为redis-net的网络:
docker network create redis-net -
启动Redis容器:
运行多个Redis容器,并将它们加入到redis-net网络中。在这里,你只需要指定容器的名称、网络、端口映射等信息。Docker会为每个容器自动分配一个唯一的Container ID和IP地址。
docker run -d --name redis-node1 --net redis-net -p 7001:6379 redis docker run -d --name redis-node2 --net redis-net -p 7002:6379 redis docker run -d --name redis-node3 --net redis-net -p 7003:6379 redis # ...添加更多的Redis节点- 1
- 2
- 3
- 4
- 配置集群:
连接到任意一个Redis容器中,并使用redis-cli命令配置集群。在下面的命令中,你需要指定所有的Redis节点地址及端口,以及–cluster-replicas 1参数表示每个主节点有一个从节点:
docker exec -it redis-node1 redis-cli --cluster create \ 172.18.0.2:6379 172.18.0.3:6379 172.18.0.4:6379 \ 172.18.0.5:6379 172.18.0.6:6379 172.18.0.7:6379 \ --cluster-replicas 1- 1
- 2
- 3
- 4
上述命令中,172.18.0.2至172.18.0.7是各个Redis容器的IP地址。运行这个命令后,Redis集群就会自动配置好,每个节点都知道其他节点的信息。
4. 验证集群配置:
你可以使用以下命令验证Redis集群的配置是否成功:docker exec -it redis-node1 redis-cli cluster nodes- 1
这将显示Redis集群的节点信息。如果所有节点都显示正常,那么你的Redis集群就已经配置成功了,这里主要演示主从结果,所以不做演示
请注意,这种配置方式是基于Docker内建的集群支持实现的,不需要手动修改配置文件。但在生产环境中,你可能需要进一步配置安全性、持久性和高可用性等方面的参数,以确保集群的稳定性和安全性。
2.2.主从数据同步原理
2.2.1.全量同步
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点,流程:

这里有一个问题,master如何得知salve是第一次来连接呢??
有几个概念,可以作为判断依据:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid,从节点第一次申请同步id不同,所以会接收到 主节点的数据,后续操作进行通信时,id相等,说明以及是同步
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
因为slave原本也是一个master,有自己的replid和offset,当第一次变成slave,与master建立连接时,发送的replid和offset是自己的replid和offset。
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。
如图:

完整流程描述:
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
2.2.2.增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了,资源消耗过多。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。
什么是增量同步?就是只更新slave与master存在差异的部分数据(主节点数据更新,从结点因为宕机或网络问题没有一直,只做这部分差异更新)。如图:

2.2.3.repl_backlog原理
master怎么知道slave与自己的数据差异在哪里呢?
这就要说到全量同步时的repl_baklog文件了。
这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset:

slave与master的offset之间的差异,就是salve需要增量拷贝的数据了。
随着不断有数据写入,master的offset逐渐变大,slave也不断的拷贝,追赶master的offset:

直到数组被填满:

此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分。
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset:

如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖:

棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。

2.3.主从同步优化
主从同步可以保证主从数据的一致性,非常重要。
可以从以下几个方面来优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。(要求服务器网络高,而读取磁盘慢,不然会造擦网络服务堵塞)
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
主从从架构图:

主从关系实现
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
-
修改从结点配置文件(永久生效)
官方配置文件默认注释

- 在redis.conf中添加一行配置:
slaveof - 有密码的需要配置密码
- 在redis.conf中添加一行配置:
slaveof 192.168.249.132 7001 masterauth 222222- 1
- 2
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <masterip> <masterport>- 1
这里有密码 所以配置主从模式的信息 7002,7003配置

删除旧容器,按照配置文件在启动一遍关闭任一容器查看日志 修改配置成功变回了redis默认的RDB

进入主节点容器7001 使用# 查看状态 info replication- 1
- 2
发现只有master一个结点,这里需要配置
docker 容器进入同一网络
因为docker 容器是互相独立的是,很多时候网络不在一起无法链接删除三个容器,先配置在同一docker网络中
- 创建网络
docker network create my_redis_network- 1
2.运行时候指定docker网络 三个容器使用同一个网络
network=xxxx
改进后docker run -d -p 7001:6379 -v /home/hadoop/Redis-cluster/7001/redis-data-7001/:/data -v /home/hadoop/Redis-cluster/7001/redis.config:/data/redis.conf --network my_redis_network --name redis7001 redis redis-server /data/redis.conf docker run -d -p 7002:7002 -v /home/hadoop/Redis-cluster/7002/redis-data-7002/:/data -v /home/hadoop/Redis-cluster/7002/redis.config:/data/redis.conf --network my_redis_network --name redis7002 redis redis-server /data/redis.conf docker run -d -p 7003:6379 -v /home/hadoop/Redis-cluster/7003/redis-data-7003/:/data -v /home/hadoop/Redis-cluster/7003/redis.config:/data/redis.conf --network my_redis_network --name redis7003 redis redis-server /data/redis.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 三个容器运行时候都拉入同一网络,查看从结点日志

这个时候不在拒绝而是successful ,进入主节点容器后查看结点状态 - docker exec -it redis7001 redis-cli进入容器
- 登录redis后查看状态
输入INFO
此时就可以看到完整的主从结构

主结点写一个数据

从结点可以读取出来

并且无法在进行写数据了

所以默认主从结点完成读写分离,从结点失去写入功能,从节点作为数据读取的副本
这里采用指令链接,但是后续搭配哨兵机制以后修改为配置文件链接,因为测试哨兵机制需要多次重启,并且由主从结构的日志截图可以看出,同一网络下运行的docker容器交互采用的是容器内的端口,为了防止后期哨兵集群部署后,结点数据量大,容器内端口冲突等,建议容器内端口修改为和映射宿主机端口一致
这样避免一些为网络问题

docker运行redis主从模式总结
1.首先配置创建对应的redis容器的数据卷和配置文件,方便挂载
2. 数据备份采用默认的RDB
3. 创建一个docker 网络 运行时候保证在同一网络
4.子实列配置文件写清楚主节点信息slaveof 主结点ip 端口 masterauth 密码- 1
- 2
- docker 运行时指定network
2.4.小结
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
3.Redis哨兵
微服务中有专门的安全保护框架seatenl来对整个分布式进行保护,redis集群躲起来以后,同样的也内置了redis缓存集群监控保护机制
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。3.1.哨兵原理
3.1.1.集群结构和作用
哨兵的结构如图:

哨兵的作用如下:
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
3.1.2.集群监控原理
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
•主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
•客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。

3.1.3.集群故障恢复原理
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大(偏移量越大,主从数据越接近)说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。
当选出一个新的master后,该如何实现切换呢?
流程如下:
这里假设master7001出现故障- sentinel给备选的slave1节点发送slaveof no one命令,让该节点成为master
- sentinel给所有其它slave发送slaveof 192.168.150.101 7002 命令,让这些slave成为新master的从节点,开始从新的master上同步数据。
- 最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点

3.1.4.小结
Sentinel的三个作用是什么?
- 监控
- 故障转移
- 通知
Sentinel如何判断一个redis实例是否健康?
- 每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线(和nacos一样的心跳机制)
- 如果大多数sentinel都认为实例主观下线,则判定服务下线
故障转移步骤有哪些?
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有节点都执行slaveof 新master
- 修改故障节点配置,添加slaveof 新master
3.2.搭建哨兵集群 (docker实现)
依旧采用docker 实现,相比于直接部署服务器,docker 环境隔离,轻量的优点可太爽了
- 创建Docker网络:
首先确保所有的Redis实例和哨兵实例都在同一个网络中:
docker network create redis-net #之前的redis 主从集群就已经运行到一个网络了- 1
- 启动Redis容器:
您可以启动多个Redis容器实例。假设您启动了三个:
docker run -d --name redis1 --net redis-net redis docker run -d --name redis2 --net redis-net redis docker run -d --name redis3 --net redis-net redis- 1
- 2
- 3
这里之前就已经创建并且启动了三个容器

