-
C++入门 第二篇( 引用、内联函数、auto关键字、指针空值nullptr)
目录
本篇为继承上一篇基础之上进行讲解:# C++入门 第一篇(C++关键字, 命名空间,C++输入&输出)
6. 引用
6.1 引用概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间,它和它引用的变量共用同一块内存空间。
就像是给他人取外号,虽然称呼不同,但是所代表的都是同一个人类型& 引用变量名(对象名) = 引用实体;
- void TestRef()
- {
- int a = 10;
- int& ra = a;//<====定义引用类型
- printf("%p\n", &a);
- printf("%p\n", &ra);
- }
6.2 引用特性
1. 引用在定义时必须初始化
2. 一个变量可以有多个引用
3. 引用一旦引用一个实体,再不能引用其他实(不能像指针那样改变指向)
因为为同一个地址故当其中一个发生改变时,另一个会跟着一起改变
6.3 常引用
- void TestConstRef()
- {
- const int a = 10;
- //int& ra = a; // 该语句编译时会出错,a为常量
- const int& ra = a;
- // int& b = 10; // 该语句编译时会出错,b为常量
- const int& b = 10;
- double d = 12.34;
- //int& rd = d; // 该语句编译时会出错,类型不同
- const int& rd = d;
- }
具体讲解:

为什么次数d=c时报错了呢?
当然此处与指针的特点相似 指针和引用,进行 赋值/初始化 权限可以缩小,但不能放大
const int c=2; c时只能读的
而 int& d=c; 此时d 不仅变成了可以读而且还可以写,扩大了权限,故发生了报错同样的例子:权限放大

正确用法:权限 缩小/平移

const int& ret=Count();拓展:

当定义 int i=1; 时,i 是一个整型变量。
接下来,double &rd = i; 语句将一个 double 类型的引用 rd 绑定到了 i 上。引用 rd 和变量 i 现在指向同一个内存地址,它们是同一个变量的不同名称。由于 rd 是 i 的引用,可以通过 rd 修改 i 的值,并且对 rd 的修改也会对 i 产生影响。
也可以理解为:i作为变量,而rd为与i同一地址为i的另名,而作为引用i,不可以对rd进行更改,故应该前面➕const 改为常变量6.4 使用场景
1. 做参数
- //可以简化对指针的引用
- void Swap(int& left, int& right)
- {
- int temp = left;
- left = right;
- right = temp;
- }
- int main()
- {
- int a=0,int b=1;
- swap(a,b);
- return 0;
- }
2. 做返回值
- //传引用
- int& Count()
- {
- static int n = 0;
- n++;
- // ...
- return n;
- }
我们曾经使用的都是传值法:
例如:- Swap(int x,int y)
- {
- return x+y;
- }
3.传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
当我们深入了解栈帧就会知道 return x+y;函数销毁时该return值存放在栈帧的寄存器上

