-
36 机器学习(四):异常值检测|线性回归|逻辑回归|聚类算法|集成学习
异常值检测
这边就讲解其中一种方法,详细可见别人的博客:
箱线图
如果一个值大于3/4分位值+1.5 IQR 他就是异常值 如果一个值小于1/4分位值-1.5 IQR 他就是异常值- 1
- 2
z-score
标准化后的值大于某一个阈值 也可以当作异常值处理
保存模型 与 使用模型
# 保存模型 joblib.dump(对应的训练器, "./tmp/test.pkl") # 使用模型 此时model就是对应的训练器 model = joblib.load("./tmp/test.pkl")- 1
- 2
- 3
- 4
- 5
回归的性能评估
这边只给出一种,注意和之前的分类的混淆矩阵的那些相对比:

接口:
sklearn.metrics.mean_squared_error mean_squared_error(y_true,y_pred).均方误差回归损失 y_true:真实值 y_pred:预测值 return:浮点数结果- 1
- 2
- 3
- 4
- 5
- 6
- 7
线性回归
正规方程的线性回归
# 正则化的 线性回归预测房子的价格 from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression import joblib from sklearn.metrics import mean_squared_error # 基本的操作(数据准备) 之前都见多了 不过值得关注的是这边多采用了对于y也进行标准化,定义了两个标准器 # ---------------------------------------------------------------------- lb = load_boston() x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25, random_state=1) print(x_train.shape) std_x = StandardScaler() x_train = std_x.fit_transform(x_train) x_test = std_x.transform(x_test) # 对y的标准化 std_y = StandardScaler() y_train = std_y.fit_transform(y_train.reshape(-1, 1)) # 目标值是一维的,这里需要传进去2维的 y_test = std_y.transform(y_test.reshape(-1, 1)) print('-'*20) # ---------------------------------------------------------------------- # estimator预测 # 正规方程求解方式预测结果,正规方程进行线性回归 lr = LinearRegression() lr.fit(x_train, y_train) # 训练结束 打印出对应的w print(lr.coef_) #回归系数可以看特征与目标之间的相关性 y_predict = lr.predict(x_test) # 预测测试集的房子价格,通过inverse得到真正的房子价格 y_lr_predict = std_y.inverse_transform(y_predict) # 保存训练好的模型 joblib.dump(lr, "./tmp/test.pkl") # 模型加载 model = joblib.load("./tmp/test.pkl") print("正规方程测试集里面每个房子的预测价格:", y_lr_predict) print("正规方程的均方误差:", mean_squared_error(y_test, y_predict))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
输出:
# # 输出:这个数据集不知道为什么用不了了 # (379, 13) # -------------------- # [[-0.12026411 0.15044778 0.02951803 0.07470354 -0.28043353 0.22170939 # 0.02190624 -0.35275513 0.29939558 -0.2028089 -0.23911894 0.06305081 # -0.45259462]] # 正规方程测试集里面每个房子的预测价格: # [[32.37816533] # ````````````` # [26.00459084]] # 正规方程的均方误差: 0.2758842244225054- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
梯度下降的线性回归
# 梯度下降去进行房价预测,数据量大要用这个 # 默认可以去调 eta0 = 0.008,会改变learning_rate # learning_rate='optimal',alpha会影响学习率的值,由alpha来算学习率 from sklearn.linear_model import SGDRegressor sgd = SGDRegressor(eta0=0.008, penalty='l1', alpha=0.005) # # 训练 sgd.fit(x_train, y_train) # print('梯度下降的回归系数', sgd.coef_) # # 预测测试集的房子价格 y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test).reshape(-1, 1)) y_predict = sgd.predict(x_test) print("梯度下降测试集里面每个房子的预测价格:", y_sgd_predict) print("梯度下降的均方误差:", mean_squared_error(y_test, y_predict)) print("梯度下降的原始房价量纲均方误差:", mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出:
梯度下降的回归系数 [-0.09161381 0.07894594 -0.01997965 0.07736127 -0.18054122 0.26622108 0. -0.23891603 0.09441201 -0.02523685 -0.22153748 0.06690733 -0.4268276 ] 梯度下降测试集里面每个房子的预测价格: [[30.32788625] ·············· [25.98775391]] 梯度下降的均方误差: 0.2782778128254135 梯度下降的原始房价量纲均方误差: 22.087751747792876- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
原理介绍
这边由于线性回归比较简单,介绍就比较简略。
我们实际上的训练就是为了训练出:下面这个w向量,然后最后得到合适的w,可以用来预测好的数据。
判断误差使用损失函数进行判断:
其中一种:最小二乘法