- 创建哨兵配置文件:
新建三个目录存放哨兵文件,以及后续的docker中哨兵工作目录的挂载
s1,s2,s3

创建一个基础的sentinel.conf文件:
port 27001 #端口 sentinel monitor mymaster 192.168.249.132 7001 2 # 设置主服务器结点密码 sentinel auth-pass mymaster 222222 sentinel down-after-milliseconds mymaster 5000 #超时时间默认 sentinel failover-timeout mymaster 60000- 1
- 2
- 3
- 4
- 5
- 6
解读:
port 27001:是当前sentinel实例的端口sentinel monitor mymaster 192.168.249.132 7001 2:指定主节点信息 (通过主节点就可以检测到从结点,所以redis主从架构中,主节点可以代表一个集群)mymaster:主节点名称,自定义,任意写192.168.249.132 7001:主节点的ip和端口2:选举master时的quorum(这里三个哨兵 超过2就检查不到心跳ping就客观下下线)值- 如果不i是docker的话 工作目录实在这个配置文件中指定的目录
dir “/tmp/s1”
s1新建一个如上配置

- 把配置文件复制到其他哨兵工作目录:

然后修改端口,端口需要修改的,虽然docker 可以映射到宿主机的端口,但是docker网络内通信,使用的是docker 容器端口


- 启动哨兵容器:
启动前先查看docker 网络,要确定哨兵和容器能够在同一网络,确保容器通行
docker network ls- 1
就像之前的主从结构一样,docker容器之间通信需要保证同一网络,并且在通信端口是容器内端口
可以申明时定义同一网络 端口和ip
使用这两个参数后,从节点发送给主节点的ip和端口信息就是这里设定好了。
实列在其他电脑,在Docker哨兵的配置中将sentinel announce-ip设置为远程计算机上Redis节点的IP地址。这样,Docker哨兵将正确地宣告Redis节点的位置给其他哨兵和Redis客户端,以便它们知道如何连接到Redis节点。replica-announce-ip 5.5.5.5 replica-announce-port 1234- 1
- 2
哨兵的配置
sentinel announce-ip <ip> sentinel announce-port <port>- 1
- 2
sentinel announce-ip :此选项允许您指定Redis Sentinel应向其他Sentinel实例宣告其监视的Redis实例的IP地址。您应该将其设置为Redis实例所在主机的IP地址。这在Redis实例的实际IP地址与其他Redis Sentinel实例和客户端应用于连接的IP地址不同时非常有用。例如,如果Redis运行在Docker容器中,您可能希望宣告主机机器的IP地址。
sentinel announce-port :此选项指定Redis Sentinel应向其他Sentinel实例宣告的Redis实例的端口。您应该将其设置为Redis实例实际监听的端口。
如果出现同一dockker网络下无法通信就要配置上面的试试
每个哨兵都需要有它自己的配置文件,并挂载到对应的工作目录:
docker run -d --name sentinel1 --net my_redis_network -p 27001:27001 -v /home/hadoop/Redis-cluster/s1:/data -v /home/hadoop/Redis-cluster/s1/sentinel.conf:/etc/sentinel.conf redis redis-sentinel /etc/sentinel.conf docker run -d --name sentinel2 --net my_redis_network -p 27002:27002 -v /home/hadoop/Redis-cluster/s2:/data -v /home/hadoop/Redis-cluster/s2/sentinel.conf:/etc/sentinel.conf redis redis-sentinel /etc/sentinel.conf docker run -d --name sentinel3 --net my_redis_network -p 27003:27003 -v /home/hadoop/Redis-cluster/s3:/data -v /home/hadoop/Redis-cluster/s3/sentinel.conf:/etc/sentinel.conf redis redis-sentinel /etc/sentinel.conf- 1
- 2
- 3
- 4
- 5
docker ps检查运行状态

现在,哨兵容器会使用s1,s2和s3这三个目录作为它们的工作目录(突然发现好多容器的工作目录都是/data 配置文件目录是/etc)。当哨兵进行某些操作时,您可以查看这些目录来观察它们的状态。
6. 测试您的哨兵集群:
停止主节点,并观察哨兵是否将其他节点提升为新的主节点:docker stop redis7001- 1
但是发现并没有切换主节点 并且发现日志
Could not rename tmp config file (Device or resource busy) WARNING: Sentinel was not able to save the new configuration on disk!!!: Device or resource busy- 1
- 2
细节因为Sentinel会在启动后向自己的配置文件中追加内容,它采用的是先创建一个临时配置文件,然后使用它替换掉原来的配置文件的方式。
如果是使用挂载卷直接挂载文件的方式,docker貌似不允许这样操作,所以会出现这个错误,你可以将配置文件放到单独的目录中,然后将目录挂载到容器。
所以三个哨兵目录创建config进行配置目录挂载,而不是文件
每个哨兵文件 新建配置目录config,并把之前的配置文件放进入
进入整个目录的挂载docker run -d --name sentinel1 --net my_redis_network -p 27001:27001 -v /home/hadoop/Redis-cluster/s1/data/:/data -v /home/hadoop/Redis-cluster/s1/config/:/etc/ redis redis-sentinel /etc/sentinel.conf docker run -d --name sentinel2 --net my_redis_network -p 27002:27002 -v /home/hadoop/Redis-cluster/s2/data/:/data -v /home/hadoop/Redis-cluster/s2/config/:/etc/ redis redis-sentinel /etc/sentinel.conf docker run -d --name sentinel3 --net my_redis_network -p 27003:27003 -v /home/hadoop/Redis-cluster/s3/data:/data -v /home/hadoop/Redis-cluster/s3/config/:/etc/ redis redis-sentinel /etc/sentinel.conf- 1
- 2
- 3
- 4
- 5
- 6
此时查看任一哨兵日志

不在出现警告无法写入磁盘
并且进入任一哨兵容器docker exec -it 哨兵容器 redis-cli -p 哨兵端口- 1
查看监视该集群的哨兵由那些,就能知道是否能通信了
SENTINEL sentinels <master-name>- 1
发现可以监控

日志哨兵日志

发现成功监控并且知道从主从信息已经同一监控
现在测试停止监控的redis集群 7001
输出哨兵日志,哨兵监控到结点服务异常
最重要的一条

发现选择哨兵选择了7003结点代替原来的主节点,进入7003容器docker exec -it redis7003 redis-cli -p 7003- 1
输入info

此时7003成为主要结点,说明哨兵的功能起到作用,防止业务瘫痪,监视集群并且替换主节点3.2.1 哨兵集群结构

3.3.RedisTemplate
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
下面,我们通过一个测试来实现RedisTemplate集成哨兵机制。
假如一个一般springboot项目
主要就以下一个controller 通过restful接口 风格操作redis@RestController public class HelloController { @Autowired private StringRedisTemplate redisTemplate; @GetMapping("/get/{key}") public String hi(@PathVariable String key) { return redisTemplate.opsForValue().get(key); } // 接口操作数据库 @GetMapping("/set/{key}/{value}") public String hi(@PathVariable String key, @PathVariable String value) { redisTemplate.opsForValue().set(key, value); return "success"; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.3.2.引入依赖
在项目的pom文件中引入依赖:
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-redisartifactId> dependency>- 1
- 2
- 3
- 4
3.3.3.配置Redis地址
然后在配置文件application.yml中指定redis的sentinel相关信息:
在sentinel 模式下,主从模式的集群有可能会随着业务变更,所以只需要配置监控者,就可以得到被监控的信息spring: redis: sentinel: master: mymaster nodes: - 192.168.249.132:27001 - 192.168.249.132:27002 - 192.168.249.132:27003 password: 222222- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我redis密码集群吧都是222222
3.3.4.配置读写分离
在项目的启动类中,添加一个新的bean:
Lettuce 是实现redisTemplate客户端的底层实现框架
@Bean public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){ //接口不能new 而只有一个方法明显是函数接口 return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED); }- 1
- 2
- 3
- 4
- 5
主节点设置数据

测试游览器输入对应api 路径

游览器操作redis设置数据

因为controller 返回的

在redis 图形化库查看

说明resttemplate都能实现,并且日志也很详细
从集群中的7001端口结点读取

从7003端口的结点写入

这个时候手动挂机主节点看看日志‘

哨兵是已经发先了,并且switch 7002作为新的主结点
而java客户端的日志是不断的发同步数据

最后确定新的主从结构
检查新的现象 。。。。详细信息

这个bean中配置的就是读写策略,包括四种:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
4.Redis分片集群
4.1.搭建分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
-
海量数据存储问题
-
高并发写的问题
基本只要可以存储数据的分布式中间件都是采用这种方式,比如hadfs使用分片集群可以解决上述问题,如图:

分布式场景建议单结点的redis不应该给予太多内存资源,数据输入量大无论是RDB,AOF,数据备份占用的内存都是很高的,大量的io会给架构带来压力
分片集群特征:
-
集群中有多个master,每个master保存不同数据,保证存储大量数据
-
每个master都可以有多个slave节点,读写分离,扩大存储量的同时还不会降低读的能力
-
master之间通过ping监测彼此健康状态,这样就代表不在需要哨兵机制,集群间相互通信,自动检查集群内存状态
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
4.1.0 docker实现redis分片集群
因为我的虚拟机内存大小优先
-
删除之前的7001、7002、7003这几个目录,重新创建出7001、7002、7003、8001、8002、8003目录:

每个文件的结构

-
新建一个配置文件 通用的 redis.conf
#端口 port 7001 #2、修改bind或注释掉 bind 0.0.0.0 #3、保护模式关闭,因为用docker否则无法访问 protected-mode no #4、关闭后台运行 daemonize no #5、设置密码 #requirepass myredis #6、配置与主节点验证的密码 #masterauth 设置密码 #7、开启aof日志 appendonly yes #8、开启集群模式 cluster-enabled yes #9、根据你启用的节点来命名,最好和端口保持一致,这个是用来保存其他节点的名称,状态等信息的 cluster-config-file nodes_7001.conf #10、超时时间 cluster-node-timeout 5000 #11、集群节点 IP:服务器就填公网ip,或者内部对应容器的ip cluster-announce-ip 192.168.249.132 #12、集群节点映射端口 cluster-announce-port 7001 #13、总线监控ip默认端口+10000 如 7001 就是 17001 cluster-announce-bus-port 17001- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
每个Redis集群中的节点都需要打开两个TCP连接。用于客户端提供服务,比如6379,还有一个额外的端口(通过在这个端口号上加10000)作为数据端口,例如:redis的端口为6379,那么另外一个需要开通的端口是:6379 + 10000, 即需要开启 16379。16379端口用于集群总线,这是一个用二进制协议的点对点通信信道。这个集群总线(Cluster bus)用于节点的失败侦测 ,如果不配置该项,很可能出现创建集群中一直waiting 线程堵塞
复制到每个文件夹,按照自己的需求进行更改
运行
docker run -d -p 7001:7001 -p 17001:17001 -v /home/hadoop/Redis-cluster/7001/data/:/data/ -v /home/hadoop/Redis-cluster/7001/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis7001 redis redis-server /data/redis.conf docker run -d -p 7002:7002 -p 17002:17002 -v /home/hadoop/Redis-cluster/7002/data/:/data/ -v /home/hadoop/Redis-cluster/7002/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis7002 redis redis-server /data/redis.conf docker run -d -p 7003:7003 -p 17003:17003 -v /home/hadoop/Redis-cluster/7003/data/:/data/ -v /home/hadoop/Redis-cluster/7003/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis7003 redis redis-server /data/redis.conf docker run -d -p 8001:8001 -p 18001:18001 -v /home/hadoop/Redis-cluster/8001/data/:/data/ -v /home/hadoop/Redis-cluster/8001/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis8001 redis redis-server /data/redis.conf docker run -d -p 8002:8002 -p 18002:18002 -v /home/hadoop/Redis-cluster/8002/data/:/data/ -v /home/hadoop/Redis-cluster/8002/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis8002 redis redis-server /data/redis.conf docker run -d -p 8003:8003 -p 18003:18003 -v /home/hadoop/Redis-cluster/8003/data/:/data/ -v /home/hadoop/Redis-cluster/8003/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis8003 redis redis-server /data/redis.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
容器运行成功

)构建集群我们使用的是Redis6.2.4版本,集群管理以及集成到了redis-cli中,格式如下:
redis-cli --cluster create --cluster-replicas 1 192.168.249.132:7001 192.168.249.132:7002 192.168.249.132:7003 192.168.249.132:8001 192.168.249.132:8002 192.168.249.132:8003- 1
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
因为docker的部署的redis,redis-cli 在容器内 所以运行
docker exec -it redis7001(任一结点) redis-cli --cluster create --cluster-replicas 1 192.168.249.132:7001 192.168.249.132:7002 192.168.249.132:7003 192.168.249.132:8001 192.168.249.132:8002 192.168.249.132:8003- 1
结构输出

redis集群正在分配插槽,然后询问你是否满意这样的分配
回复yes后开始创建集群

如果出现上述截图就是线程堵塞了,需要开启线程总线配置,并且除了redis端口还要自己暴露总线结点修改后命令
docker run -d -p 7001:7001 -p 17001:17001 -v /home/hadoop/Redis-cluster/7001/data/:/data/ -v /home/hadoop/Redis-cluster/7001/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis7001 redis redis-server /data/redis.conf docker run -d -p 7002:7002 -p 17002:17002 -v /home/hadoop/Redis-cluster/7002/data/:/data/ -v /home/hadoop/Redis-cluster/7002/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis7002 redis redis-server /data/redis.conf docker run -d -p 7003:7003 -p 17003:17003 -v /home/hadoop/Redis-cluster/7003/data/:/data/ -v /home/hadoop/Redis-cluster/7003/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis7003 redis redis-server /data/redis.conf docker run -d -p 8001:8001 -p 18001:18001 -v /home/hadoop/Redis-cluster/8001/data/:/data/ -v /home/hadoop/Redis-cluster/8001/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis8001 redis redis-server /data/redis.conf docker run -d -p 8002:8002 -p 18002:18002 -v /home/hadoop/Redis-cluster/8002/data/:/data/ -v /home/hadoop/Redis-cluster/8002/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis8002 redis redis-server /data/redis.conf docker run -d -p 8003:8003 -p 18003:18003 -v /home/hadoop/Redis-cluster/8003/data/:/data/ -v /home/hadoop/Redis-cluster/8003/conf/redis.conf:/data/redis.conf --network my_redis_network --name redis8003 redis redis-server /data/redis.conf- 1
- 2
- 3
- 4
- 5
- 6
此时运行成功

测试链接任一主节点
集群数据操作时,需要给redis-cli加上-c参数才可以:redis-cli -c -p 7001- 1
发现保存数据到该节点,最后却转发到另一个结点

集群中数据插入是根据集群算法来的,会根据转发到这个插槽的结点
redis集群中保存数据,会先对key进行计算,然后保存到计算放置的插槽节点中,并且转发到该结点,这样取值的时候也会根据插槽
进行转发查看结点情况
docker exec -it redis7001 redis-cli -p 7001 cluster nodes- 1

4.2.散列插槽
4.2.1.插槽原理
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:

数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用
CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
如图,在7001这个节点执行set a 1时,对a做hash运算,对16384取余,得到的结果是15495,因此要存储到103节点。
到了7003后,执行
get num时,对num做hash运算,对16384取余,得到的结果是2765,因此需要切换到7001节点4.2.1.小结
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例?(数据分类)
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
比如我这里对name 作为key 进行分组,每个组的前缀不同作为分组

4.3.集群伸缩
redis-cli --cluster提供了很多操作集群的命令,可以通过下面方式查看:

比如,添加节点的命令:

4.3.1.需求分析
需求:向集群中添加一个新的master节点,并向其中存储 num = 10
- 启动一个新的redis实例,端口为7004
- 添加7004到之前的集群,并作为一个master节点
- 给7004节点分配插槽,使得num这个key可以存储到7004实例
这里需要两个新的功能:
- 添加一个节点到集群中
- 将部分插槽分配到新插槽
4.3.2.创建新的redis实例
创建一个文件夹:
mkdir 7004- 1
拷贝之前配置文件:
cp redis.conf /7004- 1
修改配置文件:
sed /s/6379/7004/g 7004/redis.conf- 1
启动

4.3.3.添加新节点到redis
添加节点的语法如下:
执行命令:
docker exec -it redis7001 redis-cli --cluster add-node 192.168.249.132:7004 192.168.249.132:7001- 1

显示ok 已经成功
通过命令查看集群状态:redis-cli -p 7001 cluster nodes- 1
如图,7004加入了集群,并且默认是一个master节点:


但是,可以看到7004节点的插槽数量为0,因此没有任何数据可以存储到7004上

4.3.4.转移插槽
我们要将num存储到7004节点,因此需要先看看num的插槽是多少:
如上图所示,num的插槽为2765.
我们可以将0~3000的插槽从7001转移到7004,命令格式如下:

具体命令如下:
建立连接:

得到下面的反馈:

询问要移动多少个插槽,我们计划是3000个:
复制这个id(nodes 命令中7004的id),然后拷贝到刚才的控制台后:

这里询问,你的插槽是从哪里移动过来的?
- all:代表全部,也就是三个节点各转移一部分
- 具体的id:目标节点的id
- done:没有了
这里我们要从7001获取,因此填写7001的id:可以从多结点分配插槽

填完后,点击done,这样插槽转移就准备好了:
确认要转移吗?输入yes:

日志不断输出转移结果
然后,通过命令查看结果:docker exec -it redis7001 redis-cli -p 7001 cluster nodes
可以看到:
目的达成。
4.4.故障转移
现在集群状态是这样的:

其中7001、7002、7003,7004都是master,我们计划让7002宕机。
4.4.1.自动故障转移
当集群中有一个master宕机会发生什么呢?
直接停止一个redis实例,例如7002:
docker stop redis7002- 1
- 2
1)首先是该实例与其它实例失去连接
2)然后是疑似宕机:

3)最后是确定下线,自动提升一个slave为新的master:
4)当7002再次启动,就会变为一个slave节点了:

这样就通过各个主机之间的心跳检查实现了哨兵的故障转移机制4.4.2.手动故障转移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知(一般是用于服务器硬件升级)的数据迁移。其流程如下:
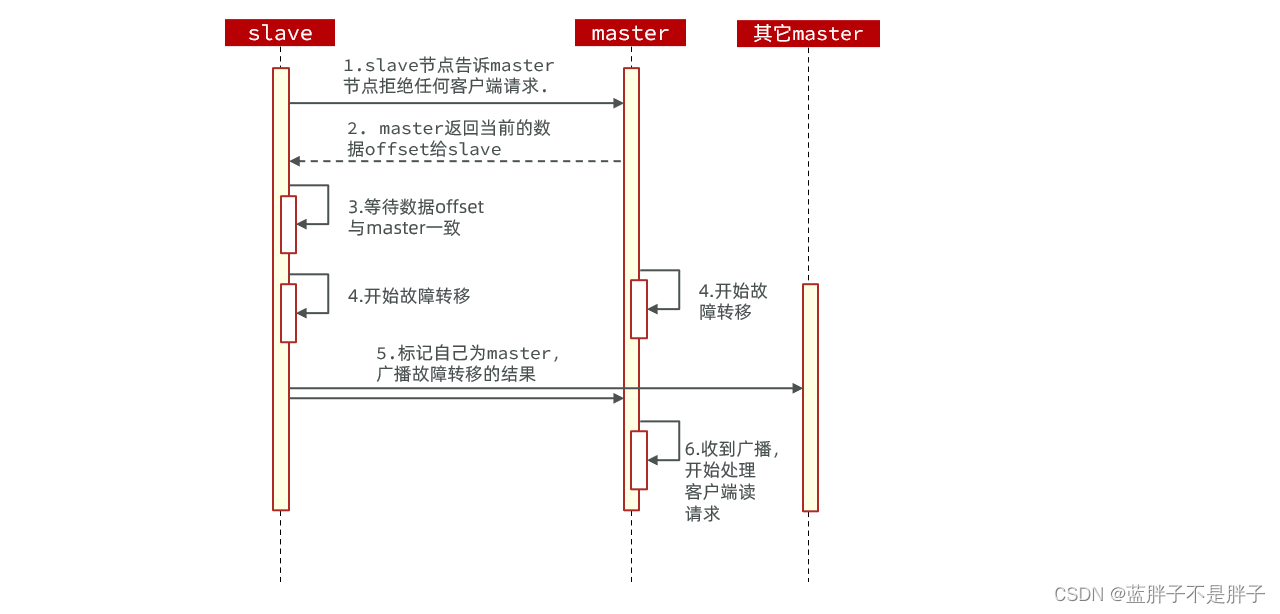
这种failover命令可以指定三种模式:
- 缺省:默认的流程,如图1~6歩
- force:省略了对offset的一致性校验
- takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见
比如我这个演示的集群手动把7002结点重新变为master
docker exec -it redis7002 redis-cli -p 7002- 1

查找结点情况docker exec -it redis7001 redis-cli -p 7001 cluster nodes- 1
7002再次成为master

4.5.RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,所以使用的步骤与哨兵模式基本一致:
1)引入redis的starter依赖
2)配置分片集群地址
3)配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
哨兵
spring: redis: password: 222222 sentinel: master: mymaster nodes: - 192.168.249.132:27001 - 192.168.249.132:27002 - 192.168.249.132:27003- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
集群
spring: redis: cluster: nodes: - 192.168.150.101:7001 - 192.168.150.101:7002 - 192.168.150.101:7003 - 192.168.150.101:8001 - 192.168.150.101:8002 - 192.168.150.101:8003- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
测试
使用之前演示的restful操作