引用:
return时,并不像传值返回,此处返回可以认为是产生了一个n的别名,可以减少拷贝,节约空间
引用返回的优点体现:- #include
- #define N 10
- typedef struct Array
- {
- int a[N];
- int size;
- }AY;
- //引用返回
- //1,减少拷贝
- //2,调用者可以修改返回对象
- int& PosAt(AY& ay ,int i)
- {
- assert(ireturn ay.a[i];//此处返回的就是a的第i个位置的别名}int main(){int ret=Count();AY ay;for (int i = 0; i < N; i++){PosAt(ay,i)=i*10;}for (int i = 0; i < N; i++){cout<<PosAt(ay,i)<<" ";}cout<return 0;}
6.5引用问题举例
举例:
- int& Add(int a, int b)
- {
- int c = a + b;
- return c;
- }
- int main()
- {
- int &ret = Add(1, 2);
- //Add(3, 4);
- cout << "Add(1,2) is :" << ret << endl;
- cout << "Add(1,2) is :" << ret << endl;
- return 0;
- }
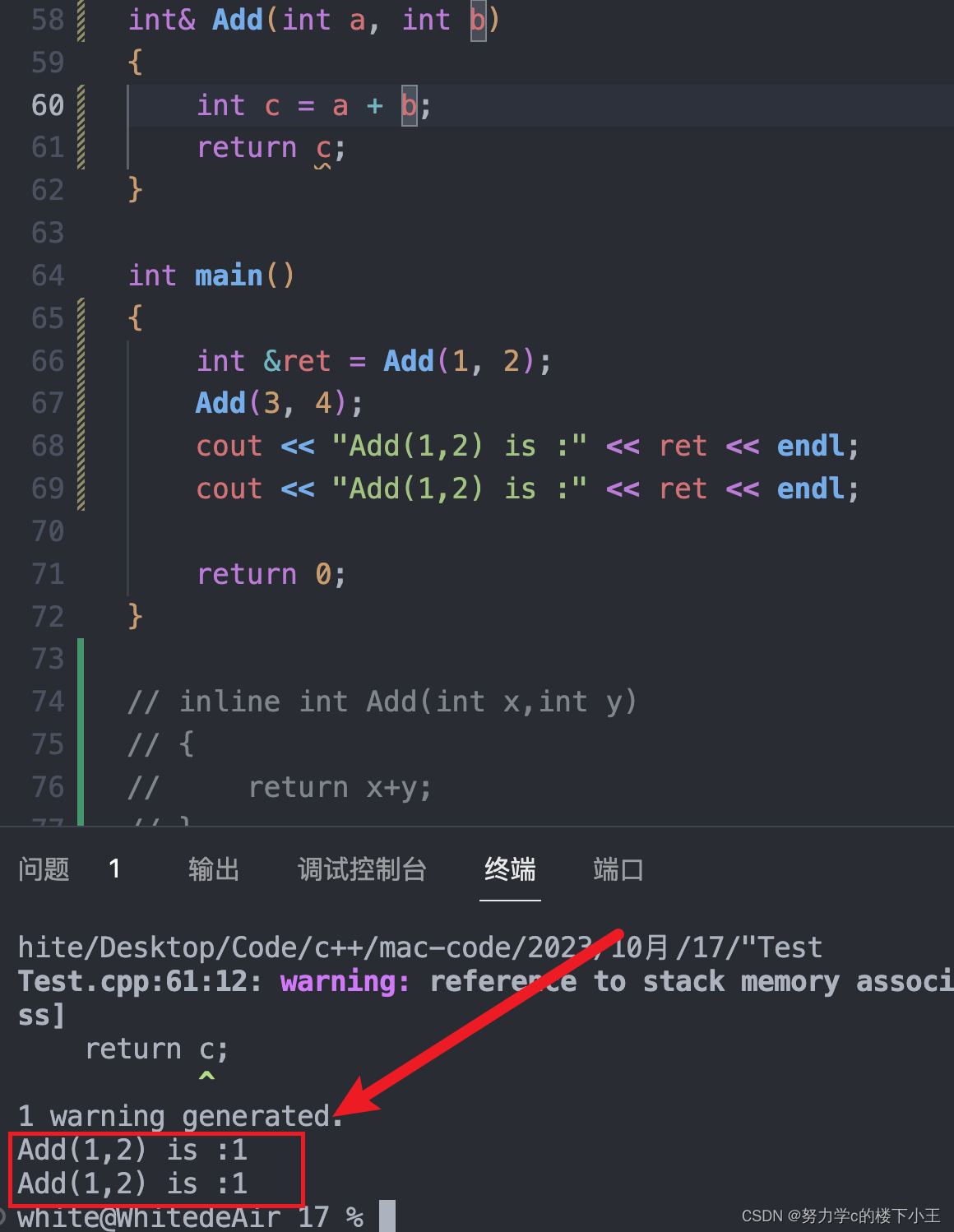
当然有些编译器输出的值可能是:
Add(1,2) is : 7
Add(1,2) is : ~(此处为随机值)不同的编译器可能在此处输出的值不同
但为什么会输出这样的值呢?在执行过程中:
int &ret = Add(1, 2);此时ret =n= 3
若此时将下一行的 Add(3, 4);注销,此时输出就可能为:

3(此处为随机值或3)
~(此处为随机值) ;
原因是访问时 该空间已经被销毁,不同的编译器输出结果可能>>不同,但此方法就是错误的这种方法,语法上是可以执行的,但是结果上是未定义的,本身就是错误的
在该代码基础之上对main函数进行更改怎么样都是错误的
6.6 反汇编中的&