而如何去反向更新w,这就是机器学习与深度学习的一大重大的特征:
而上面给出的两个接口,则是分别采用两种不同的方式去进行的更新w
方式一:正规方程(LinearRegression)

但这个也有问题,就是有些就没有这个矩阵的逆,这就有很大的局限,甚至这个方程求解的速度也不快。方式二:梯度下降(SGD)
还有很多梯度

L1 和 L2 正则化的介绍
当我们训练机器学习模型时,我们希望它能够在新数据上表现良好。但是,如果我们使用过于复杂的模型,例如具有大量特征或参数的模型,就会出现过拟合的问题。 过拟合是指模型在训练数据上表现良好,但在新数据上表现不佳的情况。为了避免过拟合,我们可以使用正则化技术。
正则化是一种用于控制模型复杂度的技术,通常应用于线性回归、逻辑回归和神经网络等机器学习模型中。 正则化通过向模型的损失函数中添加一个惩罚项来防止模型过拟合。 这个惩罚项会惩罚模型的权重参数,使其趋向于较小的值。 正则化分为L1正则化(Lasso正则化)和L2正则化(Ridge正则化),它们分别对应不同的惩罚项类型。
L1正则化(Lasso正则化)通过向损失函数中添加权重向量中各个元素的绝对值之和来惩罚权重参数。 L1正则化可以产生稀疏权重向量,即其中许多元素为零。 这使得L1正则化成为特征选择的一种方法。
L2正则化(Ridge正则化)通过向损失函数中添加权重向量中各个元素的平方和来惩罚权重参数。 L2正则化可以防止过拟合并提高模型的泛化能力

api介绍------LinearRegression
# 通过正规方程优化 sklearn.linear_model.LinearRegression(fit_intercept=True) 参数: fit_intercept:是否计算偏置 属性: LinearRegression.coef_:回归系数 LinearRegression.intercept_:偏置- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
api介绍------SGDRegressor
# SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。 sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01) 参数: loss:损失类型 loss=”squared_loss”: 普通最小二乘法 ‘squared_error’ ‘huber’ ‘epsilon_insensitive’ ‘squared_epsilon_insensitive’ fit_intercept:是否计算偏置 learning_rate : 'constant': eta = eta0 'optimal': eta = 1.0 / (alpha * (t + t0)) [default] 'invscaling': eta = eta0 / pow(t, power_t) eta0: default=0.01 eta0float,默认值=0.01 power_t=0.25:存在父类当中 对于一个常数值的学习率来说,可以使用learning_rate=’constant’ ,并使用eta0来指定学习率。 early_stopping:损失没有改进,提前停止训练 penalty是惩罚,分为L1和L2 alpha:值越高,正则化力度越强 补充 这个不是参数:t 和 执行的次数正相关 属性: SGDRegressor.coef_:回归系数 SGDRegressor.intercept_:偏置- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
岭回归 和 Lasso 回归
实际上就是上面加上正则化的回归,岭就是加上L2的线性回归,Lasso就是加上L1的线性回归。
这边给出接口:
sklearn.linear_model.Ridge sklearn.linear_model.Lasso- 1
- 2
- 3
具体的接口参数到官网上查找
逻辑回归
逻辑回归是一个很重要的模型,虽然叫做回归,但是实际上确是一个二分类器,关于逻辑回归的理解,关系到后面对于深度学习的理解,所以这一块需要重点关注。
基本使用
