# 得到每一行的数据 []
datas =open('data/word.txt','r', encoding='gbk').read().split("\n")# 得到一行的单个字 [[],...,[]]
word_datas =[[i for i in data if i !=" "]for data in datas]
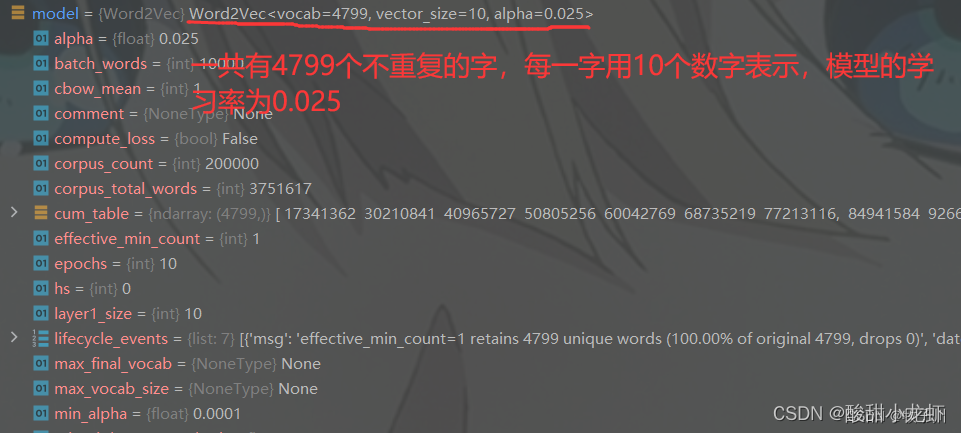
model = Word2Vec(
word_datas,# 需要训练的文本
vector_size=10,# 词向量的维度
window=2,# 句子中当前单词和预测单词之间的最大距离
min_count=1,# 忽略总频率低于此的所有单词 出现的频率小于 min_count 不用作词向量
workers=8,# 使用这些工作线程来训练模型(使用多核机器进行更快的训练)
sg=0,# 训练方法 1:skip-gram 0;CBOW。
epochs=10# 语料库上的迭代次数)