读取成功

查看日志

发现主节点7002写内存
而从节点8002读
说明实现了读写分离


并且保存结点是根据key计算来确定插槽位置的最后附上redis-cli
java客户端的工具类import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cache.annotation.CachingConfigurerSupport; import org.springframework.dao.DataAccessException; import org.springframework.data.redis.connection.DataType; import org.springframework.data.redis.connection.RedisConnection; import org.springframework.data.redis.connection.StringRedisConnection; import org.springframework.data.redis.core.Cursor; import org.springframework.data.redis.core.RedisCallback; import org.springframework.data.redis.core.ScanOptions; import org.springframework.data.redis.core.StringRedisTemplate; import org.springframework.data.redis.core.ZSetOperations.TypedTuple; import org.springframework.lang.Nullable; import org.springframework.stereotype.Component; import java.io.IOException; import java.util.*; import java.util.concurrent.TimeUnit; @Component public class CacheService extends CachingConfigurerSupport { @Autowired private StringRedisTemplate stringRedisTemplate; public StringRedisTemplate getstringRedisTemplate() { return this.stringRedisTemplate; } /** -------------------key相关操作--------------------- */ /** * 删除key * * @param key */ public void delete(String key) { stringRedisTemplate.delete(key); } /** * 批量删除key * * @param keys */ public void delete(Collection<String> keys) { stringRedisTemplate.delete(keys); } /** * 序列化key * * @param key * @return */ public byte[] dump(String key) { return stringRedisTemplate.dump(key); } /** * 是否存在key * * @param key * @return */ public Boolean exists(String key) { return stringRedisTemplate.hasKey(key); } /** * 设置过期时间 * * @param key * @param timeout * @param unit * @return */ public Boolean expire(String key, long timeout, TimeUnit unit) { return stringRedisTemplate.expire(key, timeout, unit); } /** * 设置过期时间 * * @param key * @param date * @return */ public Boolean expireAt(String key, Date date) { return stringRedisTemplate.expireAt(key, date); } /** * 查找匹配的key * * @param pattern * @return */ public Set<String> keys(String pattern) { return stringRedisTemplate.keys(pattern); } /** * 将当前数据库的 key 移动到给定的数据库 db 当中 * * @param key * @param dbIndex * @return */ public Boolean move(String key, int dbIndex) { return stringRedisTemplate.move(key, dbIndex); } /** * 移除 key 的过期时间,key 将持久保持 * * @param key * @return */ public Boolean persist(String key) { return stringRedisTemplate.persist(key); } /** * 返回 key 的剩余的过期时间 * * @param key * @param unit * @return */ public Long getExpire(String key, TimeUnit unit) { return stringRedisTemplate.getExpire(key, unit); } /** * 返回 key 的剩余的过期时间 * * @param key * @return */ public Long getExpire(String key) { return stringRedisTemplate.getExpire(key); } /** * 从当前数据库中随机返回一个 key * * @return */ public String randomKey() { return stringRedisTemplate.randomKey(); } /** * 修改 key 的名称 * * @param oldKey * @param newKey */ public void rename(String oldKey, String newKey) { stringRedisTemplate.rename(oldKey, newKey); } /** * 仅当 newkey 不存在时,将 oldKey 改名为 newkey * * @param oldKey * @param newKey * @return */ public Boolean renameIfAbsent(String oldKey, String newKey) { return stringRedisTemplate.renameIfAbsent(oldKey, newKey); } /** * 返回 key 所储存的值的类型 * * @param key * @return */ public DataType type(String key) { return stringRedisTemplate.type(key); } /** -------------------string相关操作--------------------- */ /** * 设置指定 key 的值 * @param key * @param value */ public void set(String key, String value) { stringRedisTemplate.opsForValue().set(key, value); } /** * 获取指定 key 的值 * @param key * @return */ public String get(String key) { return stringRedisTemplate.opsForValue().get(key); } /** * 返回 key 中字符串值的子字符 * @param key * @param start * @param end * @return */ public String getRange(String key, long start, long end) { return stringRedisTemplate.opsForValue().get(key, start, end); } /** * 将给定 key 的值设为 value ,并返回 key 的旧值(old value) * * @param key * @param value * @return */ public String getAndSet(String key, String value) { return stringRedisTemplate.opsForValue().getAndSet(key, value); } /** * 对 key 所储存的字符串值,获取指定偏移量上的位(bit) * * @param key * @param offset * @return */ public Boolean getBit(String key, long offset) { return stringRedisTemplate.opsForValue().getBit(key, offset); } /** * 批量获取 * * @param keys * @return */ public List<String> multiGet(Collection<String> keys) { return stringRedisTemplate.opsForValue().multiGet(keys); } /** * 设置ASCII码, 字符串'a'的ASCII码是97, 转为二进制是'01100001', 此方法是将二进制第offset位值变为value * * @param key * @param * @param value * 值,true为1, false为0 * @return */ public boolean setBit(String key, long offset, boolean value) { return stringRedisTemplate.opsForValue().setBit(key, offset, value); } /** * 将值 value 关联到 key ,并将 key 的过期时间设为 timeout * * @param key * @param value * @param timeout * 过期时间 * @param unit * 时间单位, 天:TimeUnit.DAYS 小时:TimeUnit.HOURS 分钟:TimeUnit.MINUTES * 秒:TimeUnit.SECONDS 毫秒:TimeUnit.MILLISECONDS */ public void setEx(String key, String value, long timeout, TimeUnit unit) { stringRedisTemplate.opsForValue().set(key, value, timeout, unit); } /** * 只有在 key 不存在时设置 key 的值 * * @param key * @param value * @return 之前已经存在返回false,不存在返回true */ public boolean setIfAbsent(String key, String value) { return stringRedisTemplate.opsForValue().setIfAbsent(key, value); } /** * 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始 * * @param key * @param value * @param offset * 从指定位置开始覆写 */ public void setRange(String key, String value, long offset) { stringRedisTemplate.opsForValue().set(key, value, offset); } /** * 获取字符串的长度 * * @param key * @return */ public Long size(String key) { return stringRedisTemplate.opsForValue().size(key); } /** * 批量添加 * * @param maps */ public void multiSet(Map<String, String> maps) { stringRedisTemplate.opsForValue().multiSet(maps); } /** * 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 * * @param maps * @return 之前已经存在返回false,不存在返回true */ public boolean multiSetIfAbsent(Map<String, String> maps) { return stringRedisTemplate.opsForValue().multiSetIfAbsent(maps); } /** * 增加(自增长), 负数则为自减 * * @param key * @param * @return */ public Long incrBy(String key, long increment) { return stringRedisTemplate.opsForValue().increment(key, increment); } /** * * @param key * @param * @return */ public Double incrByFloat(String key, double increment) { return stringRedisTemplate.opsForValue().increment(key, increment); } /** * 追加到末尾 * * @param key * @param value * @return */ public Integer append(String key, String value) { return stringRedisTemplate.opsForValue().append(key, value); } /** -------------------hash相关操作------------------------- */ /** * 获取存储在哈希表中指定字段的值 * * @param key * @param field * @return */ public Object hGet(String key, String field) { return stringRedisTemplate.opsForHash().get(key, field); } /** * 获取所有给定字段的值 * * @param key * @return */ public Map<Object, Object> hGetAll(String key) { return stringRedisTemplate.opsForHash().entries(key); } /** * 获取所有给定字段的值 * * @param key * @param fields * @return */ public List<Object> hMultiGet(String key, Collection<Object> fields) { return stringRedisTemplate.opsForHash().multiGet(key, fields); } public void hPut(String key, String hashKey, String value) { stringRedisTemplate.opsForHash().put(key, hashKey, value); } public void hPutAll(String key, Map<String, String> maps) { stringRedisTemplate.opsForHash().putAll(key, maps); } /** * 仅当hashKey不存在时才设置 * * @param key * @param hashKey * @param value * @return */ public Boolean hPutIfAbsent(String key, String hashKey, String value) { return stringRedisTemplate.opsForHash().putIfAbsent(key, hashKey, value); } /** * 删除一个或多个哈希表字段 * * @param key * @param fields * @return */ public Long hDelete(String key, Object... fields) { return stringRedisTemplate.opsForHash().delete(key, fields); } /** * 查看哈希表 key 中,指定的字段是否存在 * * @param key * @param field * @return */ public boolean hExists(String key, String field) { return stringRedisTemplate.opsForHash().hasKey(key, field); } /** * 为哈希表 key 中的指定字段的整数值加上增量 increment * * @param