# 逻辑回归做二分类进行癌症预测(根据细胞的属性特征) from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report,roc_auc_score from sklearn.preprocessing import StandardScaler # 数据准备 # 构造列标签名字 column = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape','Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin', 'Normal Nucleoli','Mitoses', 'Class'] # 读取数据 预测是否患病 data = pd.read_csv("./dataset/breast-cancer-wisconsin.data.txt",names=column) # 缺失值进行处理 data = data.replace(to_replace='?', value=np.nan) #直接删除,哪一行有空值,就删除对应的样本 data = data.dropna() print(data.info()) print('-'*20) # 进行数据的分割 x_train, x_test, y_train, y_test = train_test_split(data[column[1:10]], data[column[10]], test_size=0.25,random_state=1) # 进行标准化处理 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) # 逻辑回归预测 C正则化力度 solver 默认是 'liblinear' lg = LogisticRegression(C=0.8, solver='newton-cg') lg.fit(x_train, y_train) y_predict = lg.predict(x_test) # 正确率判断 print("准确率:\n", lg.score(x_test, y_test)) # 得出对应分类的概率 会得到两个数 前者是不患病的概率 后者是患病的概率 print("概率是:\n",lg.predict_proba(x_test)[0]) # 为什么还要看下召回率,labels和target_names对应 # macro avg 平均值 weighted avg 加权平均值 print("召回率:\n", classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"])) #AUC计算要求是二分类,不需要是0和1 print("AUC指标:\n", roc_auc_score(y_test, y_predict))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
输出:
<class 'pandas.core.frame.DataFrame'> Index: 683 entries, 0 to 698 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Sample code number 683 non-null int64 1 Clump Thickness 683 non-null int64 2 Uniformity of Cell Size 683 non-null int64 3 Uniformity of Cell Shape 683 non-null int64 4 Marginal Adhesion 683 non-null int64 5 Single Epithelial Cell Size 683 non-null int64 6 Bare Nuclei 683 non-null object 7 Bland Chromatin 683 non-null int64 8 Normal Nucleoli 683 non-null int64 9 Mitoses 683 non-null int64 10 Class 683 non-null int64 dtypes: int64(10), object(1) memory usage: 64.0+ KB None -------------------- 准确率: 0.9824561403508771 概率是: [0.95194977 0.04805023] 召回率: precision recall f1-score support 良性 0.97 1.00 0.99 111 恶性 1.00 0.95 0.97 60 accuracy 0.98 171 macro avg 0.99 0.97 0.98 171 weighted avg 0.98 0.98 0.98 171 AUC指标: 0.975- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
原理介绍
正向原理介绍
输入:
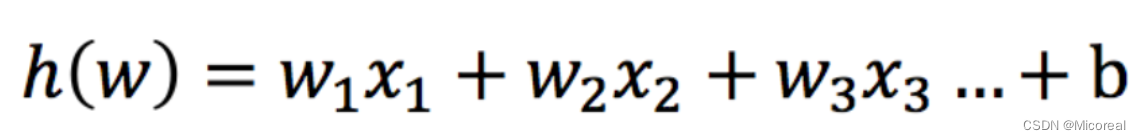
逻辑回归的输入就是一个线性回归,他把这个值作为输入。然后得到的值我们称为z,再输入到激活函数当中:
这边举一个最广为人知的激活函数sigmoid:

这个不是很好看懂,实际上就是g(z) = 1/(1+exp(-z))然后我们的值就会经过这个激活函数,把这些值映射到【0,1】之间,而且也是正好映射-∞映射到0,0映射到0.5,+∞映射到1,这样子,然后我们再对于我们映射到的值判断属于0-0.5 输出的就是0,0.5-1输出的就是1 从而进行分类。
例子:

但有了这个正向的原理,那我们该怎么反向去更新那些参数w呢?损失函数 与 反向更新
当然数学家也使用这个交叉熵给出了答案

结合完整的:

计算的例子:

知道了损失函数,那我们就该去反向更新w(想要使用梯度下降进行更新),自然想到的就是链式求导法则:

这边给出别人的计算哈,!OxO !如此,我们知道了梯度,也就可以按照对应的梯度下降算法进行优化w。
接口介绍
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0) solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},(优化器,或者就是说就是那个学习率,不过是随着时间的变化而变化的)默认: 'liblinear';用于优化问题的算法。对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。对于多类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。 penalty:正则化的种类 C:正则化力度- 1
- 2
- 3
- 4
- 5
- 6
- 7
聚类算法初识
这边主要介绍的就是k-means算法,也是无监督算法的典型。
k-means
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程api接口:
sklearn.cluster.KMeans(n_clusters=8) 参数: n_clusters:开始的聚类中心数量 整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。 方法: estimator.fit(x) estimator.predict(x) estimator.fit_predict(x) 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
模型的评估
计算样本i到同簇其他样本的平均距离ai,ai 越小样本i的簇内不相似度越小,说明样本i越应该被聚类到该簇。计算样本i到最近簇Cj 的所有样本的平均距离bij,称样本i与最近簇Cj 的不相似度,定义为样本i的簇间不相似度:bi =min{bi1, bi2, …, bik},bi越大,说明样本i越不属于其他簇。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。
平均轮廓系数的取值范围为[-1,1],系数越大,聚类效果越好。
簇内样本的距离越近,簇间样本距离越远
代码
import pandas as pd from sklearn.decomposition import PCA from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score # 1.获取数据 order_product = pd.read_csv("./data/instacart/order_products__prior.csv") products = pd.read_csv("./data/instacart/products.csv") orders = pd.read_csv("./data/instacart/orders.csv") aisles = pd.read_csv("./data/instacart/aisles.csv") # 2.数据基本处理 table1 = pd.merge(order_product, products, on=["product_id", "product_id"]) table2 = pd.merge(table1, orders, on=["order_id", "order_id"]) table = pd.merge(table2, aisles, on=["aisle_id", "aisle_id"]) table = pd.crosstab(table["user_id"], table["aisle"]) table = table[:1000] # 3.特征工程 — pca transfer = PCA(n_components=0.9) data = transfer.fit_transform(table) # 4.机器学习(k-means) estimator = KMeans(n_clusters=8, random_state=22) estimator.fit_predict(data) # 5.模型评估 silhouette_score(data, y_predict)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
集成学习
集成学习一般分为两种:
- Boosting(串行):它的基本思路是将基分类器层层叠加,每一层在训练的时候,对前一层基分类器分错的样本,给予更高的权重。
- Bagging(并行):Bagging 方法更像是一个集体决策的过程,每个个体都进行单独学习,学习的内容可以相同,也可以不同,也可以部分重叠。但由于个体之间存在差异性,最终做出的判断不会完全一致。在最终做决策时,每个个体单独作出判断,再通过投票的方式做出最后的集体决策。
集成学习一般可分为以下 3 个步骤。
(1)找到误差互相独立的基分类器。
(2)训练基分类器。
(3)合并基分类器的结果。
合并基分类器的方法有 voting 和 stacking 两种。前者是用投票的方式,将获得
最多选票的结果作为最终的结果。后者是用串行的方式,把前一个基分类器的结果输出到下一个分类器,将所有基分类器的输出结果相加(或者用更复杂的算法融合,比如把各基分类器的输出作为特征,使用逻辑回归作为融合模型进行最后的结果预测)作为最终的输出。偏差和方差
讲解讲不清楚,这边直接给出一个图例:

Bagging 能够提高弱分类器性能的原因是降低了方差,Boosting 能够提升弱分类器性能的原因是降低了偏差。Adaboost(原理略写)------Boosting
Adaboost的基本实现步骤如下:
- 初始化训练数据的权重向量,使每个样本的权重相等。
- 训练一个弱分类器,并计算其在训练数据上的错误率。
- 根据分类器的错误率更新训练数据的权重向量,使被错误分类的样本的权重增加,而被正确分类的样本的权重减少。
- 重复步骤2和3,直到达到指定数量的弱分类器或直到训练数据完全正确分类。
- 将所有弱分类器组合成一个强分类器。
在实现Adaboost时,我们需要选择一个基础分类器作为弱分类器。 常用的基础分类器包括决策树、神经网络和支持向量机等。
GBDT (原理略写)------Boosting
Gradient Boosting(梯度提升) 是 Boosting 中的一大类算法,其基本思想是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有模型中。算法 1 描述了 Gradient Boosting 算法的基本流程,在每一轮迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练一个新的弱分类器进行拟合并计算出该弱分类器的权重,最终实现对模型的更新。
比如一开始GBDT(x,y) 下一步: GBDT(x,y真实-y)
区分梯度提升和梯度下降

自己做一个hard bagging
import numpy as np import pandas as pd import matplotlib.pyplot as plt # 准备数据 from sklearn import datasets x, y = datasets.make_moons(n_samples=1000, noise=0.3, random_state=42) plt.scatter(x[y == 0, 0], x[y == 0, 1]) plt.scatter(x[y == 1, 0], x[y == 1, 1]) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:

#默认分割比例是75%和25% from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42) log_clf = LogisticRegression() log_clf.fit(x_train, y_train) log_clf.score(x_test, y_test) svm_clf = SVC() svm_clf.fit(x_train, y_train) svm_clf.score(x_test, y_test) dt_clf = DecisionTreeClassifier() dt_clf.fit(x_train, y_train) dt_clf.score(x_test, y_test) #训练好模型,测试集做预测 y_predict1 = log_clf.predict(x_test) y_predict2 = svm_clf.predict(x_test) y_predict3 = dt_clf.predict(x_test)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
from sklearn.metrics import accuracy_score # 自己做一个bagging并行 hard bagging y_predict = np.array((y_predict1 + y_predict2 + y_predict3) >= 2, dtype='int') #accuracy_score计算准确率的 print(accuracy_score(y_test, y_predict))- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
0.908- 1
我们直接进行相加,其实有一个问题,就比如说我们上面不是定义了三个基分类器,三个训练出来的模型,得出的效果有高有低,而我们给予其相同的权重进行累加,这明显是不对的,我们需要进行修改成soft bagging,加上他们每个人对应的猜对的概率。
调用接口写的hard bagging
from sklearn.ensemble import VotingClassifier #hard模式就是少数服从多数 voting_clf = VotingClassifier(estimators=[ ('log_clf', LogisticRegression()), ('svm_clf', SVC()), ('dt_clf', DecisionTreeClassifier())], voting='hard') voting_clf.fit(x_train, y_train) print(voting_clf.score(x_test, y_test))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出:
0.908- 1
soft bagging
当然也可以自己写一个,但这里避免麻烦就直接调用接口了
# hard和soft区别请看课件解释 voting_clf2 = VotingClassifier(estimators=[ ('log_clf', LogisticRegression()), ('svm_clf', SVC(probability=True)), #支持向量机中需要加入probability ('dt_clf', DecisionTreeClassifier())], voting='soft') voting_clf2.fit(x_train, y_train) print(voting_clf2.score(x_test, y_test))- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
0.916- 1
BaggingClassifier的api接口介绍
from sklearn.tree import DecisionTreeClassifier #用决策树集成上千模型 from sklearn.ensemble import BaggingClassifier # 这个可以搭配别的模型进行使用 # n_estimators指定了随机森林中决策树的数量 max_samples指定了每个决策树使用的样本数 # bootstrap指定了是否使用有放回抽样来生成每个决策树的训练数据 这个一般都是有放回 除非数据量很大 # oob_score=True 拿没有取到的数据集作为测试集 概率上统计有37%的数据是随机不到的 # n_jobs 使用多少个cpu核心在跑 如果是-1的话就是使用所有的核心跑 # max_features指定了在寻找最佳分割时要考虑的特征数量 # bootstrap_features指定了是否在寻找最佳分割时对特征进行有放回抽样 bagging_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=10, max_samples=100, bootstrap=True,oob_score=True,n_jobs=1) bagging_clf.fit(x_train, y_train) print(bagging_clf.score(x_test, y_test))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出:
0.912- 1
RandomForestClassifier的api接口介绍
这个直接就是定义了是用决策树进行拼接,自行去sklearn上查找也可,这边就提一嘴是bagging的算法
rc_clf2 = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, random_state=666, oob_score=True, n_jobs=-1) rc_clf2.fit(x, y) rc_clf2.oob_score_- 1
- 2
- 3
- 4
- 5
输出:
0.92- 1
ExtraTreesClassifie
ExtraTreesClassifier是一种基于决策树的集成学习算法,它通过随机化特征选择和样本选择来构建多个决策树,并将它们的预测结果进行平均来得到最终的预测结果。与传统决策树不同的是,ExtraTreesClassifier在选择划分属性时不再从所有属性中选择最优属性,而是从一个随机子集中选择最优属性。这样可以增加基学习器之间的差异性,提高模型的泛化能力ExtraTreesClassifier可以用于二元分类和多类别分类问题,并且在实践中表现良好。如果您需要使用决策树作为基学习器,则可以考虑使用ExtraTreesClassifier。
提高泛化能力,避免过拟合现象。
from sklearn.ensemble import ExtraTreesClassifier et_clf = ExtraTreesClassifier(n_estimators=500, oob_score=True, bootstrap=True, n_jobs=-1) et_clf.fit(x, y) et_clf.oob_score_- 1
- 2
- 3
- 4
- 5
- 6
bossting
from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier- 1
- 2
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(), n_estimators=500) ada_clf.fit(x_train, y_train) ada_clf.score(x_test, y_test)- 1
- 2
- 3
输出:
0.892- 1
from sklearn.ensemble import GradientBoostingClassifier gb_clf = GradientBoostingClassifier(max_depth=2, n_estimators=30) gb_clf.fit(x_train, y_train) gb_clf.score(x_test, y_test)- 1
- 2
- 3
- 4
- 5
输出:
0.9- 1
-
相关阅读:
Oracle Primavera Unifier 23.6 新特征
Day23-JDBC
超详细Redis入门教程二
赫尔辛基交通安全改善项目部署Velodyne Lidar智能基础设施解决方案
mobileperf安装及使用
【软件工程之美 - 专栏笔记】34 | 账号密码泄露成灾,应该怎样预防?
使用REDIS的INCREMENT方法生成自增主键,并发量每秒一万
Apache Spark 的基本概念和在大数据分析中的应用
WebSocket封装(TypeScript、单例模式、自动重连、事件监听、Vue中使用)
04 运算符
- 原文地址:https://blog.csdn.net/Micoreal/article/details/133925790