在反汇编中可以看出:
->在表层上引用是不开空间的
-> 在底层上引用开辟空间(4字节),从汇编层面上引用也是用指针实现的6.7 引用和指针的不同点:
-
引用概念上定义一个变量的别名,指针存储一个变量地址。
-
引用在定义时必须初始化,指针没有要求
-
引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
-
没有NULL引用,但有NULL指针
-
在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32 位平台下占4个字节)
-
引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
-
有多级指针,但是没有多级引用
-
访问实体方式不同,指针需要显式解引用,引用编译器自己处理
-
引用比指针使用起来相对更安全
7.内联函数
7.1 内联函数与宏对比
以inline 修饰的函数叫内联函数
在C语言中使用定义宏:#define
定义宏相关文章:# C语言:程序环境和预处理
定义相关define 函数 在变异阶段阶段就会进行读写,使用时容易出现bug
若定义一个x+y的宏:#define Add(x,y) ((x)+(y))宏函数的错误写法:
- #define Add(int x, int y) return x + y;
- #define Add(x, y) x + y;
- #define Add(x, y) (x + y);
- #define Add(x, y) (x) + (y);
相比内联函数定义宏的缺点是:
宏定义函数相比内联函数的缺点包括可读性差、难以调试、没有类型安全的检查、占用更多内存、可能引发副作用、排查错误困难和缺乏类型检查等等。内联函数的优点:
9. 减少函数调用开销。
10. 减少函数体积,节省代码存储空间。
11. 提高指令缓存命中率。
12. 消除函数调用的运行时开销。7.2 内联函数
使用lnline内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率
- inline int Add(int x,int y)
- {
- return x+y;
- }
内敛是以空间(编译出来的可执行程序会变大非运行时占用内存变大)换时间的做法
假设1000个调用swap的地方:
swap不是inline:
swap+调用swap指令,合计是10+1000swap是inline:
swap+调用swap指令,合计是 1*10007.2内联函数的特性:
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会 用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运 行效率。
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建 议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不 是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址 了,链接就会找不到。
- // F.h
- #include
- using namespace std;
- inline void f(int i);
- // F.cpp
- #include "F.h"
- void f(int i)
- {
- cout << i << endl;
- }
- // main.cpp
- #include "F.h"
- int main()
- {
- f(10);
- return 0;
- }
- // 链接错误:main.obj : error LNK2019:
- //无法解析的外部符号 "void __cdecl f(int)"
- //(?f@@YAXH@Z),该符号在函数 _main 中被引用
8. auto关键字
auto 关键字是用来进行类型推断的。在 C++11 标准引入之前,我们需要显式地声明变量的类型,例如 int、double 等。而使用 auto 关键字,则可以根据变量的初始值自动推断出其类型。
auto 关键字的使用可以简化代码,提高代码的可读性和可维护性。特别是在定义复杂类型或迭代器类型时,使用 auto 可以避免重复编写类型名称,减少代码冗余。

【注意】
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto 的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编 译期会将auto替换为变量实际的类型
typedef相比于auto的缺点:- typedef char* pstring;
- int main()
- {
- const pstring p1;// 编译成功还是失败?
- const pstring* p2;// 编译成功还是失败?
- return 0;
- }
p1失败
正确写法:- const pstring p1=nullptr;
- const pstring* p2;
auto的使用细则
1. auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须 加&

遍历数组:- //曾今的方法:
- int array[] = {1, 2, 3, 4, 5, 6};
- for (int i = 0; i < sizeof(array) / sizeof(int); i++)
- {
- cout << array[i] << " ";
- }
- cout << endl;
- // 遍历数组新方式:
- // 范围for--语法糖 : 自动依次取数组中数据赋值给e对象,
- //自动判断结束
- for (auto e : array)
- {
- cout << e << " ";
- }
- cout << endl;
2. 在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
- void TestAuto()
- {
- auto a = 1, b = 2;
- auto c = 3, d = 4.0;
- // 该行代码会编译失败,因为c和d的初始化表达式类型不同
- }
3.auto不能推导的场景
- auto不能作为函数的参数
- // 此处代码编译失败,auto不能作为形参类型,
- //因为编译器无法对a的实际类型进行推导
- void TestAuto(auto a)
- {
- }
- auto不能直接用来声明数组
- void TestAuto()
- {
- int a[] = {1,2,3};
- auto b[] = {4,5,6};
- }
-
为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法
-
auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有 lambda表达式等进行配合使用。
9.指针空值nullptr

二者的区别是什么呢?
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何 种定义,在使用空值的指针时都不可避免的会遇到些麻烦- void f(int)
- {
- cout<<"f(int)"<}void f(int*){cout<<"f(int*)"<}int main(){f(0);f(NULL);f((int*)NULL);return 0;}
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的 初衷相悖。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器 默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0。注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入 的。
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
本篇就到此结束啦,感谢阅读,创作不易,若喜欢的话不妨留下一个免费的赞👍吧🥰🥰🥰🥰
-
相关阅读:
变量与运算符
vSphere 架构设计方案(上)
Roson的Qt之旅 #114 QML Repeater(重复器)
如何修改uni微信小程序editor组件和input组件的placeholder默认样式
力扣.82删除链表中的重复元素(java语言实现)
MySQL的排序和分页
SAP-SD26-设定销售收入科目
浅谈C/C++指针和引用在Linux和Windows不同环境下的编码风格
【-前端攻城师之JS基础】01JS基础语法
读书笔记之C Primer Plus 4
- 原文地址:https://blog.csdn.net/2301_77649794/article/details/133905429