key * @param field * @param increment * @return */ public Long hIncrBy(String key, Object field, long increment) { return stringRedisTemplate.opsForHash().increment(key, field, increment); } /** * 为哈希表 key 中的指定字段的整数值加上增量 increment * * @param key * @param field * @param delta * @return */ public Double hIncrByFloat(String key, Object field, double delta) { return stringRedisTemplate.opsForHash().increment(key, field, delta); } /** * 获取所有哈希表中的字段 * * @param key * @return */ public Set<Object> hKeys(String key) { return stringRedisTemplate.opsForHash().keys(key); } /** * 获取哈希表中字段的数量 * * @param key * @return */ public Long hSize(String key) { return stringRedisTemplate.opsForHash().size(key); } /** * 获取哈希表中所有值 * * @param key * @return */ public List<Object> hValues(String key) { return stringRedisTemplate.opsForHash().values(key); } /** * 迭代哈希表中的键值对 * * @param key * @param options * @return */ public Cursor<Map.Entry<Object, Object>> hScan(String key, ScanOptions options) { return stringRedisTemplate.opsForHash().scan(key, options); } /** ------------------------list相关操作---------------------------- */ /** * 通过索引获取列表中的元素 * * @param key * @param index * @return */ public String lIndex(String key, long index) { return stringRedisTemplate.opsForList().index(key, index); } /** * 获取列表指定范围内的元素 * * @param key * @param start * 开始位置, 0是开始位置 * @param end * 结束位置, -1返回所有 * @return */ public List<String> lRange(String key, long start, long end) { return stringRedisTemplate.opsForList().range(key, start, end); } /** * 存储在list头部 * * @param key * @param value * @return */ public Long lLeftPush(String key, String value) { return stringRedisTemplate.opsForList().leftPush(key, value); } /** * * @param key * @param value * @return */ public Long lLeftPushAll(String key, String... value) { return stringRedisTemplate.opsForList().leftPushAll(key, value); } /** * * @param key * @param value * @return */ public Long lLeftPushAll(String key, Collection<String> value) { return stringRedisTemplate.opsForList().leftPushAll(key, value); } /** * 当list存在的时候才加入 * * @param key * @param value * @return */ public Long lLeftPushIfPresent(String key, String value) { return stringRedisTemplate.opsForList().leftPushIfPresent(key, value); } /** * 如果pivot存在,再pivot前面添加 * * @param key * @param pivot * @param value * @return */ public Long lLeftPush(String key, String pivot, String value) { return stringRedisTemplate.opsForList().leftPush(key, pivot, value); } /** * * @param key * @param value * @return */ public Long lRightPush(String key, String value) { return stringRedisTemplate.opsForList().rightPush(key, value); } /** * * @param key * @param value * @return */ public Long lRightPushAll(String key, String... value) { return stringRedisTemplate.opsForList().rightPushAll(key, value); } /** * * @param key * @param value * @return */ public Long lRightPushAll(String key, Collection<String> value) { return stringRedisTemplate.opsForList().rightPushAll(key, value); } /** * 为已存在的列表添加值 * * @param key * @param value * @return */ public Long lRightPushIfPresent(String key, String value) { return stringRedisTemplate.opsForList().rightPushIfPresent(key, value); } /** * 在pivot元素的右边添加值 * * @param key * @param pivot * @param value * @return */ public Long lRightPush(String key, String pivot, String value) { return stringRedisTemplate.opsForList().rightPush(key, pivot, value); } /** * 通过索引设置列表元素的值 * * @param key * @param index * 位置 * @param value */ public void lSet(String key, long index, String value) { stringRedisTemplate.opsForList().set(key, index, value); } /** * 移出并获取列表的第一个元素 * * @param key * @return 删除的元素 */ public String lLeftPop(String key) { return stringRedisTemplate.opsForList().leftPop(key); } /** * 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 * * @param key * @param timeout * 等待时间 * @param unit * 时间单位 * @return */ public String lBLeftPop(String key, long timeout, TimeUnit unit) { return stringRedisTemplate.opsForList().leftPop(key, timeout, unit); } /** * 移除并获取列表最后一个元素 * * @param key * @return 删除的元素 */ public String lRightPop(String key) { return stringRedisTemplate.opsForList().rightPop(key); } /** * 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 * * @param key * @param timeout * 等待时间 * @param unit * 时间单位 * @return */ public String lBRightPop(String key, long timeout, TimeUnit unit) { return stringRedisTemplate.opsForList().rightPop(key, timeout, unit); } /** * 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 * * @param sourceKey * @param destinationKey * @return */ public String lRightPopAndLeftPush(String sourceKey, String destinationKey) { return stringRedisTemplate.opsForList().rightPopAndLeftPush(sourceKey, destinationKey); } /** * 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 * * @param sourceKey * @param destinationKey * @param timeout * @param unit * @return */ public String lBRightPopAndLeftPush(String sourceKey, String destinationKey, long timeout, TimeUnit unit) { return stringRedisTemplate.opsForList().rightPopAndLeftPush(sourceKey, destinationKey, timeout, unit); } /** * 删除集合中值等于value得元素 * * @param key * @param index * index=0, 删除所有值等于value的元素; index>0, 从头部开始删除第一个值等于value的元素; * index<0, 从尾部开始删除第一个值等于value的元素; * @param value * @return */ public Long lRemove(String key, long index, String value) { return stringRedisTemplate.opsForList().remove(key, index, value); } /** * 裁剪list * * @param key * @param start * @param end */ public void lTrim(String key, long start, long end) { stringRedisTemplate.opsForList().trim(key, start, end); } /** * 获取列表长度 * * @param key * @return */ public Long lLen(String key) { return stringRedisTemplate.opsForList().size(key); } /** --------------------set相关操作-------------------------- */ /** * set添加元素 * * @param key * @param values * @return */ public Long sAdd(String key, String... values) { return stringRedisTemplate.opsForSet().add(key, values); } /** * set移除元素 * * @param key * @param values * @return */ public Long sRemove(String key, Object... values) { return stringRedisTemplate.opsForSet().remove(key, values); } /** * 移除并返回集合的一个随机元素 * * @param key * @return */ public String sPop(String key) { return stringRedisTemplate.opsForSet().pop(key); } /** * 将元素value从一个集合移到另一个集合 * * @param key * @param value * @param destKey * @return */ public Boolean sMove(String key, String value, String destKey) { return stringRedisTemplate.opsForSet().move(key, value, destKey); } /** * 获取集合的大小 * * @param key * @return */ public Long sSize(String key) { return stringRedisTemplate.opsForSet().size(key); } /** * 判断集合是否包含value * * @param key * @param value * @return */ public Boolean sIsMember(String key, Object value) { return stringRedisTemplate.opsForSet().isMember(key, value); } /** * 获取两个集合的交集 * * @param key * @param otherKey * @return */ public Set<String> sIntersect(String key, String otherKey) { return stringRedisTemplate.opsForSet().intersect(key, otherKey); } /** * 获取key集合与多个集合的交集 * * @param key * @param otherKeys * @return */ public Set<String> sIntersect(String key, Collection<String> otherKeys) { return stringRedisTemplate.opsForSet().intersect(key, otherKeys); } /** * key集合与otherKey集合的交集存储到destKey集合中 * * @param key * @param otherKey * @param destKey * @return */ public Long sIntersectAndStore(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForSet().intersectAndStore(key, otherKey, destKey); } /** * key集合与多个集合的交集存储到destKey集合中 * * @param key * @param otherKeys * @param destKey * @return */ public Long sIntersectAndStore(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForSet().intersectAndStore(key, otherKeys, destKey); } /** * 获取两个集合的并集 * * @param key * @param otherKeys * @return */ public Set<String> sUnion(String key, String otherKeys) { return stringRedisTemplate.opsForSet().union(key, otherKeys); } /** * 获取key集合与多个集合的并集 * * @param key * @param otherKeys * @return */ public Set<String> sUnion(String key, Collection<String> otherKeys) { return stringRedisTemplate.opsForSet().union(key, otherKeys); } /** * key集合与otherKey集合的并集存储到destKey中 * * @param key * @param otherKey * @param destKey * @return */ public Long sUnionAndStore(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForSet().unionAndStore(key, otherKey, destKey); } /** * key集合与多个集合的并集存储到destKey中 * * @param key * @param otherKeys * @param destKey * @return */ public Long sUnionAndStore(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForSet().unionAndStore(key, otherKeys, destKey); } /** * 获取两个集合的差集 * * @param key * @param otherKey * @return */ public Set<String> sDifference(String key, String otherKey) { return stringRedisTemplate.opsForSet().difference(key, otherKey); } /** * 获取key集合与多个集合的差集 * * @param key * @param otherKeys * @return */ public Set<String> sDifference(String key, Collection<String> otherKeys) { return stringRedisTemplate.opsForSet().difference(key, otherKeys); } /** * key集合与otherKey集合的差集存储到destKey中 * * @param key * @param otherKey * @param destKey * @return */ public Long sDifference(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForSet().differenceAndStore(key, otherKey, destKey); } /** * key集合与多个集合的差集存储到destKey中 * * @param key * @param otherKeys * @param destKey * @return */ public Long sDifference(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForSet().differenceAndStore(key, otherKeys, destKey); } /** * 获取集合所有元素 * * @param key * @param * @param * @return */ public Set<String> setMembers(String key) { return stringRedisTemplate.opsForSet().members(key); } /** * 随机获取集合中的一个元素 * * @param key * @return */ public String sRandomMember(String key) { return stringRedisTemplate.opsForSet().randomMember(key); } /** * 随机获取集合中count个元素 * * @param key * @param count * @return */ public List<String> sRandomMembers(String key, long count) { return stringRedisTemplate.opsForSet().randomMembers(key, count); } /** * 随机获取集合中count个元素并且去除重复的 * * @param key * @param count * @return */ public Set<String> sDistinctRandomMembers(String key, long count) { return stringRedisTemplate.opsForSet().distinctRandomMembers(key, count); } /** * * @param key * @param options * @return */ public Cursor<String> sScan(String key, ScanOptions options) { return stringRedisTemplate.opsForSet().scan(key, options); } /**------------------zSet相关操作--------------------------------*/ /** * 添加元素,有序集合是按照元素的score值由小到大排列 * * @param key * @param value * @param score * @return */ public Boolean zAdd(String key, String value, double score) { return stringRedisTemplate.opsForZSet().add(key, value, score); } /** * * @param key * @param values * @return */ public Long zAdd(String key, Set<TypedTuple<String>> values) { return stringRedisTemplate.opsForZSet().add(key, values); } /** * * @param key * @param values * @return */ public Long zRemove(String key, Object... values) { return stringRedisTemplate.opsForZSet().remove(key, values); } public Long zRemove(String key, Collection<String> values) { if(values!=null&&!values.isEmpty()){ Object[] objs = values.toArray(new Object[values.size()]); return stringRedisTemplate.opsForZSet().remove(key, objs); } return 0L; } /** * 增加元素的score值,并返回增加后的值 * * @param key * @param value * @param delta * @return */ public Double zIncrementScore(String key, String value, double delta) { return stringRedisTemplate.opsForZSet().incrementScore(key, value, delta); } /** * 返回元素在集合的排名,有序集合是按照元素的score值由小到大排列 * * @param key * @param value * @return 0表示第一位 */ public Long zRank(String key, Object value) { return stringRedisTemplate.opsForZSet().rank(key, value); } /** * 返回元素在集合的排名,按元素的score值由大到小排列 * * @param key * @param value * @return */ public Long zReverseRank(String key, Object value) { return stringRedisTemplate.opsForZSet().reverseRank(key, value); } /** * 获取集合的元素, 从小到大排序 * * @param key * @param start * 开始位置 * @param end * 结束位置, -1查询所有 * @return */ public Set<String> zRange(String key, long start, long end) { return stringRedisTemplate.opsForZSet().range(key, start, end); } /** * 获取zset集合的所有元素, 从小到大排序 * */ public Set<String> zRangeAll(String key) { return zRange(key,0,-1); } /** * 获取集合元素, 并且把score值也获取 * * @param key * @param start * @param end * @return */ public Set<TypedTuple<String>> zRangeWithScores(String key, long start, long end) { return stringRedisTemplate.opsForZSet().rangeWithScores(key, start, end); } /** * 根据Score值查询集合元素 * * @param key * @param min * 最小值 * @param max * 最大值 * @return */ public Set<String> zRangeByScore(String key, double min, double max) { return stringRedisTemplate.opsForZSet().rangeByScore(key, min, max); } /** * 根据Score值查询集合元素, 从小到大排序 * * @param key * @param min * 最小值 * @param max * 最大值 * @return */ public Set<TypedTuple<String>> zRangeByScoreWithScores(String key, double min, double max) { return stringRedisTemplate.opsForZSet().rangeByScoreWithScores(key, min, max); } /** * * @param key * @param min * @param max * @param start * @param end * @return */ public Set<TypedTuple<String>> zRangeByScoreWithScores(String key, double min, double max, long start, long end) { return stringRedisTemplate.opsForZSet().rangeByScoreWithScores(key, min, max, start, end); } /** * 获取集合的元素, 从大到小排序 * * @param key * @param start * @param end * @return */ public Set<String> zReverseRange(String key, long start, long end) { return stringRedisTemplate.opsForZSet().reverseRange(key, start, end); } public Set<String> zReverseRangeByScore(String key, long min, long max) { return stringRedisTemplate.opsForZSet().reverseRangeByScore(key, min, max); } /** * 获取集合的元素, 从大到小排序, 并返回score值 * * @param key * @param start * @param end * @return */ public Set<TypedTuple<String>> zReverseRangeWithScores(String key, long start, long end) { return stringRedisTemplate.opsForZSet().reverseRangeWithScores(key, start, end); } /** * 根据Score值查询集合元素, 从大到小排序 * * @param key * @param min * @param max * @return */ public Set<String> zReverseRangeByScore(String key, double min, double max) { return stringRedisTemplate.opsForZSet().reverseRangeByScore(key, min, max); } /** * 根据Score值查询集合元素, 从大到小排序 * * @param key * @param min * @param max * @return */ public Set<TypedTuple<String>> zReverseRangeByScoreWithScores( String key, double min, double max) { return stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, min, max); } /** * * @param key * @param min * @param max * @param start * @param end * @return */ public Set<String> zReverseRangeByScore(String key, double min, double max, long start, long end) { return stringRedisTemplate.opsForZSet().reverseRangeByScore(key, min, max, start, end); } /** * 根据score值获取集合元素数量 * * @param key * @param min * @param max * @return */ public Long zCount(String key, double min, double max) { return stringRedisTemplate.opsForZSet().count(key, min, max); } /** * 获取集合大小 * * @param key * @return */ public Long zSize(String key) { return stringRedisTemplate.opsForZSet().size(key); } /** * 获取集合大小 * * @param key * @return */ public Long zZCard(String key) { return stringRedisTemplate.opsForZSet().zCard(key); } /** * 获取集合中value元素的score值 * * @param key * @param value * @return */ public Double zScore(String key, Object value) { return stringRedisTemplate.opsForZSet().score(key, value); } /** * 移除指定索引位置的成员 * * @param key * @param start * @param end * @return */ public Long zRemoveRange(String key, long start, long end) { return stringRedisTemplate.opsForZSet().removeRange(key, start, end); } /** * 根据指定的score值的范围来移除成员 * * @param key * @param min * @param max * @return */ public Long zRemoveRangeByScore(String key, double min, double max) { return stringRedisTemplate.opsForZSet().removeRangeByScore(key, min, max); } /** * 获取key和otherKey的并集并存储在destKey中 * * @param key * @param otherKey * @param destKey * @return */ public Long zUnionAndStore(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForZSet().unionAndStore(key, otherKey, destKey); } /** * * @param key * @param otherKeys * @param destKey * @return */ public Long zUnionAndStore(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForZSet() .unionAndStore(key, otherKeys, destKey); } /** * 交集 * * @param key * @param otherKey * @param destKey * @return */ public Long zIntersectAndStore(String key, String otherKey, String destKey) { return stringRedisTemplate.opsForZSet().intersectAndStore(key, otherKey, destKey); } /** * 交集 * * @param key * @param otherKeys * @param destKey * @return */ public Long zIntersectAndStore(String key, Collection<String> otherKeys, String destKey) { return stringRedisTemplate.opsForZSet().intersectAndStore(key, otherKeys, destKey); } /** * * @param key * @param options * @return */ public Cursor<TypedTuple<String>> zScan(String key, ScanOptions options) { return stringRedisTemplate.opsForZSet().scan(key, options); } /** * 扫描主键,建议使用 * @param patten * @return */ public Set<String> scan(String patten){ Set<String> keys = stringRedisTemplate.execute((RedisCallback<Set<String>>) connection -> { Set<String> result = new HashSet<>(); try (Cursor<byte[]> cursor = connection.scan(new ScanOptions.ScanOptionsBuilder() .match(patten).count(10000).build())) { while (cursor.hasNext()) { result.add(new String(cursor.next())); } } catch (IOException e) { e.printStackTrace(); } return result; }); return keys; } /** * 管道技术,提高性能 * @param type * @param values * @return */ public List<Object> lRightPushPipeline(String type,Collection<String> values){ List<Object> results = stringRedisTemplate.executePipelined(new RedisCallback<Object>() { public Object doInRedis(RedisConnection connection) throws DataAccessException { StringRedisConnection stringRedisConn = (StringRedisConnection)connection; //集合转换数组 String[] strings = values.toArray(new String[values.size()]); //直接批量发送 stringRedisConn.rPush(type, strings); return null; } }); return results; } public List<Object> refreshWithPipeline(String future_key,String topic_key,Collection<String> values){ List<Object> objects = stringRedisTemplate.executePipelined(new RedisCallback<Object>() { @Nullable @Override public Object doInRedis(RedisConnection redisConnection) throws DataAccessException { StringRedisConnection stringRedisConnection = (StringRedisConnection)redisConnection; String[] strings = values.toArray(new String[values.size()]); stringRedisConnection.rPush(topic_key,strings); stringRedisConnection.zRem(future_key,strings); return null; } }); return objects; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
- 611
- 612
- 613
- 614
- 615
- 616
- 617
- 618
- 619
- 620
- 621
- 622
- 623
- 624
- 625
- 626
- 627
- 628
- 629
- 630
- 631
- 632
- 633
- 634
- 635
- 636
- 637
- 638
- 639
- 640
- 641
- 642
- 643
- 644
- 645
- 646
- 647
- 648
- 649
- 650
- 651
- 652
- 653
- 654
- 655
- 656
- 657
- 658
- 659
- 660
- 661
- 662
- 663
- 664
- 665
- 666
- 667
- 668
- 669
- 670
- 671
- 672
- 673
- 674
- 675
- 676
- 677
- 678
- 679
- 680
- 681
- 682
- 683
- 684
- 685
- 686
- 687
- 688
- 689
- 690
- 691
- 692
- 693
- 694
- 695
- 696
- 697
- 698
- 699
- 700
- 701
- 702
- 703
- 704
- 705
- 706
- 707
- 708
- 709
- 710
- 711
- 712
- 713
- 714
- 715
- 716
- 717
- 718
- 719
- 720
- 721
- 722
- 723
- 724
- 725
- 726
- 727
- 728
- 729
- 730
- 731
- 732
- 733
- 734
- 735
- 736
- 737
- 738
- 739
- 740
- 741
- 742
- 743
- 744
- 745
- 746
- 747
- 748
- 749
- 750
- 751
- 752
- 753
- 754
- 755
- 756
- 757
- 758
- 759
- 760
- 761
- 762
- 763
- 764
- 765
- 766
- 767
- 768
- 769
- 770
- 771
- 772
- 773
- 774
- 775
- 776
- 777
- 778
- 779
- 780
- 781
- 782
- 783
- 784
- 785
- 786
- 787
- 788
- 789
- 790
- 791
- 792
- 793
- 794
- 795
- 796
- 797
- 798
- 799
- 800
- 801
- 802
- 803
- 804
- 805
- 806
- 807
- 808
- 809
- 810
- 811
- 812
- 813
- 814
- 815
- 816
- 817
- 818
- 819
- 820
- 821
- 822
- 823
- 824
- 825
- 826
- 827
- 828
- 829
- 830
- 831
- 832
- 833
- 834
- 835
- 836
- 837
- 838
- 839
- 840
- 841
- 842
- 843
- 844
- 845
- 846
- 847
- 848
- 849
- 850
- 851
- 852
- 853
- 854
- 855
- 856
- 857
- 858
- 859
- 860
- 861
- 862
- 863
- 864
- 865
- 866
- 867
- 868
- 869
- 870
- 871
- 872
- 873
- 874
- 875
- 876
- 877
- 878
- 879
- 880
- 881
- 882
- 883
- 884
- 885
- 886
- 887
- 888
- 889
- 890
- 891
- 892
- 893
- 894
- 895
- 896
- 897
- 898
- 899
- 900
- 901
- 902
- 903
- 904
- 905
- 906
- 907
- 908
- 909
- 910
- 911
- 912
- 913
- 914
- 915
- 916
- 917
- 918
- 919
- 920
- 921
- 922
- 923
- 924
- 925
- 926
- 927
- 928
- 929
- 930
- 931
- 932
- 933
- 934
- 935
- 936
- 937
- 938
- 939
- 940
- 941
- 942
- 943
- 944
- 945
- 946
- 947
- 948
- 949
- 950
- 951
- 952
- 953
- 954
- 955
- 956
- 957
- 958
- 959
- 960
- 961
- 962
- 963
- 964
- 965
- 966
- 967
- 968
- 969
- 970
- 971
- 972
- 973
- 974
- 975
- 976
- 977
- 978
- 979
- 980
- 981
- 982
- 983
- 984
- 985
- 986
- 987
- 988
- 989
- 990
- 991
- 992
- 993
- 994
- 995
- 996
- 997
- 998
- 999
- 1000
- 1001
- 1002
- 1003
- 1004
- 1005
- 1006
- 1007
- 1008
- 1009
- 1010
- 1011
- 1012
- 1013
- 1014
- 1015
- 1016
- 1017
- 1018
- 1019
- 1020
- 1021
- 1022
- 1023
- 1024
- 1025
- 1026
- 1027
- 1028
- 1029
- 1030
- 1031
- 1032
- 1033
- 1034
- 1035
- 1036
- 1037
- 1038
- 1039
- 1040
- 1041
- 1042
- 1043
- 1044
- 1045
- 1046
- 1047
- 1048
- 1049
- 1050
- 1051
- 1052
- 1053
- 1054
- 1055
- 1056
- 1057
- 1058
- 1059
- 1060
- 1061
- 1062
- 1063
- 1064
- 1065
- 1066
- 1067
- 1068
- 1069
- 1070
- 1071
- 1072
- 1073
- 1074
- 1075
- 1076
- 1077
- 1078
- 1079
- 1080
- 1081
- 1082
- 1083
- 1084
- 1085
- 1086
- 1087
- 1088
- 1089
- 1090
- 1091
- 1092
- 1093
- 1094
- 1095
- 1096
- 1097
- 1098
- 1099
- 1100
- 1101
- 1102
- 1103
- 1104
- 1105
- 1106
- 1107
- 1108
- 1109
- 1110
- 1111
- 1112
- 1113
- 1114
- 1115
- 1116
- 1117
- 1118
- 1119
- 1120
- 1121
- 1122
- 1123
- 1124
- 1125
- 1126
- 1127
- 1128
- 1129
- 1130
- 1131
- 1132
- 1133
- 1134
- 1135
- 1136
- 1137
- 1138
- 1139
- 1140
- 1141
- 1142
- 1143
- 1144
- 1145
- 1146
- 1147
- 1148
- 1149
- 1150
- 1151
- 1152
- 1153
- 1154
- 1155
- 1156
- 1157
- 1158
- 1159
- 1160
- 1161
- 1162
- 1163
- 1164
- 1165
- 1166
- 1167
- 1168
- 1169
- 1170
- 1171
- 1172
- 1173
- 1174
- 1175
- 1176
- 1177
- 1178
- 1179
- 1180
- 1181
- 1182
- 1183
- 1184
- 1185
- 1186
- 1187
- 1188
- 1189
- 1190
- 1191
- 1192
- 1193
- 1194
- 1195
- 1196
- 1197
- 1198
- 1199
- 1200
- 1201
- 1202
- 1203
- 1204
- 1205
- 1206
- 1207
- 1208
- 1209
- 1210
- 1211
- 1212
- 1213
- 1214
- 1215
- 1216
- 1217
- 1218
- 1219
- 1220
- 1221
- 1222
- 1223
- 1224
- 1225
- 1226
- 1227
- 1228
- 1229
- 1230
- 1231
- 1232
- 1233
- 1234
- 1235
- 1236
- 1237
- 1238
- 1239
- 1240
- 1241
- 1242
- 1243
- 1244
- 1245
- 1246
- 1247
- 1248
- 1249
- 1250
- 1251
- 1252
- 1253
- 1254
- 1255
- 1256
- 1257
- 1258
- 1259
- 1260
- 1261
- 1262
- 1263
- 1264
- 1265
- 1266
- 1267
- 1268
- 1269
- 1270
- 1271
- 1272
- 1273
- 1274
- 1275
- 1276
- 1277
- 1278
- 1279
- 1280
- 1281
- 1282
- 1283
- 1284
- 1285
- 1286
- 1287
- 1288
- 1289
- 1290
- 1291
- 1292
- 1293
- 1294
- 1295
- 1296
- 1297
- 1298
- 1299
- 1300
- 1301
- 1302
- 1303
- 1304
- 1305
- 1306
- 1307
- 1308
- 1309
- 1310
- 1311
- 1312
- 1313
- 1314
- 1315
- 1316
- 1317
- 1318
- 1319
- 1320
- 1321
- 1322
- 1323
- 1324
- 1325
- 1326
- 1327
- 1328
- 1329
- 1330
- 1331
- 1332
- 1333
- 1334
- 1335
- 1336
- 1337
- 1338
- 1339
- 1340
- 1341
- 1342
- 1343
- 1344
- 1345
- 1346
- 1347
- 1348
- 1349
- 1350
- 1351
- 1352
- 1353
- 1354
- 1355
- 1356
- 1357
- 1358
- 1359
- 1360
- 1361
- 1362
- 1363
- 1364
- 1365
- 1366
- 1367
- 1368
- 1369
- 1370
- 1371
- 1372
- 1373
- 1374
- 1375
- 1376
- 1377
- 1378
- 1379
- 1380
- 1381
- 1382
- 1383
- 1384
- 1385
- 1386
- 1387
- 1388
- 1389
- 1390
- 1391
- 1392
- 1393
- 1394
- 1395
- 1396
- 1397
- 1398
- 1399
- 1400
- 1401
- 1402
- 1403
- 1404
- 1405
- 1406
- 1407
- 1408
- 1409
- 1410
- 1411
- 1412
- 1413
- 1414
- 1415
- 1416
- 1417
- 1418
- 1419
- 1420
- 1421
- 1422
- 1423
- 1424
- 1425
- 1426
- 1427
- 1428
- 1429
- 1430
- 1431
- 1432
- 1433
- 1434
- 1435
- 1436
- 1437
- 1438
- 1439
- 1440
- 1441
-
相关阅读:
2022云和恩墨大讲堂·苏州站成功举办,论道数智化时代下国产数据库的技术创新与实践
【设计模式实践笔记】第三节:建造者模式
软件建模与分析
最大流与最小费用最大流简略版)
【紧急情况】:回宿舍放下书包的我,花了20分钟敲了一个抢购脚本
docker对网络和程序速度的影响
C++ Reference: Standard C++ Library reference: C Library: cstring: strncat
Java下打印1-100以内的质数
GNU gold链接器初学(1)
MQ消息队列产品对比
- 原文地址:https://blog.csdn.net/qq_55272229/article/details/133860224
